 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Person Re-identification: A Survey and Outlook
Jan 13, 2020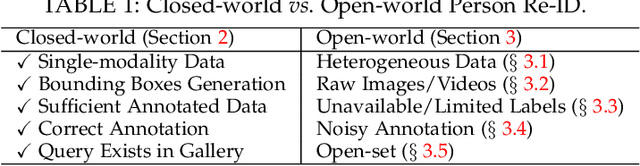

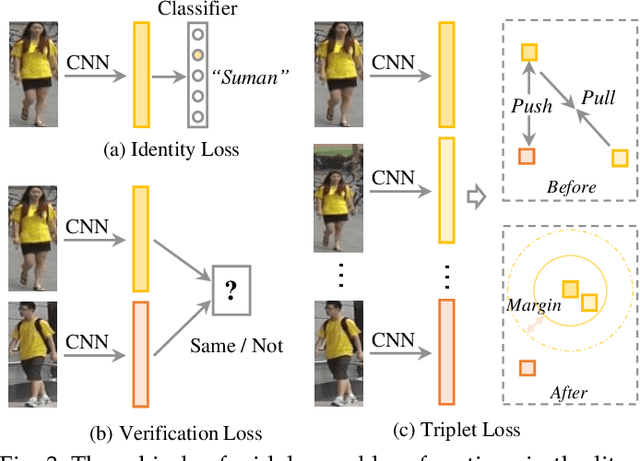
Person re-identification (Re-ID) aims at retrieving a person of interest across multiple non-overlapping cameras. With the advancement of deep neural networks and increasing demand of intelligent video surveillance, it has gained significantly increased interest in the computer vision community. By dissecting the involved components in developing a person Re-ID system, we categorize it into the closed-world and open-world settings. The widely studied closed-world setting is usually applied under various research-oriented assumptions, and has achieved inspiring success using deep learning techniques on a number of datasets. We first conduct a comprehensive overview with in-depth analysis for closed-world person Re-ID from three different perspectives, including deep feature representation learning, deep metric learning and ranking optimization. With the performance saturation under closed-world setting, the research focus for person Re-ID has recently shifted to the open-world setting, facing more challenging issues. This setting is closer to practical applications under specific scenarios. We summarize the open-world Re-ID in terms of five different aspects. By analyzing the advantages of existing methods, we design a powerful AGW baseline, achieving state-of-the-art or at least comparable performance on both single- and cross-modality Re-ID tasks. Meanwhile, we introduce a new evaluation metric (mINP) for person Re-ID, indicating the cost for finding all the correct matches, which provides an additional criteria to evaluate the Re-ID system for real applications. Finally, some important yet under-investigated open issues are discussed.
Torchreid: A Library for Deep Learning Person Re-Identification in Pytorch
Oct 22, 2019


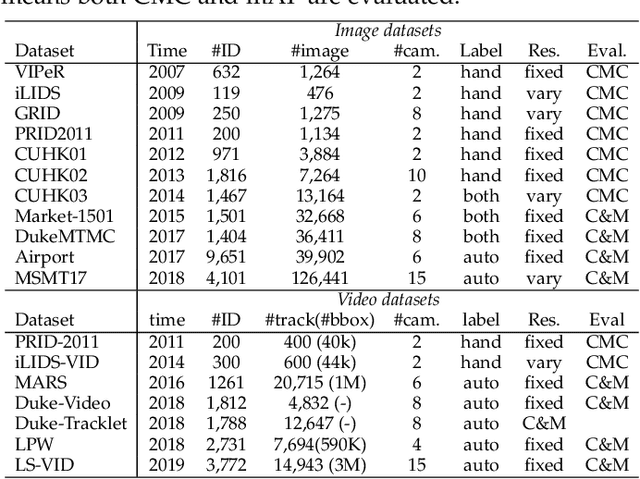
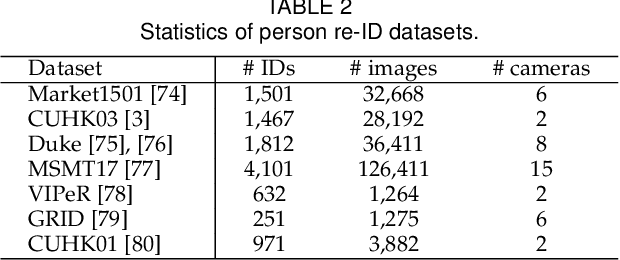
Person re-identification (re-ID), which aims to re-identify people across different camera views, has been significantly advanced by deep learning in recent years, particularly with convolutional neural networks (CNNs). In this paper, we present Torchreid, a software library built on PyTorch that allows fast development and end-to-end training and evaluation of deep re-ID models. As a general-purpose framework for person re-ID research, Torchreid provides (1) unified data loaders that support 15 commonly used re-ID benchmark datasets covering both image and video domains, (2) streamlined pipelines for quick development and benchmarking of deep re-ID models, and (3) implementations of the latest re-ID CNN architectures along with their pre-trained models to facilitate reproducibility as well as future research. With a high-level modularity in its design, Torchreid offers a great flexibility to allow easy extension to new datasets, CNN models and loss functions.
Learning Generalisable Omni-Scale Representations for Person Re-Identification
Oct 22, 2019
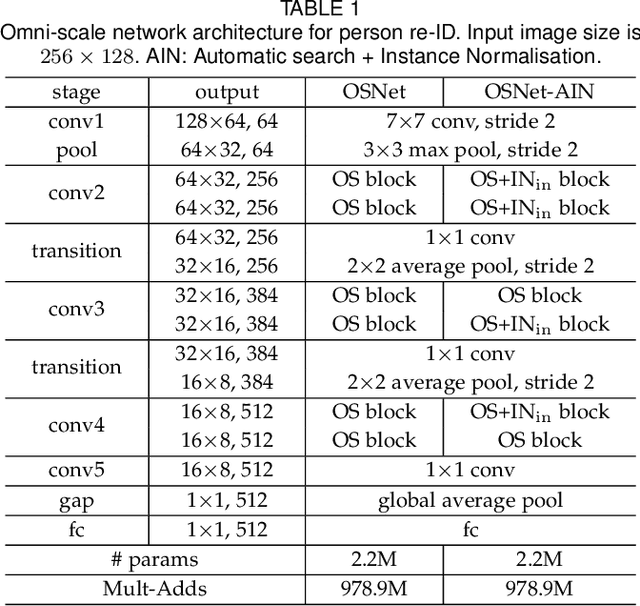
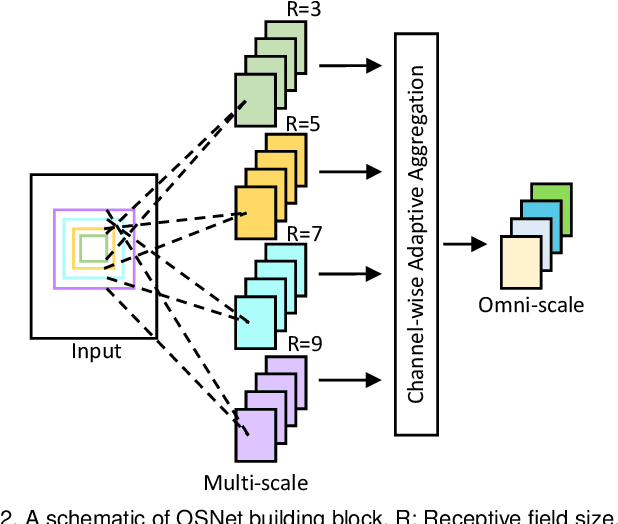
An effective person re-identification (re-ID) model should learn feature representations that are both discriminative, for distinguishing similar-looking people, and generalisable, for deployment across datasets without any adaptation. In this paper, we develop novel CNN architectures to address both challenges. First, we present a re-ID CNN termed omni-scale network (OSNet) to learn features that not only capture different spatial scales but also encapsulate a synergistic combination of multiple scales, namely omni-scale features. The basic building block consists of multiple convolutional streams, each detecting features at a certain scale. For omni-scale feature learning, a unified aggregation gate is introduced to dynamically fuse multi-scale features with channel-wise weights. OSNet is lightweight as its building blocks comprise factorised convolutions. Second, to improve generalisable feature learning, we introduce instance normalisation (IN) layers into OSNet to cope with cross-dataset discrepancies. Further, to determine the optimal placements of these IN layers in the architecture, we formulate an efficient differentiable architecture search algorithm. Extensive experiments show that, in the conventional same-dataset setting, OSNet achieves state-of-the-art performance, despite being much smaller than existing re-ID models. In the more challenging yet practical cross-dataset setting, OSNet beats most recent unsupervised domain adaptation methods without requiring any target data for model adaptation. Our code and models are released at \texttt{https://github.com/KaiyangZhou/deep-person-reid}.
Few-Shot Learning with Global Class Representations
Aug 14, 2019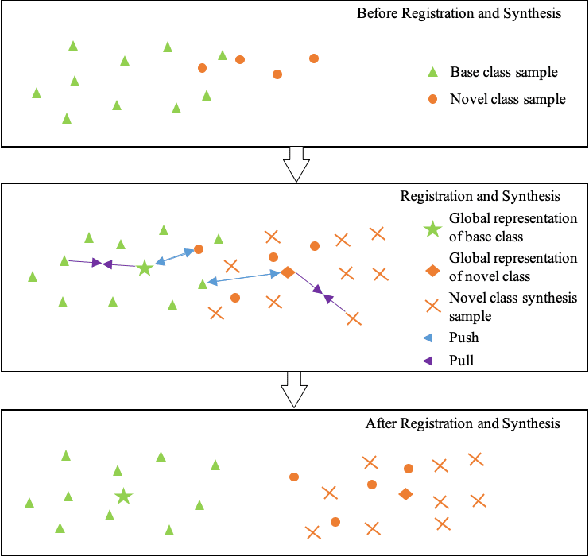
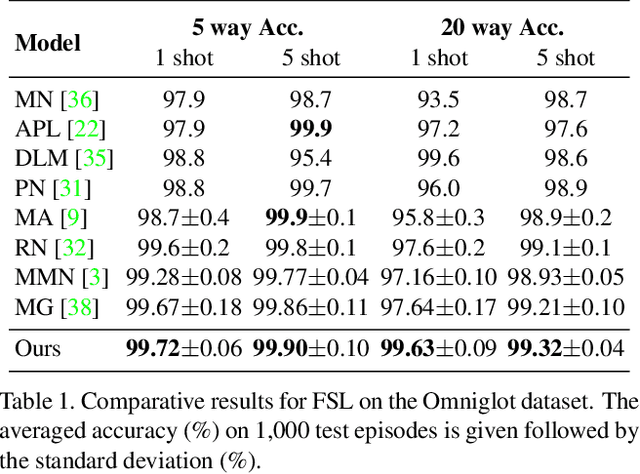
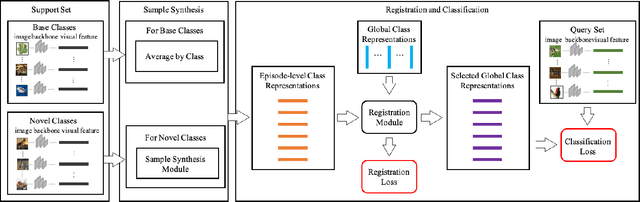
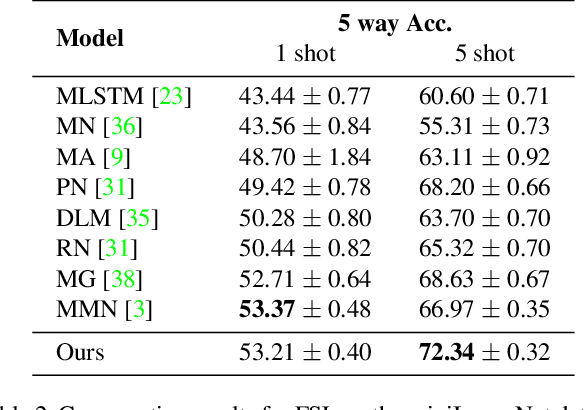
In this paper, we propose to tackle the challenging few-shot learning (FSL) problem by learning global class representations using both base and novel class training samples. In each training episode, an episodic class mean computed from a support set is registered with the global representation via a registration module. This produces a registered global class representation for computing the classification loss using a query set. Though following a similar episodic training pipeline as existing meta learning based approaches, our method differs significantly in that novel class training samples are involved in the training from the beginning. To compensate for the lack of novel class training samples, an effective sample synthesis strategy is developed to avoid overfitting. Importantly, by joint base-novel class training, our approach can be easily extended to a more practical yet challenging FSL setting, i.e., generalized FSL, where the label space of test data is extended to both base and novel classes. Extensive experiments show that our approach is effective for both of the two FSL settings.
Goal-Driven Sequential Data Abstraction
Aug 08, 2019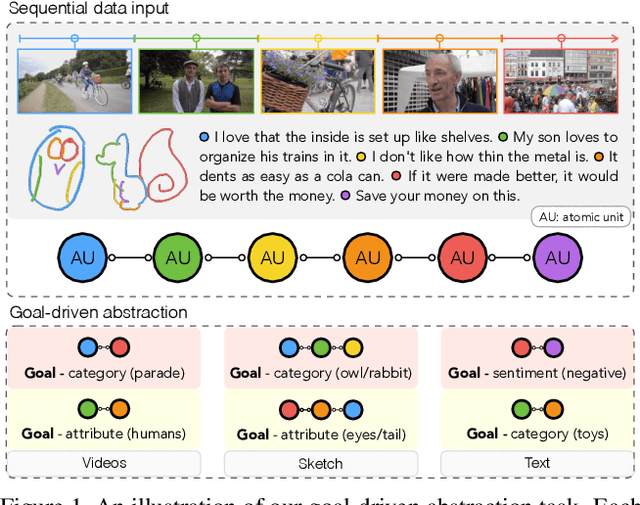
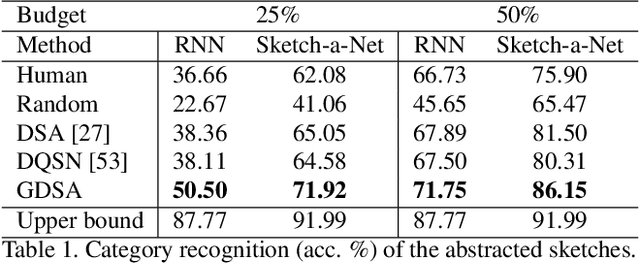
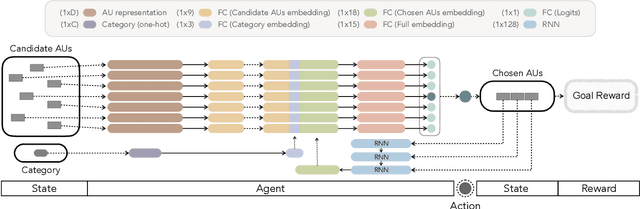
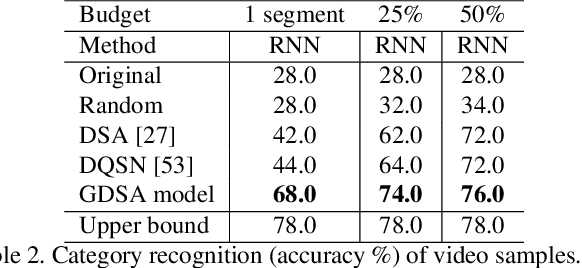
Automatic data abstraction is an important capability for both benchmarking machine intelligence and supporting summarization applications. In the former one asks whether a machine can `understand' enough about the meaning of input data to produce a meaningful but more compact abstraction. In the latter this capability is exploited for saving space or human time by summarizing the essence of input data. In this paper we study a general reinforcement learning based framework for learning to abstract sequential data in a goal-driven way. The ability to define different abstraction goals uniquely allows different aspects of the input data to be preserved according to the ultimate purpose of the abstraction. Our reinforcement learning objective does not require human-defined examples of ideal abstraction. Importantly our model processes the input sequence holistically without being constrained by the original input order. Our framework is also domain agnostic -- we demonstrate applications to sketch, video and text data and achieve promising results in all domains.
Omni-Scale Feature Learning for Person Re-Identification
May 02, 2019
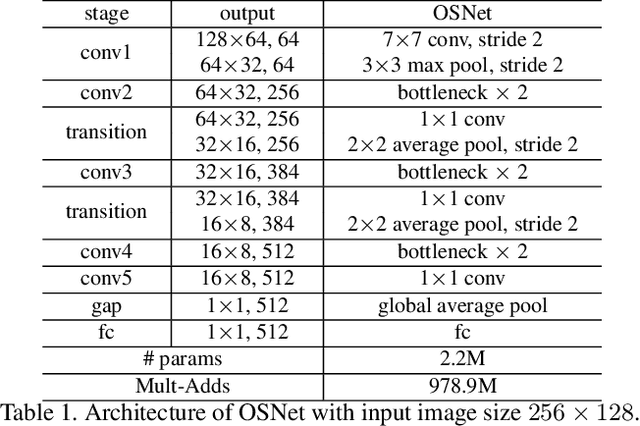
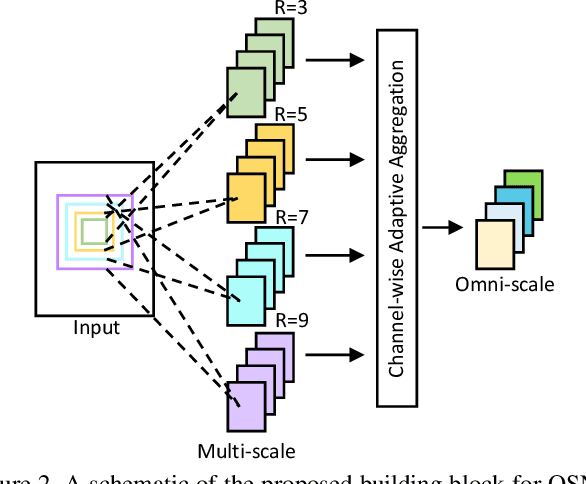
As an instance-level recognition problem, person re-identification (ReID) relies on discriminative features, which not only capture different spatial scales but also encapsulate an arbitrary combination of multiple scales. We call these features of both homogeneous and heterogeneous scales omni-scale features. In this paper, a novel deep CNN is designed, termed Omni-Scale Network (OSNet), for omni-scale feature learning in ReID. This is achieved by designing a residual block composed of multiple convolutional feature streams, each detecting features at a certain scale. Importantly, a novel unified aggregation gate is introduced to dynamically fuse multi-scale features with input-dependent channel-wise weights. To efficiently learn spatial-channel correlations and avoid overfitting, the building block uses both pointwise and depthwise convolutions. By stacking such blocks layer-by-layer, our OSNet is extremely lightweight and can be trained from scratch on existing ReID benchmarks. Despite its small model size, our OSNet achieves state-of-the-art performance on six person-ReID datasets.
Compressing deep neural networks by matrix product operators
Apr 11, 2019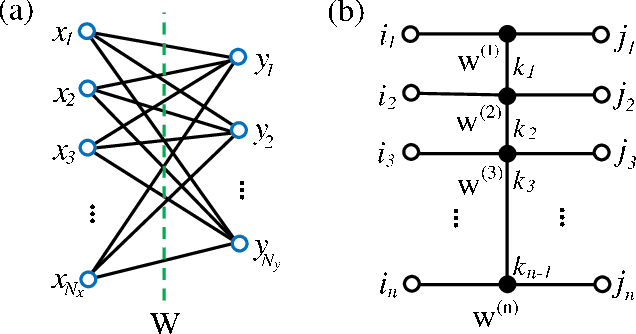
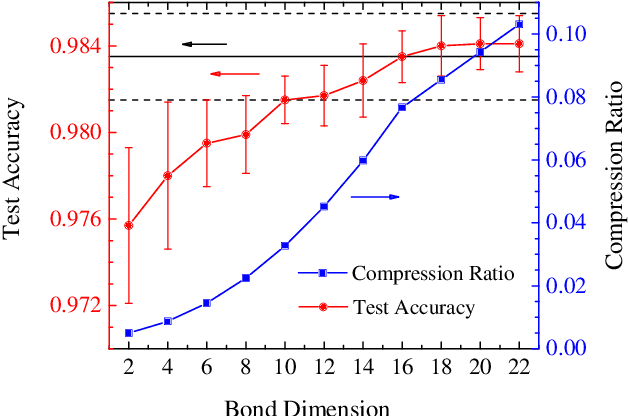
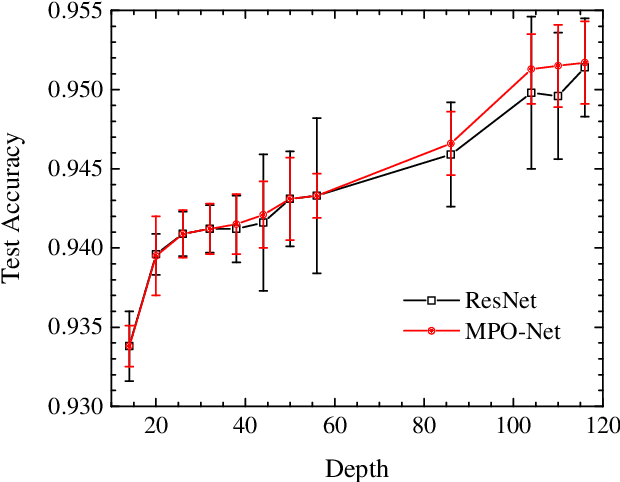

A deep neural network is a parameterization of a multi-layer mapping of signals in terms of many alternatively arranged linear and nonlinear transformations. The linear transformations, which are generally used in the fully-connected as well as convolutional layers, contain most of the variational parameters that are trained and stored. Compressing a deep neural network to reduce its number of variational parameters but not its prediction power is an important but challenging problem towards the establishment of an optimized scheme in training efficiently these parameters and in lowering the risk of overfitting. Here we show that this problem can be effectively solved by representing linear transformations with matrix product operators (MPO). We have tested this approach in five main neural networks, including FC2, LeNet-5, VGG, ResNet, and DenseNet on two widely used datasets, namely MNIST and CIFAR-10, and found that this MPO representation indeed sets up a faithful and efficient mapping between input and output signals, which can keep or even improve the prediction accuracy with dramatically reduced number of parameters.
Tree Tensor Networks for Generative Modeling
Jan 08, 2019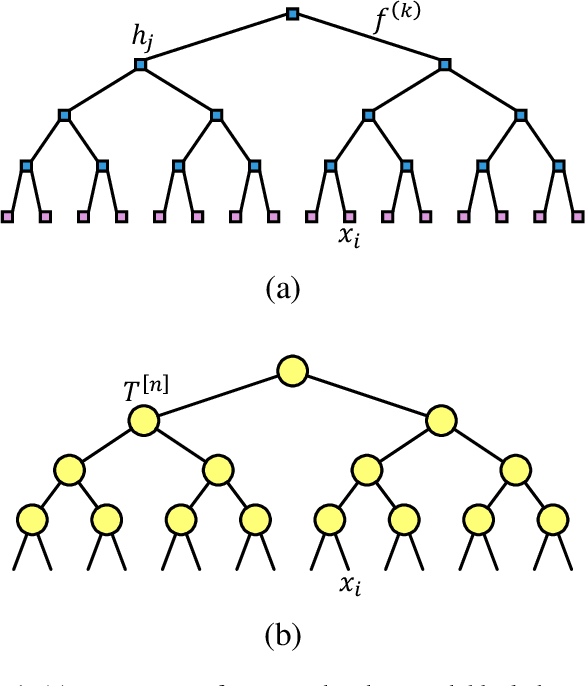
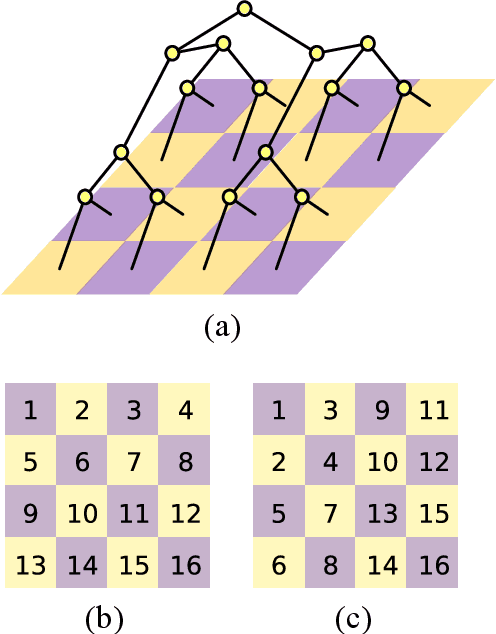
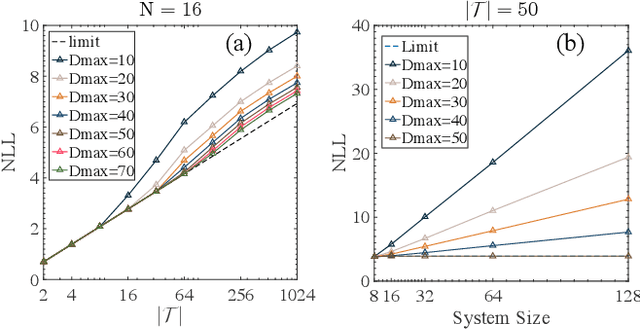
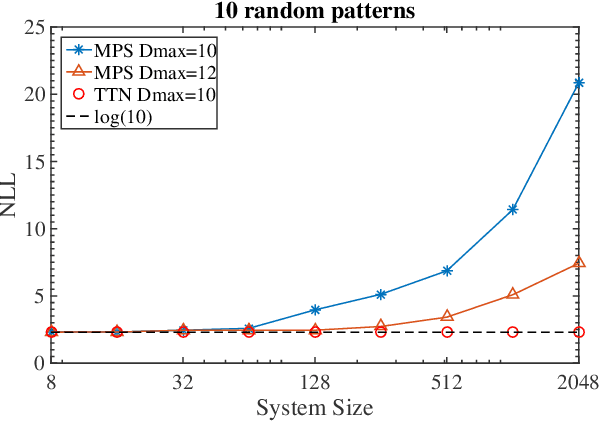
Matrix product states (MPS), a tensor network designed for one-dimensional quantum systems, has been recently proposed for generative modeling of natural data (such as images) in terms of `Born machine'. However, the exponential decay of correlation in MPS restricts its representation power heavily for modeling complex data such as natural images. In this work, we push forward the effort of applying tensor networks to machine learning by employing the Tree Tensor Network (TTN) which exhibits balanced performance in expressibility and efficient training and sampling. We design the tree tensor network to utilize the 2-dimensional prior of the natural images and develop sweeping learning and sampling algorithms which can be efficiently implemented utilizing Graphical Processing Units (GPU). We apply our model to random binary patterns and the binary MNIST datasets of handwritten digits. We show that TTN is superior to MPS for generative modeling in keeping correlation of pixels in natural images, as well as giving better log-likelihood scores in standard datasets of handwritten digits. We also compare its performance with state-of-the-art generative models such as the Variational AutoEncoders, Restricted Boltzmann machines, and PixelCNN. Finally, we discuss the future development of Tensor Network States in machine learning problems.
Face-Focused Cross-Stream Network for Deception Detection in Videos
Dec 11, 2018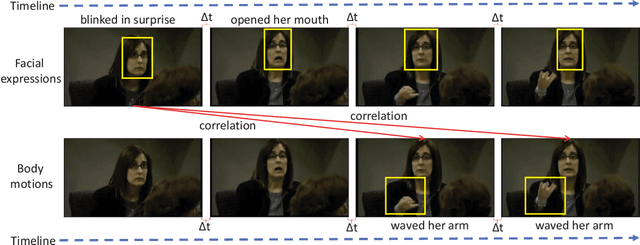
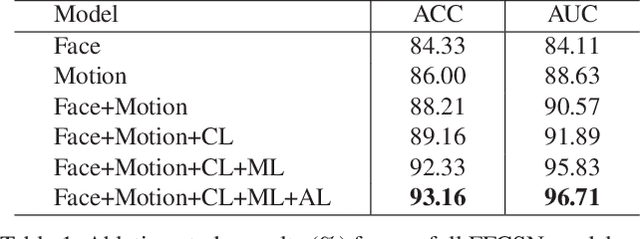
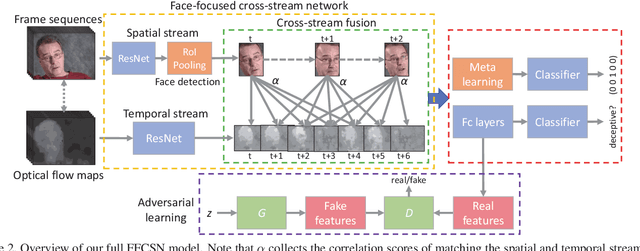
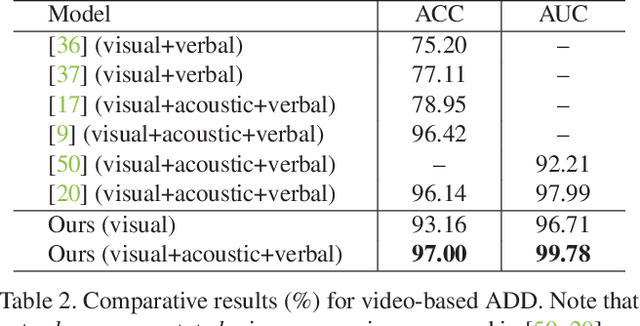
Automated deception detection (ADD) from real-life videos is a challenging task. It specifically needs to address two problems: (1) Both face and body contain useful cues regarding whether a subject is deceptive. How to effectively fuse the two is thus key to the effectiveness of an ADD model. (2) Real-life deceptive samples are hard to collect; learning with limited training data thus challenges most deep learning based ADD models. In this work, both problems are addressed. Specifically, for face-body multimodal learning, a novel face-focused cross-stream network (FFCSN) is proposed. It differs significantly from the popular two-stream networks in that: (a) face detection is added into the spatial stream to capture the facial expressions explicitly, and (b) correlation learning is performed across the spatial and temporal streams for joint deep feature learning across both face and body. To address the training data scarcity problem, our FFCSN model is trained with both meta learning and adversarial learning. Extensive experiments show that our FFCSN model achieves state-of-the-art results. Further, the proposed FFCSN model as well as its robust training strategy are shown to be generally applicable to other human-centric video analysis tasks such as emotion recognition from user-generated videos.
Zero-Shot Learning with Sparse Attribute Propagation
Dec 11, 2018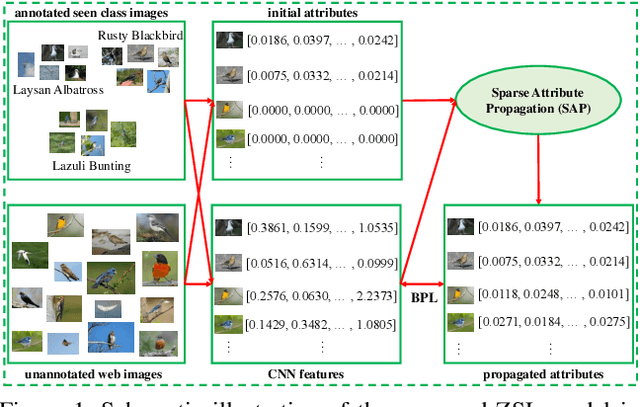
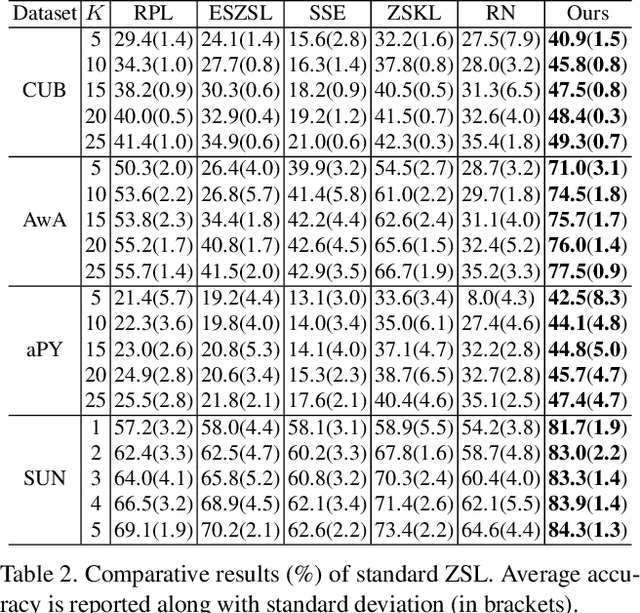

Zero-shot learning (ZSL) aims to recognize a set of unseen classes without any training images. The standard approach to ZSL requires a semantic descriptor for each class/instance, with attribute vector being the most widely used. Attribute annotation is expensive; it thus severely limits the scalability of ZSL. In this paper, we define a new ZSL setting where only a few images are annotated with attributes from each seen class. This is clearly more challenging yet more realistic than the conventional ZSL setting. To overcome the attribute sparsity under our new ZSL setting, we propose a novel inductive ZSL model termed sparse attribute propagation (SAP) by propagating attribute annotations to more unannotated images using sparse coding. This is followed by learning bidirectional projections between features and attributes for ZSL. An efficient solver is provided, together with rigorous theoretic algorithm analysis. With our SAP, we show that a ZSL training dataset can now be augmented by the abundant web images returned by image search engine, to further improve the model performance. Moreover, the general applicability of SAP is demonstrated on solving the social image annotation (SIA) problem. Extensive experiments show that our model achieves superior performance on both ZSL and SIA.