 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Self-supervised Learning with Automated Unsupervised Outlier Arbitration
Dec 15, 2021

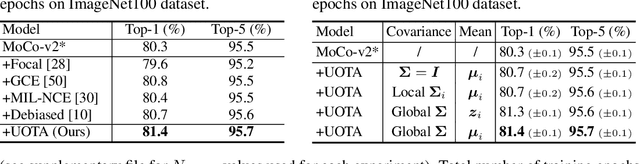
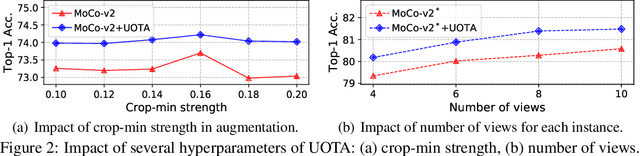
Our work reveals a structured shortcoming of the existing mainstream self-supervised learning methods. Whereas self-supervised learning frameworks usually take the prevailing perfect instance level invariance hypothesis for granted, we carefully investigate the pitfalls behind. Particularly, we argue that the existing augmentation pipeline for generating multiple positive views naturally introduces out-of-distribution (OOD) samples that undermine the learning of the downstream tasks. Generating diverse positive augmentations on the input does not always pay off in benefiting downstream tasks. To overcome this inherent deficiency, we introduce a lightweight latent variable model UOTA, targeting the view sampling issue for self-supervised learning. UOTA adaptively searches for the most important sampling region to produce views, and provides viable choice for outlier-robust self-supervised learning approaches. Our method directly generalizes to many mainstream self-supervised learning approaches, regardless of the loss's nature contrastive or not. We empirically show UOTA's advantage over the state-of-the-art self-supervised paradigms with evident margin, which well justifies the existence of the OOD sample issue embedded in the existing approaches. Especially, we theoretically prove that the merits of the proposal boil down to guaranteed estimator variance and bias reduction. Code is available: at https://github.com/ssl-codelab/uota.
A Style and Semantic Memory Mechanism for Domain Generalization
Dec 14, 2021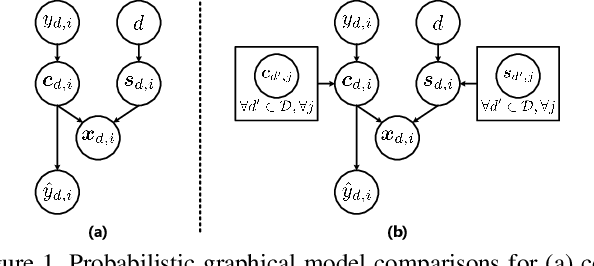
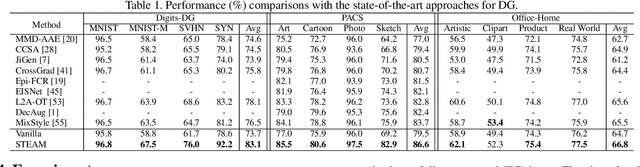
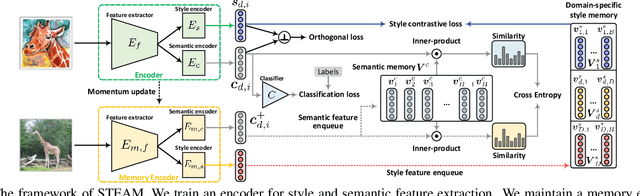
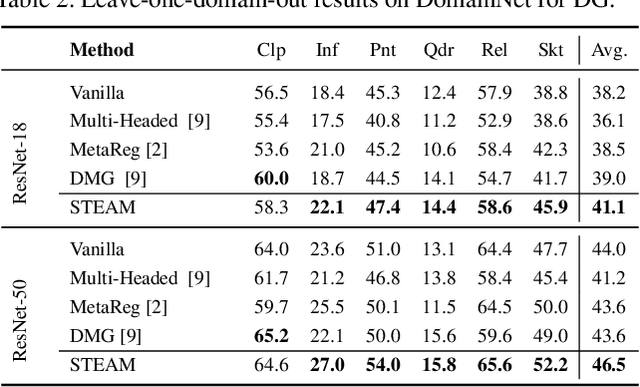
Mainstream state-of-the-art domain generalization algorithms tend to prioritize the assumption on semantic invariance across domains. Meanwhile, the inherent intra-domain style invariance is usually underappreciated and put on the shelf. In this paper, we reveal that leveraging intra-domain style invariance is also of pivotal importance in improving the efficiency of domain generalization. We verify that it is critical for the network to be informative on what domain features are invariant and shared among instances, so that the network sharpens its understanding and improves its semantic discriminative ability. Correspondingly, we also propose a novel "jury" mechanism, which is particularly effective in learning useful semantic feature commonalities among domains. Our complete model called STEAM can be interpreted as a novel probabilistic graphical model, for which the implementation requires convenient constructions of two kinds of memory banks: semantic feature bank and style feature bank. Empirical results show that our proposed framework surpasses the state-of-the-art methods by clear margins.
Transferrable Contrastive Learning for Visual Domain Adaptation
Dec 14, 2021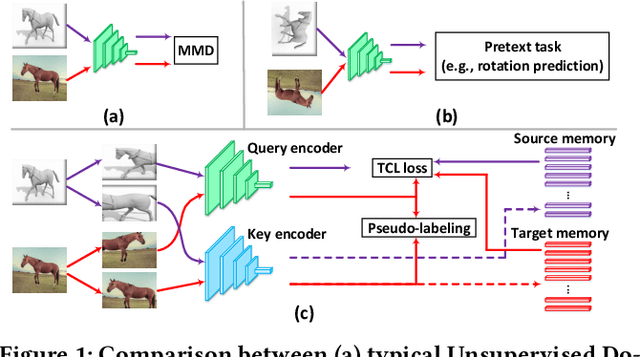
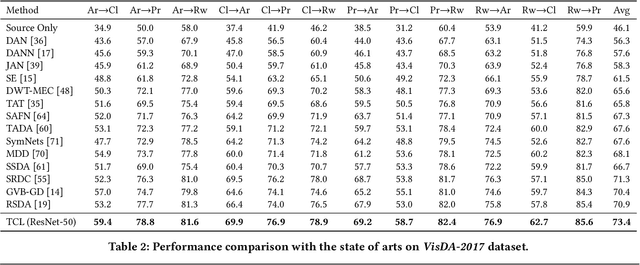
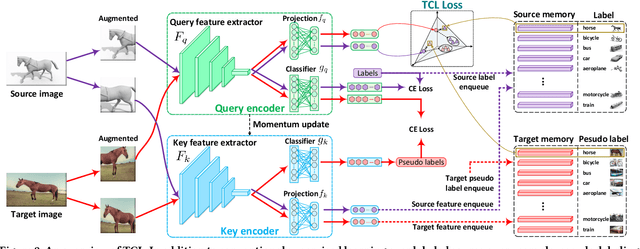
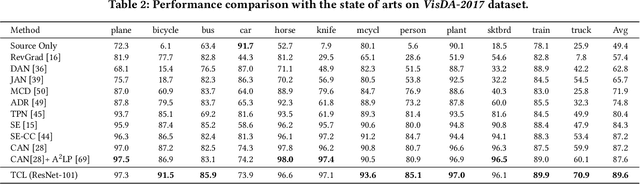
Self-supervised learning (SSL) has recently become the favorite among feature learning methodologies. It is therefore appealing for domain adaptation approaches to consider incorporating SSL. The intuition is to enforce instance-level feature consistency such that the predictor becomes somehow invariant across domains. However, most existing SSL methods in the regime of domain adaptation usually are treated as standalone auxiliary components, leaving the signatures of domain adaptation unattended. Actually, the optimal region where the domain gap vanishes and the instance level constraint that SSL peruses may not coincide at all. From this point, we present a particular paradigm of self-supervised learning tailored for domain adaptation, i.e., Transferrable Contrastive Learning (TCL), which links the SSL and the desired cross-domain transferability congruently. We find contrastive learning intrinsically a suitable candidate for domain adaptation, as its instance invariance assumption can be conveniently promoted to cross-domain class-level invariance favored by domain adaptation tasks. Based on particular memory bank constructions and pseudo label strategies, TCL then penalizes cross-domain intra-class domain discrepancy between source and target through a clean and novel contrastive loss. The free lunch is, thanks to the incorporation of contrastive learning, TCL relies on a moving-averaged key encoder that naturally achieves a temporally ensembled version of pseudo labels for target data, which avoids pseudo label error propagation at no extra cost. TCL therefore efficiently reduces cross-domain gaps. Through extensive experiments on benchmarks (Office-Home, VisDA-2017, Digits-five, PACS and DomainNet) for both single-source and multi-source domain adaptation tasks, TCL has demonstrated state-of-the-art performances.
CoCo-BERT: Improving Video-Language Pre-training with Contrastive Cross-modal Matching and Denoising
Dec 14, 2021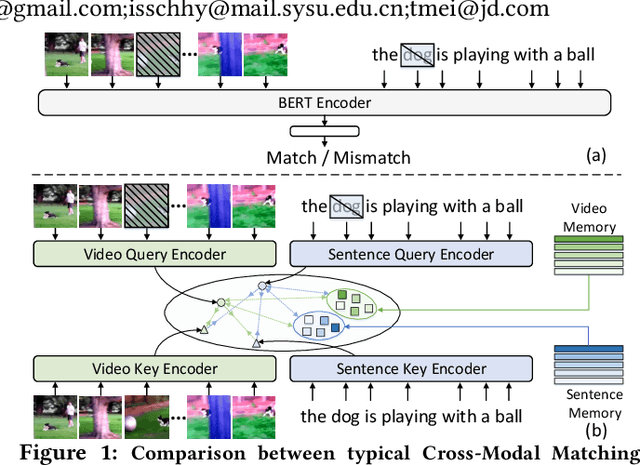
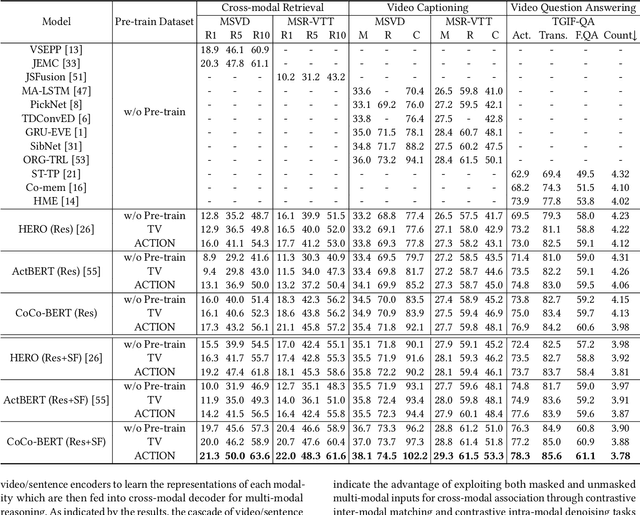
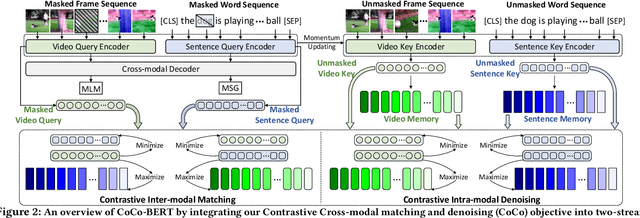
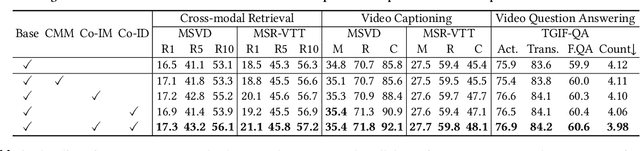
BERT-type structure has led to the revolution of vision-language pre-training and the achievement of state-of-the-art results on numerous vision-language downstream tasks. Existing solutions dominantly capitalize on the multi-modal inputs with mask tokens to trigger mask-based proxy pre-training tasks (e.g., masked language modeling and masked object/frame prediction). In this work, we argue that such masked inputs would inevitably introduce noise for cross-modal matching proxy task, and thus leave the inherent vision-language association under-explored. As an alternative, we derive a particular form of cross-modal proxy objective for video-language pre-training, i.e., Contrastive Cross-modal matching and denoising (CoCo). By viewing the masked frame/word sequences as the noisy augmentation of primary unmasked ones, CoCo strengthens video-language association by simultaneously pursuing inter-modal matching and intra-modal denoising between masked and unmasked inputs in a contrastive manner. Our CoCo proxy objective can be further integrated into any BERT-type encoder-decoder structure for video-language pre-training, named as Contrastive Cross-modal BERT (CoCo-BERT). We pre-train CoCo-BERT on TV dataset and a newly collected large-scale GIF video dataset (ACTION). Through extensive experiments over a wide range of downstream tasks (e.g., cross-modal retrieval, video question answering, and video captioning), we demonstrate the superiority of CoCo-BERT as a pre-trained structure.
Dual Spoof Disentanglement Generation for Face Anti-spoofing with Depth Uncertainty Learning
Dec 01, 2021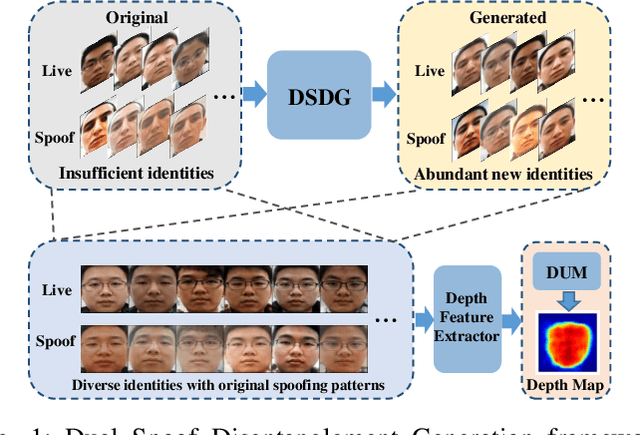
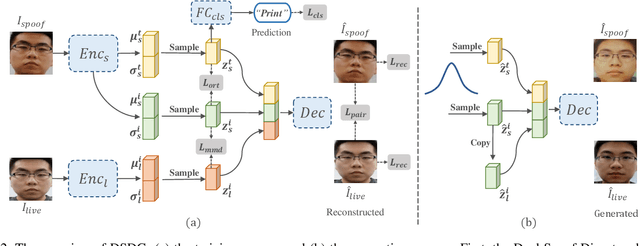
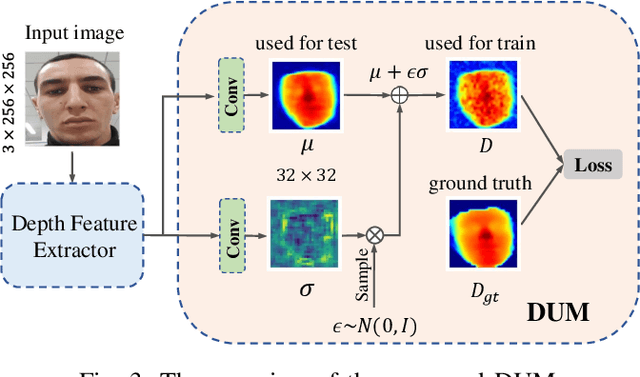
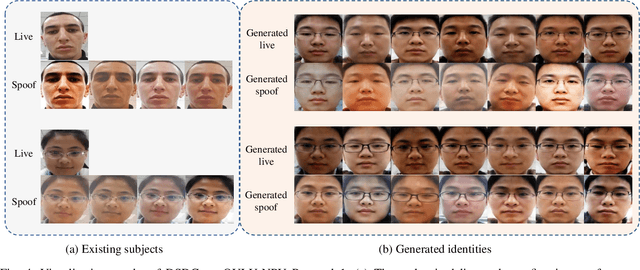
Face anti-spoofing (FAS) plays a vital role in preventing face recognition systems from presentation attacks. Existing face anti-spoofing datasets lack diversity due to the insufficient identity and insignificant variance, which limits the generalization ability of FAS model. In this paper, we propose Dual Spoof Disentanglement Generation (DSDG) framework to tackle this challenge by "anti-spoofing via generation". Depending on the interpretable factorized latent disentanglement in Variational Autoencoder (VAE), DSDG learns a joint distribution of the identity representation and the spoofing pattern representation in the latent space. Then, large-scale paired live and spoofing images can be generated from random noise to boost the diversity of the training set. However, some generated face images are partially distorted due to the inherent defect of VAE. Such noisy samples are hard to predict precise depth values, thus may obstruct the widely-used depth supervised optimization. To tackle this issue, we further introduce a lightweight Depth Uncertainty Module (DUM), which alleviates the adverse effects of noisy samples by depth uncertainty learning. DUM is developed without extra-dependency, thus can be flexibly integrated with any depth supervised network for face anti-spoofing. We evaluate the effectiveness of the proposed method on five popular benchmarks and achieve state-of-the-art results under both intra- and inter- test settings. The codes are available at https://github.com/JDAI-CV/FaceX-Zoo/tree/main/addition_module/DSDG.
Directional Self-supervised Learning for Risky Image Augmentations
Oct 26, 2021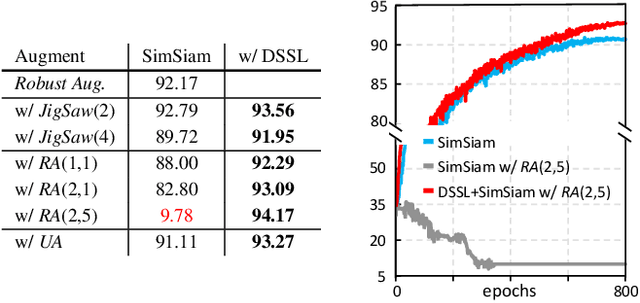
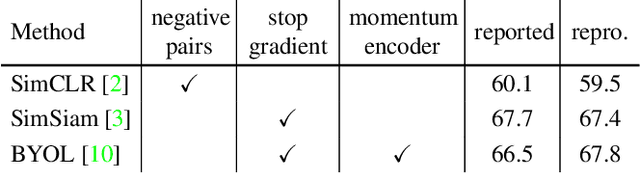
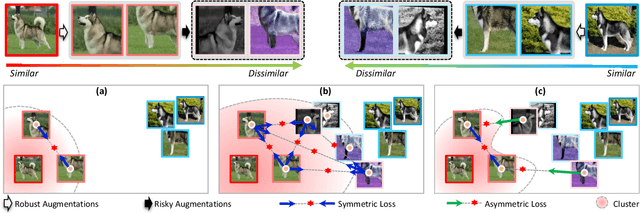

Only a few cherry-picked robust augmentation policies are beneficial to standard self-supervised image representation learning, despite the large augmentation family. In this paper, we propose a directional self-supervised learning paradigm (DSSL), which is compatible with significantly more augmentations. Specifically, we adapt risky augmentation policies after standard views augmented by robust augmentations, to generate harder risky view (RV). The risky view usually has a higher deviation from the original image than the standard robust view (SV). Unlike previous methods equally pairing all augmented views for symmetrical self-supervised training to maximize their similarities, DSSL treats augmented views of the same instance as a partially ordered set (SV$\leftrightarrow $SV, SV$\leftarrow$RV), and then equips directional objective functions respecting to the derived relationships among views. DSSL can be easily implemented with a few lines of Pseudocode and is highly flexible to popular self-supervised learning frameworks, including SimCLR, SimSiam, BYOL. The extensive experimental results on CIFAR and ImageNet demonstrated that DSSL can stably improve these frameworks with compatibility to a wider range of augmentations.
ViDA-MAN: Visual Dialog with Digital Humans
Oct 26, 2021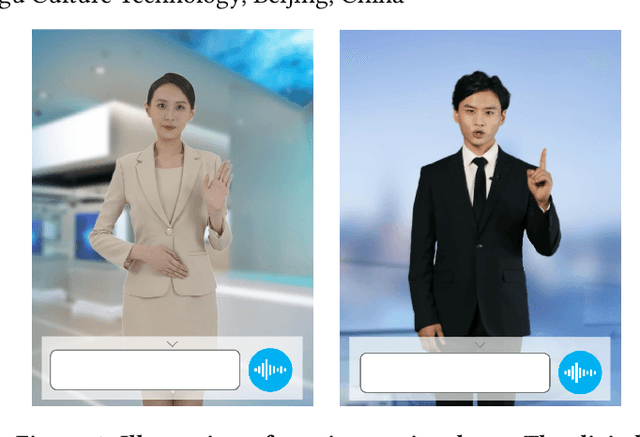
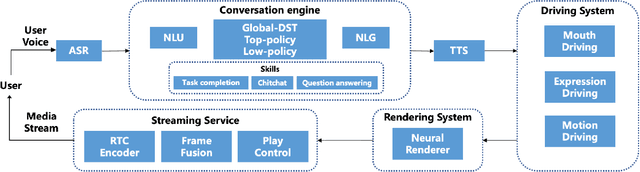
We demonstrate ViDA-MAN, a digital-human agent for multi-modal interaction, which offers realtime audio-visual responses to instant speech inquiries. Compared to traditional text or voice-based system, ViDA-MAN offers human-like interactions (e.g, vivid voice, natural facial expression and body gestures). Given a speech request, the demonstration is able to response with high quality videos in sub-second latency. To deliver immersive user experience, ViDA-MAN seamlessly integrates multi-modal techniques including Acoustic Speech Recognition (ASR), multi-turn dialog, Text To Speech (TTS), talking heads video generation. Backed with large knowledge base, ViDA-MAN is able to chat with users on a number of topics including chit-chat, weather, device control, News recommendations, booking hotels, as well as answering questions via structured knowledge.
A Baseline Framework for Part-level Action Parsing and Action Recognition
Oct 07, 2021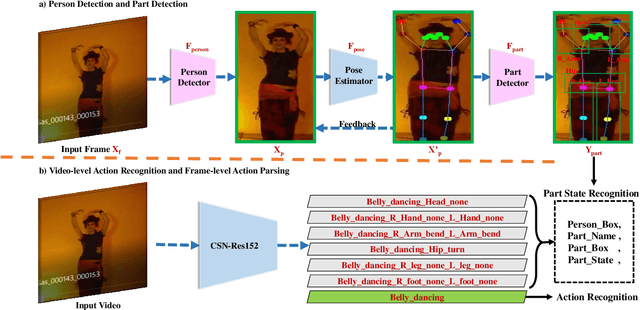


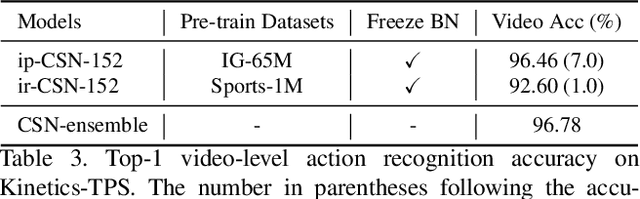
This technical report introduces our 2nd place solution to Kinetics-TPS Track on Part-level Action Parsing in ICCV DeeperAction Workshop 2021. Our entry is mainly based on YOLOF for instance and part detection, HRNet for human pose estimation, and CSN for video-level action recognition and frame-level part state parsing. We describe technical details for the Kinetics-TPS dataset, together with some experimental results. In the competition, we achieved 61.37% mAP on the test set of Kinetics-TPS.
CoSeg: Cognitively Inspired Unsupervised Generic Event Segmentation
Sep 30, 2021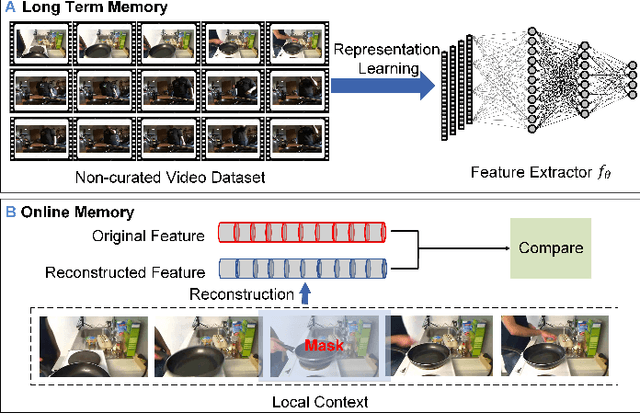
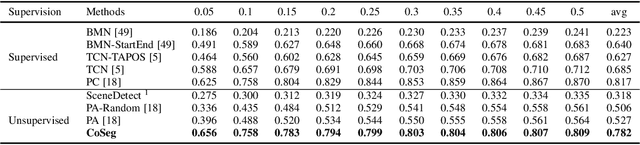
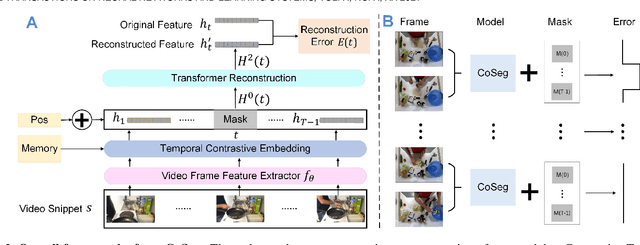
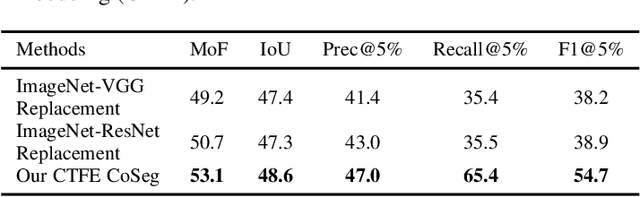
Some cognitive research has discovered that humans accomplish event segmentation as a side effect of event anticipation. Inspired by this discovery, we propose a simple yet effective end-to-end self-supervised learning framework for event segmentation/boundary detection. Unlike the mainstream clustering-based methods, our framework exploits a transformer-based feature reconstruction scheme to detect event boundary by reconstruction errors. This is consistent with the fact that humans spot new events by leveraging the deviation between their prediction and what is actually perceived. Thanks to their heterogeneity in semantics, the frames at boundaries are difficult to be reconstructed (generally with large reconstruction errors), which is favorable for event boundary detection. Additionally, since the reconstruction occurs on the semantic feature level instead of pixel level, we develop a temporal contrastive feature embedding module to learn the semantic visual representation for frame feature reconstruction. This procedure is like humans building up experiences with "long-term memory". The goal of our work is to segment generic events rather than localize some specific ones. We focus on achieving accurate event boundaries. As a result, we adopt F1 score (Precision/Recall) as our primary evaluation metric for a fair comparison with previous approaches. Meanwhile, we also calculate the conventional frame-based MoF and IoU metric. We thoroughly benchmark our work on four publicly available datasets and demonstrate much better results.
Semi-Supervised Domain Generalizable Person Re-Identification
Sep 09, 2021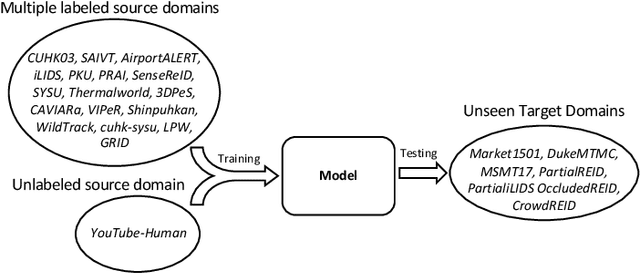
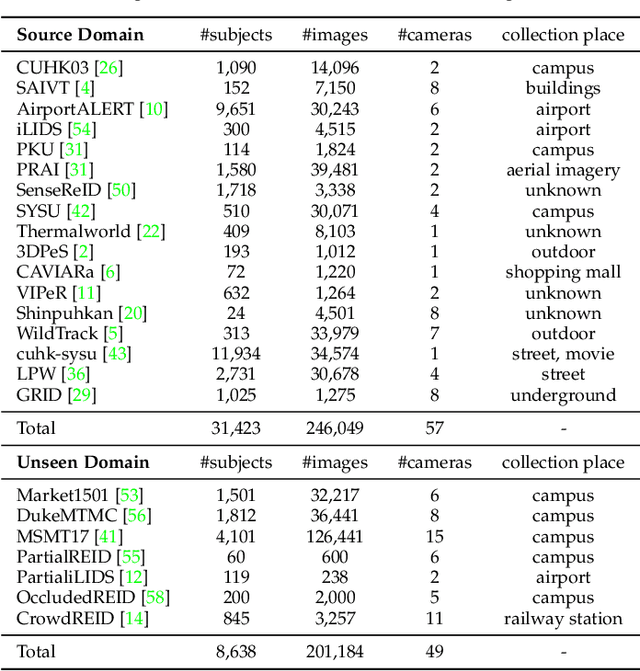
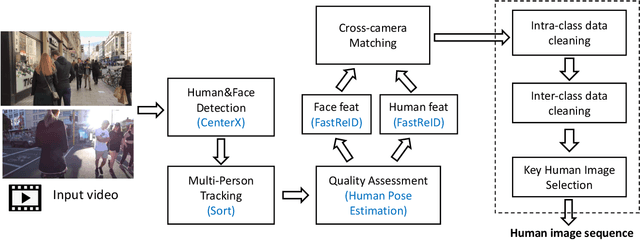

Existing person re-identification (re-id) methods are stuck when deployed to a new unseen scenario despite the success in cross-camera person matching. Recent efforts have been substantially devoted to domain adaptive person re-id where extensive unlabeled data in the new scenario are utilized in a transductive learning manner. However, for each scenario, it is required to first collect enough data and then train such a domain adaptive re-id model, thus restricting their practical application. Instead, we aim to explore multiple labeled datasets to learn generalized domain-invariant representations for person re-id, which is expected universally effective for each new-coming re-id scenario. To pursue practicability in real-world systems, we collect all the person re-id datasets (20 datasets) in this field and select the three most frequently used datasets (i.e., Market1501, DukeMTMC, and MSMT17) as unseen target domains. In addition, we develop DataHunter that collects over 300K+ weak annotated images named YouTube-Human from YouTube street-view videos, which joins 17 remaining full labeled datasets to form multiple source domains. On such a large and challenging benchmark called FastHuman (~440K+ labeled images), we further propose a simple yet effective Semi-Supervised Knowledge Distillation (SSKD) framework. SSKD effectively exploits the weakly annotated data by assigning soft pseudo labels to YouTube-Human to improve models' generalization ability. Experiments on several protocols verify the effectiveness of the proposed SSKD framework on domain generalizable person re-id, which is even comparable to supervised learning on the target domains. Lastly, but most importantly, we hope the proposed benchmark FastHuman could bring the next development of domain generalizable person re-id algorithms.