 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZooming into Face Forensics: A Pixel-level Analysis
Dec 12, 2019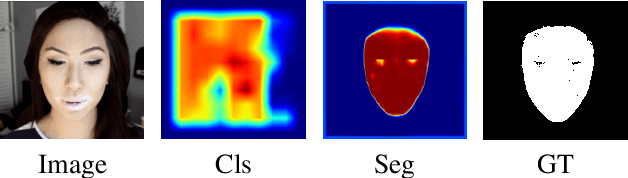
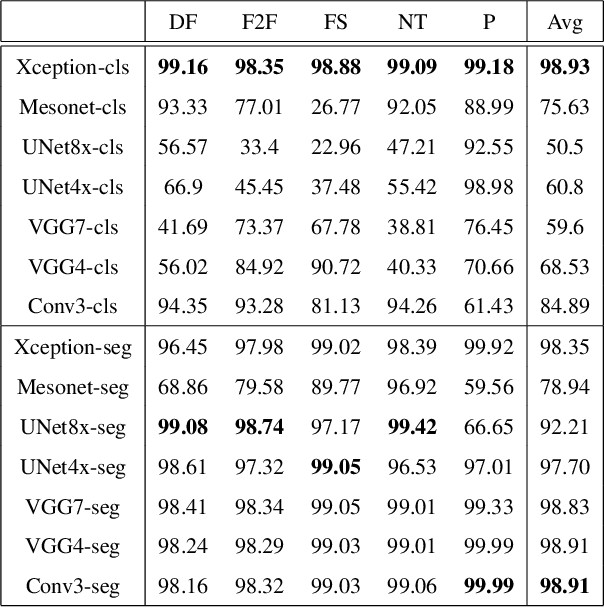
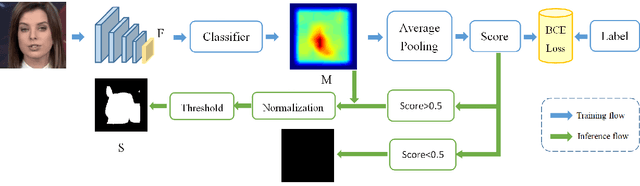
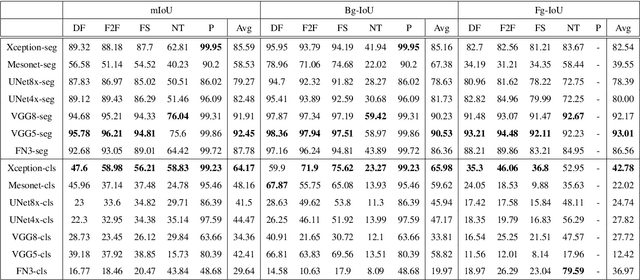
The stunning progress in face manipulation methods has made it possible to synthesize realistic fake face images, which poses potential threats to our society. It is urgent to have face forensics techniques to distinguish those tampered images. A large scale dataset "FaceForensics++" has provided enormous training data generated from prominent face manipulation methods to facilitate anti-fake research. However, previous works focus more on casting it as a classification problem by only considering a global prediction. Through investigation to the problem, we find that training a classification network often fails to capture high quality features, which might lead to sub-optimal solutions. In this paper, we zoom in on the problem by conducting a pixel-level analysis, i.e. formulating it as a pixel-level segmentation task. By evaluating multiple architectures on both segmentation and classification tasks, We show the superiority of viewing the problem from a segmentation perspective. Different ablation studies are also performed to investigate what makes an effective and efficient anti-fake model. Strong baselines are also established, which, we hope, could shed some light on the field of face forensics.
Mis-classified Vector Guided Softmax Loss for Face Recognition
Nov 26, 2019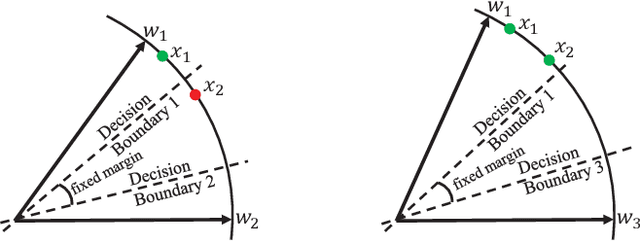
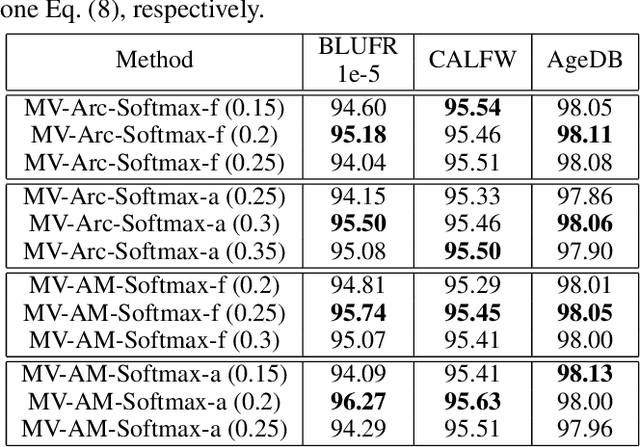
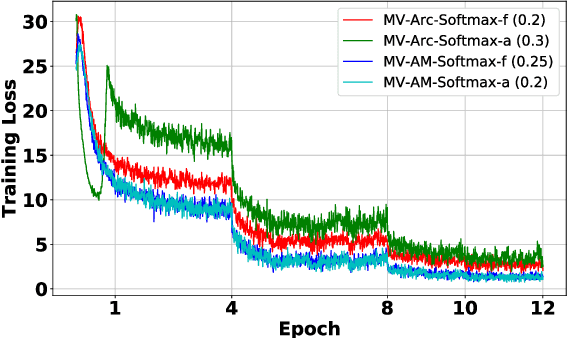
Face recognition has witnessed significant progress due to the advances of deep convolutional neural networks (CNNs), the central task of which is how to improve the feature discrimination. To this end, several margin-based (\textit{e.g.}, angular, additive and additive angular margins) softmax loss functions have been proposed to increase the feature margin between different classes. However, despite great achievements have been made, they mainly suffer from three issues: 1) Obviously, they ignore the importance of informative features mining for discriminative learning; 2) They encourage the feature margin only from the ground truth class, without realizing the discriminability from other non-ground truth classes; 3) The feature margin between different classes is set to be same and fixed, which may not adapt the situations very well. To cope with these issues, this paper develops a novel loss function, which adaptively emphasizes the mis-classified feature vectors to guide the discriminative feature learning. Thus we can address all the above issues and achieve more discriminative face features. To the best of our knowledge, this is the first attempt to inherit the advantages of feature margin and feature mining into a unified loss function. Experimental results on several benchmarks have demonstrated the effectiveness of our method over state-of-the-art alternatives.
Scheduled Differentiable Architecture Search for Visual Recognition
Sep 23, 2019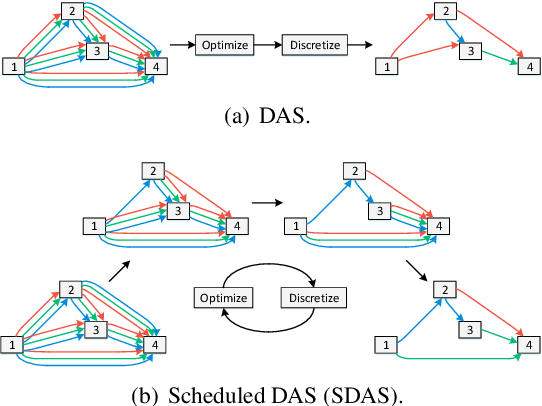
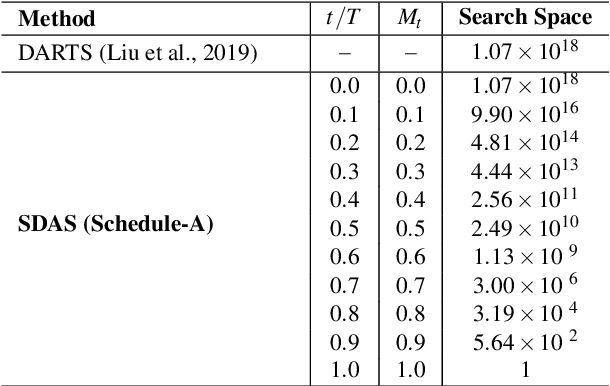
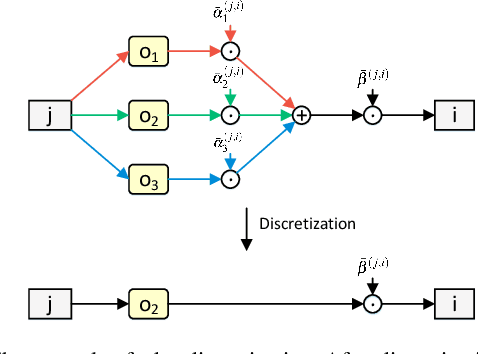
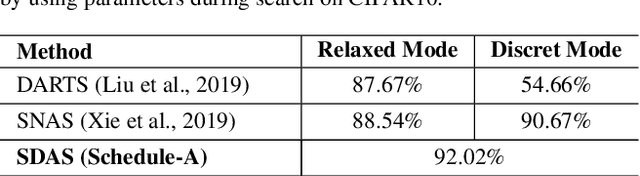
Convolutional Neural Networks (CNN) have been regarded as a capable class of models for visual recognition problems. Nevertheless, it is not trivial to develop generic and powerful network architectures, which requires significant efforts of human experts. In this paper, we introduce a new idea for automatically exploring architectures on a remould of Differentiable Architecture Search (DAS), which possesses the efficient search via gradient descent. Specifically, we present Scheduled Differentiable Architecture Search (SDAS) for both image and video recognition that nicely integrates the selection of operations during training with a schedule. Technically, an architecture or a cell is represented as a directed graph. Our SDAS gradually fixes the operations on the edges in the graph in a progressive and scheduled manner, as opposed to a one-step decision of operations for all the edges once the training completes in existing DAS, which may make the architecture brittle. Moreover, we enlarge the search space of SDAS particularly for video recognition by devising several unique operations to encode spatio-temporal dynamics and demonstrate the impact in affecting the architecture search of SDAS. Extensive experiments of architecture learning are conducted on CIFAR10, Kinetics10, UCF101 and HMDB51 datasets, and superior results are reported when comparing to DAS method. More remarkably, the search by our SDAS is around 2-fold faster than DAS. When transferring the learnt cells on CIFAR10 and Kinetics10 respectively to large-scale ImageNet and Kinetics400 datasets, the constructed network also outperforms several state-of-the-art hand-crafted structures.
Hierarchy Parsing for Image Captioning
Sep 10, 2019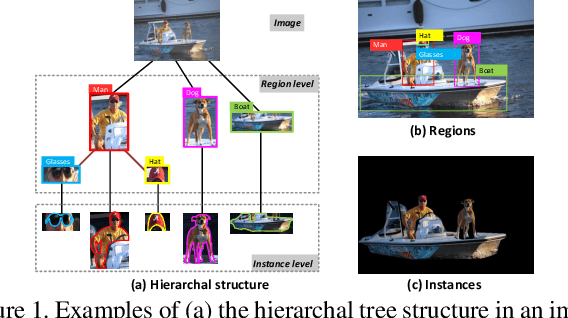
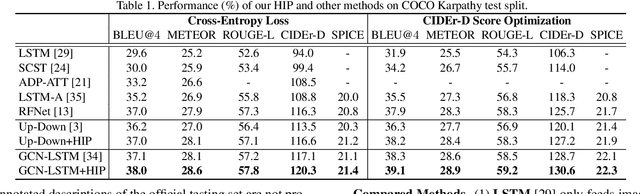
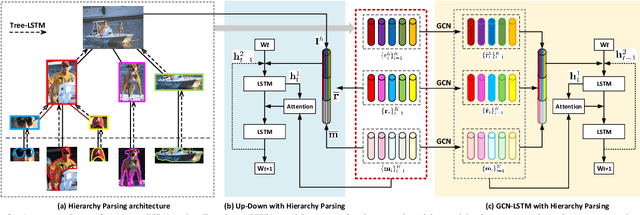
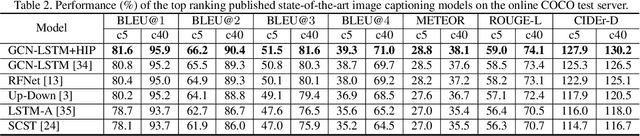
It is always well believed that parsing an image into constituent visual patterns would be helpful for understanding and representing an image. Nevertheless, there has not been evidence in support of the idea on describing an image with a natural-language utterance. In this paper, we introduce a new design to model a hierarchy from instance level (segmentation), region level (detection) to the whole image to delve into a thorough image understanding for captioning. Specifically, we present a HIerarchy Parsing (HIP) architecture that novelly integrates hierarchical structure into image encoder. Technically, an image decomposes into a set of regions and some of the regions are resolved into finer ones. Each region then regresses to an instance, i.e., foreground of the region. Such process naturally builds a hierarchal tree. A tree-structured Long Short-Term Memory (Tree-LSTM) network is then employed to interpret the hierarchal structure and enhance all the instance-level, region-level and image-level features. Our HIP is appealing in view that it is pluggable to any neural captioning models. Extensive experiments on COCO image captioning dataset demonstrate the superiority of HIP. More remarkably, HIP plus a top-down attention-based LSTM decoder increases CIDEr-D performance from 120.1% to 127.2% on COCO Karpathy test split. When further endowing instance-level and region-level features from HIP with semantic relation learnt through Graph Convolutional Networks (GCN), CIDEr-D is boosted up to 130.6%.
Deep Metric Learning with Density Adaptivity
Sep 09, 2019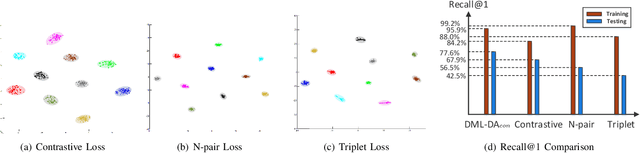
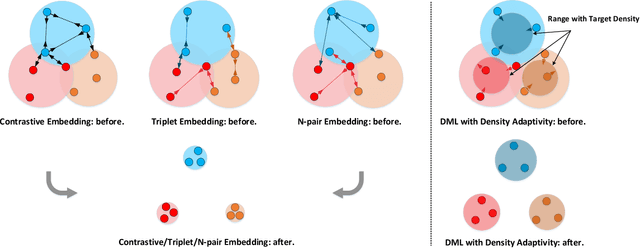
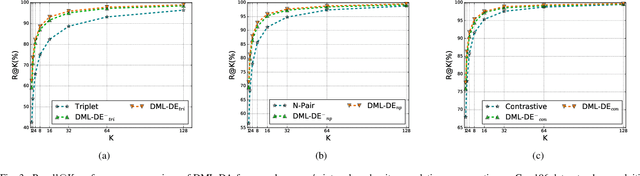
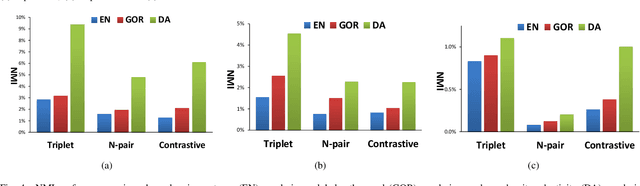
The problem of distance metric learning is mostly considered from the perspective of learning an embedding space, where the distances between pairs of examples are in correspondence with a similarity metric. With the rise and success of Convolutional Neural Networks (CNN), deep metric learning (DML) involves training a network to learn a nonlinear transformation to the embedding space. Existing DML approaches often express the supervision through maximizing inter-class distance and minimizing intra-class variation. However, the results can suffer from overfitting problem, especially when the training examples of each class are embedded together tightly and the density of each class is very high. In this paper, we integrate density, i.e., the measure of data concentration in the representation, into the optimization of DML frameworks to adaptively balance inter-class similarity and intra-class variation by training the architecture in an end-to-end manner. Technically, the knowledge of density is employed as a regularizer, which is pluggable to any DML architecture with different objective functions such as contrastive loss, N-pair loss and triplet loss. Extensive experiments on three public datasets consistently demonstrate clear improvements by amending three types of embedding with the density adaptivity. More remarkably, our proposal increases Recall@1 from 67.95% to 77.62%, from 52.01% to 55.64% and from 68.20% to 70.56% on Cars196, CUB-200-2011 and Stanford Online Products dataset, respectively.
Gaussian Temporal Awareness Networks for Action Localization
Sep 09, 2019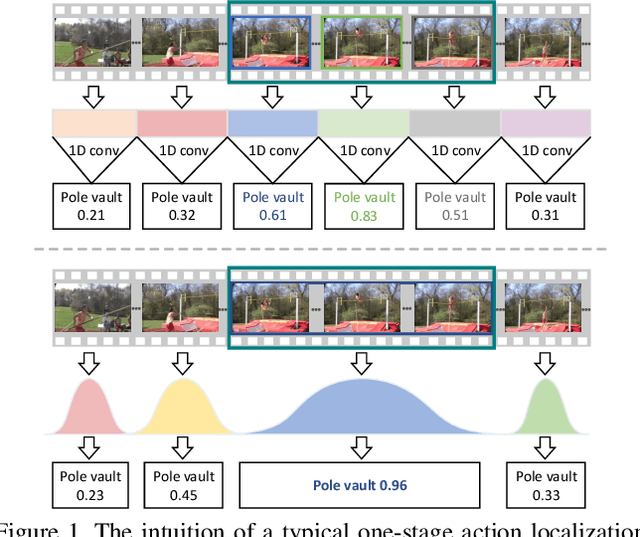
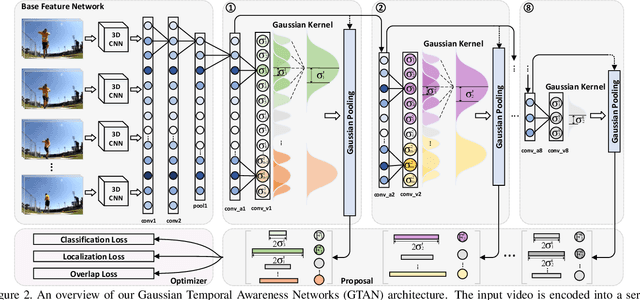
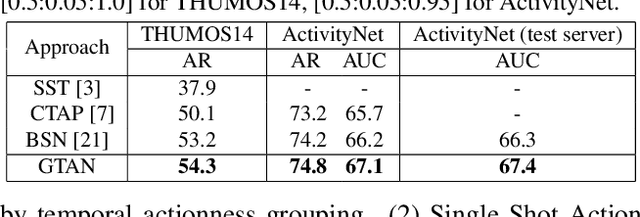
Temporally localizing actions in a video is a fundamental challenge in video understanding. Most existing approaches have often drawn inspiration from image object detection and extended the advances, e.g., SSD and Faster R-CNN, to produce temporal locations of an action in a 1D sequence. Nevertheless, the results can suffer from robustness problem due to the design of predetermined temporal scales, which overlooks the temporal structure of an action and limits the utility on detecting actions with complex variations. In this paper, we propose to address the problem by introducing Gaussian kernels to dynamically optimize temporal scale of each action proposal. Specifically, we present Gaussian Temporal Awareness Networks (GTAN) --- a new architecture that novelly integrates the exploitation of temporal structure into an one-stage action localization framework. Technically, GTAN models the temporal structure through learning a set of Gaussian kernels, each for a cell in the feature maps. Each Gaussian kernel corresponds to a particular interval of an action proposal and a mixture of Gaussian kernels could further characterize action proposals with various length. Moreover, the values in each Gaussian curve reflect the contextual contributions to the localization of an action proposal. Extensive experiments are conducted on both THUMOS14 and ActivityNet v1.3 datasets, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, GTAN achieves 1.9% and 1.1% improvements in mAP on testing set of the two datasets.
Relationship-Aware Spatial Perception Fusion for Realistic Scene Layout Generation
Sep 02, 2019
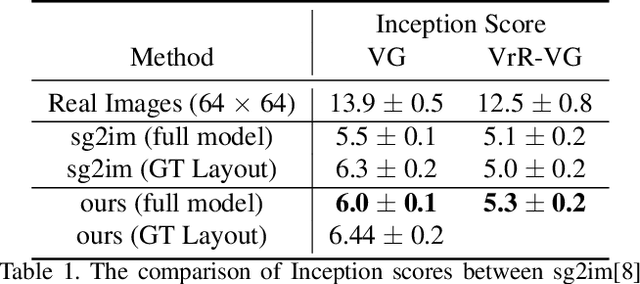
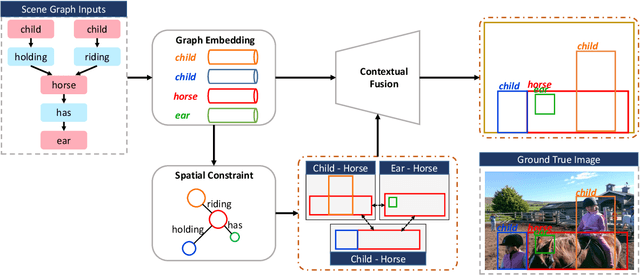
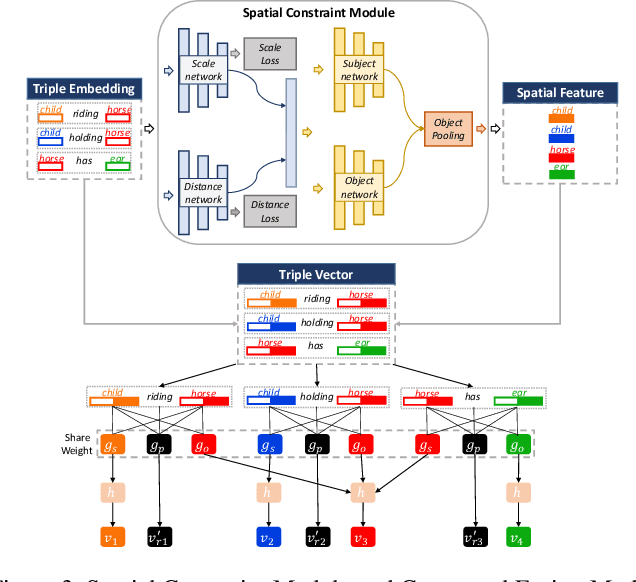
The significant progress on Generative Adversarial Networks (GANs) have made it possible to generate surprisingly realistic images for single object based on natural language descriptions. However, controlled generation of images for multiple entities with explicit interactions is still difficult to achieve due to the scene layout generation heavily suffer from the diversity object scaling and spatial locations. In this paper, we proposed a novel framework for generating realistic image layout from textual scene graphs. In our framework, a spatial constraint module is designed to fit reasonable scaling and spatial layout of object pairs with considering relationship between them. Moreover, a contextual fusion module is introduced for fusing pair-wise spatial information in terms of object dependency in scene graph. By using these two modules, our proposed framework tends to generate more commonsense layout which is helpful for realistic image generation. Experimental results including quantitative results, qualitative results and user studies on two different scene graph datasets demonstrate our proposed framework's ability to generate complex and logical layout with multiple objects from scene graph.
Customizable Architecture Search for Semantic Segmentation
Aug 26, 2019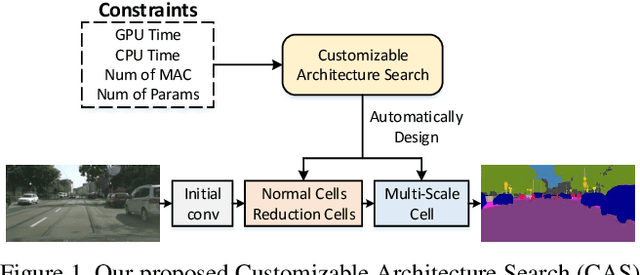
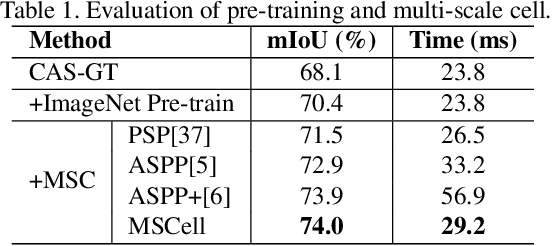
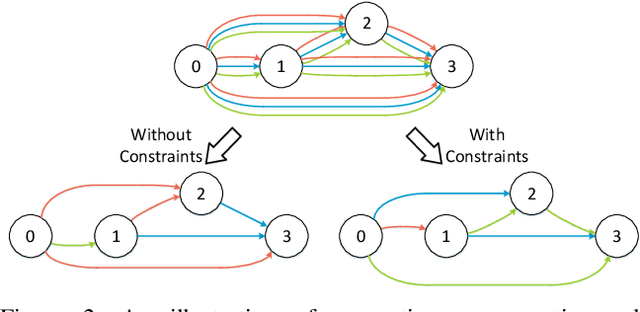
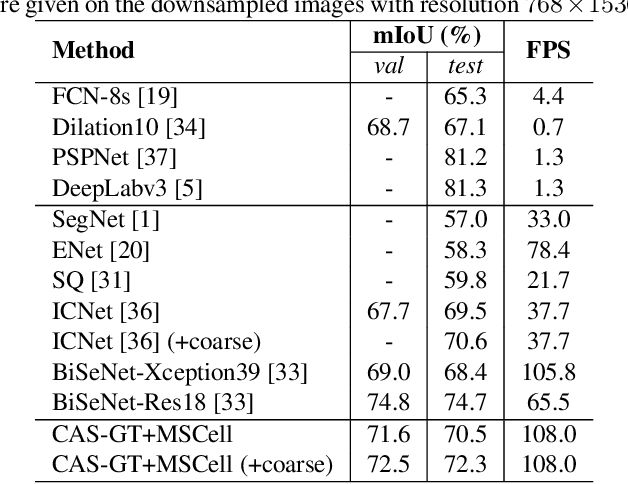
In this paper, we propose a Customizable Architecture Search (CAS) approach to automatically generate a network architecture for semantic image segmentation. The generated network consists of a sequence of stacked computation cells. A computation cell is represented as a directed acyclic graph, in which each node is a hidden representation (i.e., feature map) and each edge is associated with an operation (e.g., convolution and pooling), which transforms data to a new layer. During the training, the CAS algorithm explores the search space for an optimized computation cell to build a network. The cells of the same type share one architecture but with different weights. In real applications, however, an optimization may need to be conducted under some constraints such as GPU time and model size. To this end, a cost corresponding to the constraint will be assigned to each operation. When an operation is selected during the search, its associated cost will be added to the objective. As a result, our CAS is able to search an optimized architecture with customized constraints. The approach has been thoroughly evaluated on Cityscapes and CamVid datasets, and demonstrates superior performance over several state-of-the-art techniques. More remarkably, our CAS achieves 72.3% mIoU on the Cityscapes dataset with speed of 108 FPS on an Nvidia TitanXp GPU.
Mocycle-GAN: Unpaired Video-to-Video Translation
Aug 26, 2019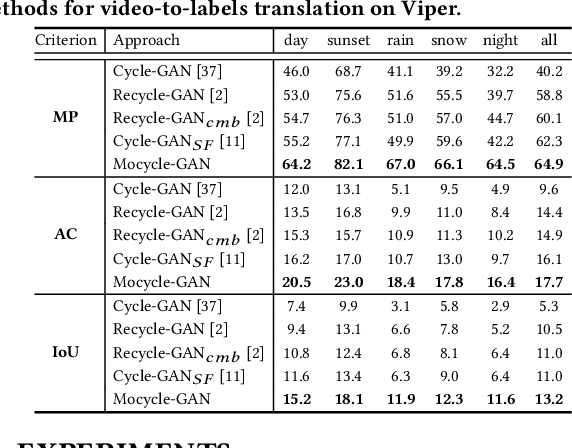
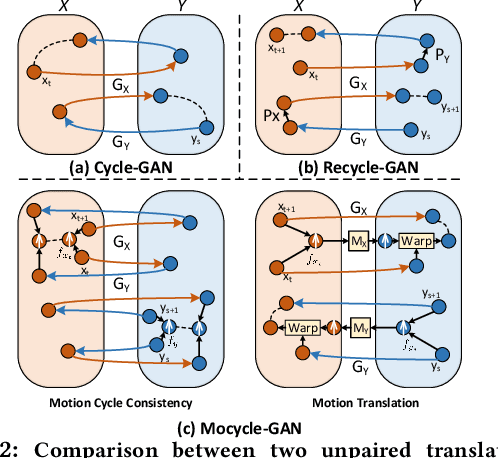
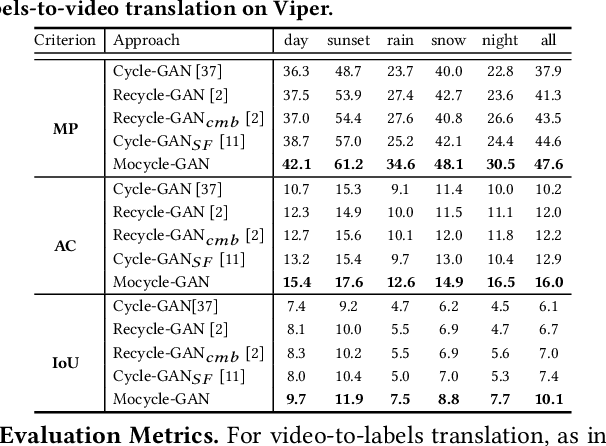
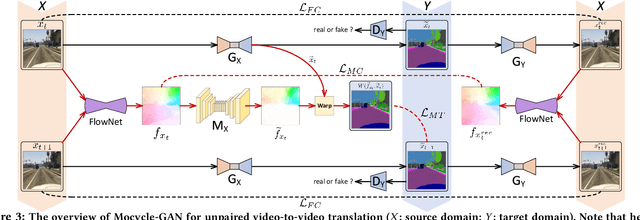
Unsupervised image-to-image translation is the task of translating an image from one domain to another in the absence of any paired training examples and tends to be more applicable to practical applications. Nevertheless, the extension of such synthesis from image-to-image to video-to-video is not trivial especially when capturing spatio-temporal structures in videos. The difficulty originates from the aspect that not only the visual appearance in each frame but also motion between consecutive frames should be realistic and consistent across transformation. This motivates us to explore both appearance structure and temporal continuity in video synthesis. In this paper, we present a new Motion-guided Cycle GAN, dubbed as Mocycle-GAN, that novelly integrates motion estimation into unpaired video translator. Technically, Mocycle-GAN capitalizes on three types of constrains: adversarial constraint discriminating between synthetic and real frame, cycle consistency encouraging an inverse translation on both frame and motion, and motion translation validating the transfer of motion between consecutive frames. Extensive experiments are conducted on video-to-labels and labels-to-video translation, and superior results are reported when comparing to state-of-the-art methods. More remarkably, we qualitatively demonstrate our Mocycle-GAN for both flower-to-flower and ambient condition transfer.
Relation Distillation Networks for Video Object Detection
Aug 26, 2019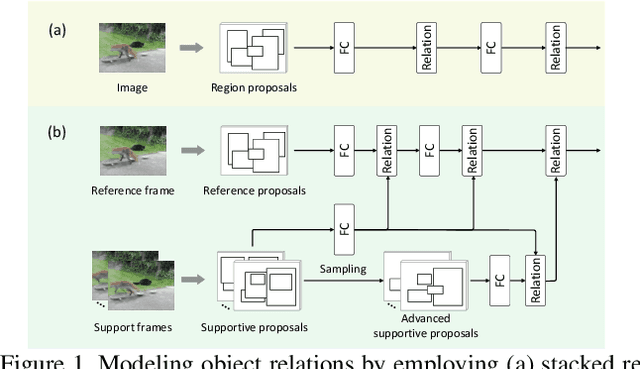

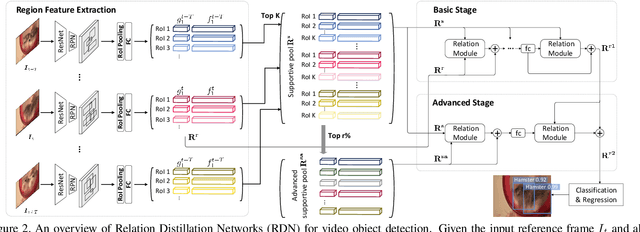
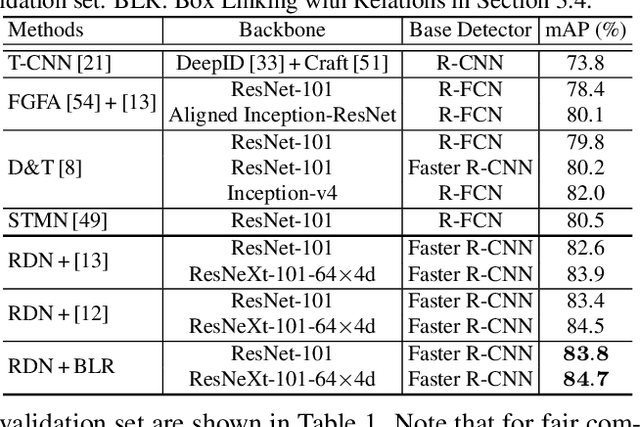
It has been well recognized that modeling object-to-object relations would be helpful for object detection. Nevertheless, the problem is not trivial especially when exploring the interactions between objects to boost video object detectors. The difficulty originates from the aspect that reliable object relations in a video should depend on not only the objects in the present frame but also all the supportive objects extracted over a long range span of the video. In this paper, we introduce a new design to capture the interactions across the objects in spatio-temporal context. Specifically, we present Relation Distillation Networks (RDN) --- a new architecture that novelly aggregates and propagates object relation to augment object features for detection. Technically, object proposals are first generated via Region Proposal Networks (RPN). RDN then, on one hand, models object relation via multi-stage reasoning, and on the other, progressively distills relation through refining supportive object proposals with high objectness scores in a cascaded manner. The learnt relation verifies the efficacy on both improving object detection in each frame and box linking across frames. Extensive experiments are conducted on ImageNet VID dataset, and superior results are reported when comparing to state-of-the-art methods. More remarkably, our RDN achieves 81.8% and 83.2% mAP with ResNet-101 and ResNeXt-101, respectively. When further equipped with linking and rescoring, we obtain to-date the best reported mAP of 83.8% and 84.7%.