 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Play Multi-Follower Bayesian Stackelberg Games
Oct 01, 2025In a multi-follower Bayesian Stackelberg game, a leader plays a mixed strategy over $L$ actions to which $n\ge 1$ followers, each having one of $K$ possible private types, best respond. The leader's optimal strategy depends on the distribution of the followers' private types. We study an online learning version of this problem: a leader interacts for $T$ rounds with $n$ followers with types sampled from an unknown distribution every round. The leader's goal is to minimize regret, defined as the difference between the cumulative utility of the optimal strategy and that of the actually chosen strategies. We design learning algorithms for the leader under different feedback settings. Under type feedback, where the leader observes the followers' types after each round, we design algorithms that achieve $\mathcal O\big(\sqrt{\min\{L\log(nKA T), nK \} \cdot T} \big)$ regret for independent type distributions and $\mathcal O\big(\sqrt{\min\{L\log(nKA T), K^n \} \cdot T} \big)$ regret for general type distributions. Interestingly, those bounds do not grow with $n$ at a polynomial rate. Under action feedback, where the leader only observes the followers' actions, we design algorithms with $\mathcal O( \min\{\sqrt{ n^L K^L A^{2L} L T \log T}, K^n\sqrt{ T } \log T \} )$ regret. We also provide a lower bound of $\Omega(\sqrt{\min\{L, nK\}T})$, almost matching the type-feedback upper bounds.
WOMAC: A Mechanism For Prediction Competitions
Aug 25, 2025Competitions are widely used to identify top performers in judgmental forecasting and machine learning, and the standard competition design ranks competitors based on their cumulative scores against a set of realized outcomes or held-out labels. However, this standard design is neither incentive-compatible nor very statistically efficient. The main culprit is noise in outcomes/labels that experts are scored against; it allows weaker competitors to often win by chance, and the winner-take-all nature incentivizes misreporting that improves win probability even if it decreases expected score. Attempts to achieve incentive-compatibility rely on randomized mechanisms that add even more noise in winner selection, but come at the cost of determinism and practical adoption. To tackle these issues, we introduce a novel deterministic mechanism: WOMAC (Wisdom of the Most Accurate Crowd). Instead of scoring experts against noisy outcomes, as is standard, WOMAC scores experts against the best ex-post aggregate of peer experts' predictions given the noisy outcomes. WOMAC is also more efficient than the standard competition design in typical settings. While the increased complexity of WOMAC makes it challenging to analyze incentives directly, we provide a clear theoretical foundation to justify the mechanism. We also provide an efficient vectorized implementation and demonstrate empirically on real-world forecasting datasets that WOMAC is a more reliable predictor of experts' out-of-sample performance relative to the standard mechanism. WOMAC is useful in any competition where there is substantial noise in the outcomes/labels.
Learning to Coordinate Bidders in Non-Truthful Auctions
Jul 03, 2025In non-truthful auctions such as first-price and all-pay auctions, the independent strategic behaviors of bidders, with the corresponding equilibrium notion -- Bayes Nash equilibria -- are notoriously difficult to characterize and can cause undesirable outcomes. An alternative approach to designing better auction systems is to coordinate the bidders: let a mediator make incentive-compatible recommendations of correlated bidding strategies to the bidders, namely, implementing a Bayes correlated equilibrium (BCE). The implementation of BCE, however, requires knowledge of the distribution of bidders' private valuations, which is often unavailable. We initiate the study of the sample complexity of learning Bayes correlated equilibria in non-truthful auctions. We prove that the BCEs in a large class of non-truthful auctions, including first-price and all-pay auctions, can be learned with a polynomial number $\tilde O(\frac{n}{\varepsilon^2})$ of samples from the bidders' value distributions. Our technique is a reduction to the problem of estimating bidders' expected utility from samples, combined with an analysis of the pseudo-dimension of the class of all monotone bidding strategies of bidders.
CPathAgent: An Agent-based Foundation Model for Interpretable High-Resolution Pathology Image Analysis Mimicking Pathologists' Diagnostic Logic
May 26, 2025Recent advances in computational pathology have led to the emergence of numerous foundation models. However, these approaches fail to replicate the diagnostic process of pathologists, as they either simply rely on general-purpose encoders with multi-instance learning for classification or directly apply multimodal models to generate reports from images. A significant limitation is their inability to emulate the diagnostic logic employed by pathologists, who systematically examine slides at low magnification for overview before progressively zooming in on suspicious regions to formulate comprehensive diagnoses. To address this gap, we introduce CPathAgent, an innovative agent-based model that mimics pathologists' reasoning processes by autonomously executing zoom-in/out and navigation operations across pathology images based on observed visual features. To achieve this, we develop a multi-stage training strategy unifying patch-level, region-level, and whole-slide capabilities within a single model, which is essential for mimicking pathologists, who require understanding and reasoning capabilities across all three scales. This approach generates substantially more detailed and interpretable diagnostic reports compared to existing methods, particularly for huge region understanding. Additionally, we construct an expert-validated PathMMU-HR$^{2}$, the first benchmark for huge region analysis, a critical intermediate scale between patches and whole slides, as diagnosticians typically examine several key regions rather than entire slides at once. Extensive experiments demonstrate that CPathAgent consistently outperforms existing approaches across three scales of benchmarks, validating the effectiveness of our agent-based diagnostic approach and highlighting a promising direction for the future development of computational pathology.
PiFlow: Principle-aware Scientific Discovery with Multi-Agent Collaboration
May 21, 2025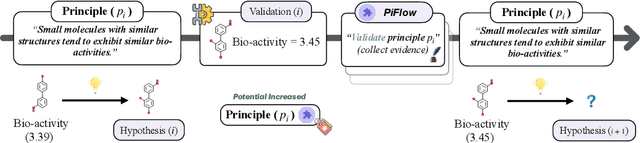
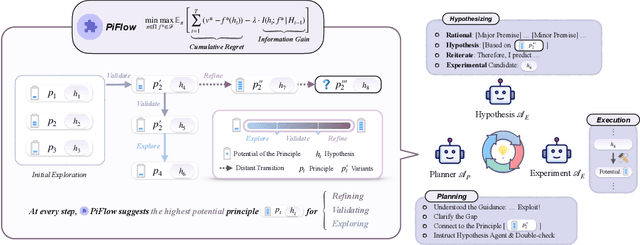

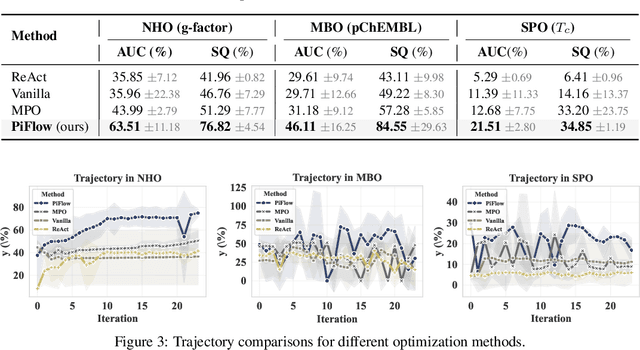
Large Language Model (LLM)-based multi-agent systems (MAS) demonstrate remarkable potential for scientific discovery. Existing approaches, however, often automate scientific discovery using predefined workflows that lack rationality constraints. This often leads to aimless hypothesizing and a failure to consistently link hypotheses with evidence, thereby hindering systematic uncertainty reduction. Overcoming these limitations fundamentally requires systematic uncertainty reduction. We introduce \texttt{PiFlow}, an information-theoretical framework, treating automated scientific discovery as a structured uncertainty reduction problem guided by principles (e.g., scientific laws). In evaluations across three distinct scientific domains -- discovering nanomaterial structures, bio-molecules, and superconductor candidates with targeted properties -- our method significantly improves discovery efficiency, reflected by a 73.55\% increase in the Area Under the Curve (AUC) of property values versus exploration steps, and enhances solution quality by 94.06\% compared to a vanilla agent system. Overall, \texttt{PiFlow} serves as a Plug-and-Play method, establishing a novel paradigm shift in highly efficient automated scientific discovery, paving the way for more robust and accelerated AI-driven research. Code is publicly available at our \href{https://github.com/amair-lab/PiFlow}{GitHub}.
Collaborative Unlabeled Data Optimization
May 20, 2025This paper pioneers a novel data-centric paradigm to maximize the utility of unlabeled data, tackling a critical question: How can we enhance the efficiency and sustainability of deep learning training by optimizing the data itself? We begin by identifying three key limitations in existing model-centric approaches, all rooted in a shared bottleneck: knowledge extracted from data is locked to model parameters, hindering its reusability and scalability. To this end, we propose CoOpt, a highly efficient, parallelized framework for collaborative unlabeled data optimization, thereby effectively encoding knowledge into the data itself. By distributing unlabeled data and leveraging publicly available task-agnostic models, CoOpt facilitates scalable, reusable, and sustainable training pipelines. Extensive experiments across diverse datasets and architectures demonstrate its efficacy and efficiency, achieving 13.6% and 6.8% improvements on Tiny-ImageNet and ImageNet-1K, respectively, with training speedups of $1.94 \times $ and $1.2 \times$.
Unified Continuous Generative Models
May 12, 2025Recent advances in continuous generative models, including multi-step approaches like diffusion and flow-matching (typically requiring 8-1000 sampling steps) and few-step methods such as consistency models (typically 1-8 steps), have demonstrated impressive generative performance. However, existing work often treats these approaches as distinct paradigms, resulting in separate training and sampling methodologies. We introduce a unified framework for training, sampling, and analyzing these models. Our implementation, the Unified Continuous Generative Models Trainer and Sampler (UCGM-{T,S}), achieves state-of-the-art (SOTA) performance. For example, on ImageNet 256x256 using a 675M diffusion transformer, UCGM-T trains a multi-step model achieving 1.30 FID in 20 steps and a few-step model reaching 1.42 FID in just 2 steps. Additionally, applying UCGM-S to a pre-trained model (previously 1.26 FID at 250 steps) improves performance to 1.06 FID in only 40 steps. Code is available at: https://github.com/LINs-lab/UCGM.
Efficient Generative Model Training via Embedded Representation Warmup
Apr 14, 2025



Diffusion models excel at generating high-dimensional data but fall short in training efficiency and representation quality compared to self-supervised methods. We identify a key bottleneck: the underutilization of high-quality, semantically rich representations during training notably slows down convergence. Our systematic analysis reveals a critical representation processing region -- primarily in the early layers -- where semantic and structural pattern learning takes place before generation can occur. To address this, we propose Embedded Representation Warmup (ERW), a plug-and-play framework where in the first stage we get the ERW module serves as a warmup that initializes the early layers of the diffusion model with high-quality, pretrained representations. This warmup minimizes the burden of learning representations from scratch, thereby accelerating convergence and boosting performance. Our theoretical analysis demonstrates that ERW's efficacy depends on its precise integration into specific neural network layers -- termed the representation processing region -- where the model primarily processes and transforms feature representations for later generation. We further establish that ERW not only accelerates training convergence but also enhances representation quality: empirically, our method achieves a 40$\times$ acceleration in training speed compared to REPA, the current state-of-the-art methods. Code is available at https://github.com/LINs-lab/ERW.
FASR-Net: Unsupervised Shadow Removal Leveraging Inherent Frequency Priors
Apr 08, 2025Shadow removal is challenging due to the complex interaction of geometry, lighting, and environmental factors. Existing unsupervised methods often overlook shadow-specific priors, leading to incomplete shadow recovery. To address this issue, we propose a novel unsupervised Frequency Aware Shadow Removal Network (FASR-Net), which leverages the inherent frequency characteristics of shadow regions. Specifically, the proposed Wavelet Attention Downsampling Module (WADM) integrates wavelet-based image decomposition and deformable attention, effectively breaking down the image into frequency components to enhance shadow details within specific frequency bands. We also introduce several new loss functions for precise shadow-free image reproduction: a frequency loss to capture image component details, a brightness-chromaticity loss that references the chromaticity of shadow-free regions, and an alignment loss to ensure smooth transitions between shadowed and shadow-free regions. Experimental results on the AISTD and SRD datasets demonstrate that our method achieves superior shadow removal performance.
STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?
Mar 31, 2025
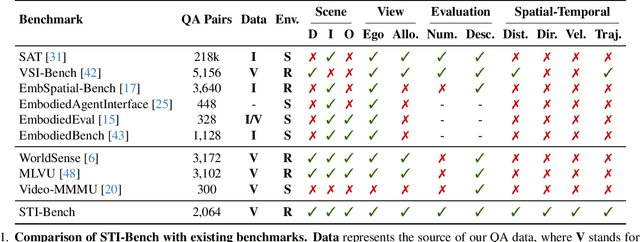

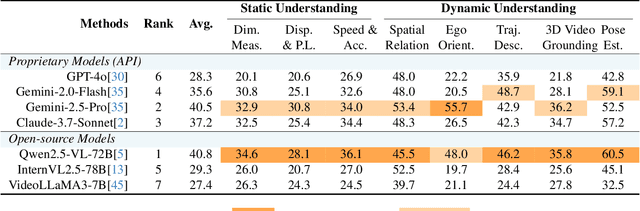
The use of Multimodal Large Language Models (MLLMs) as an end-to-end solution for Embodied AI and Autonomous Driving has become a prevailing trend. While MLLMs have been extensively studied for visual semantic understanding tasks, their ability to perform precise and quantitative spatial-temporal understanding in real-world applications remains largely unexamined, leading to uncertain prospects. To evaluate models' Spatial-Temporal Intelligence, we introduce STI-Bench, a benchmark designed to evaluate MLLMs' spatial-temporal understanding through challenging tasks such as estimating and predicting the appearance, pose, displacement, and motion of objects. Our benchmark encompasses a wide range of robot and vehicle operations across desktop, indoor, and outdoor scenarios. The extensive experiments reveals that the state-of-the-art MLLMs still struggle in real-world spatial-temporal understanding, especially in tasks requiring precise distance estimation and motion analysis.