 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDM-ASR: Bridging Accuracy and Efficiency in ASR with Diffusion-Based Non-Autoregressive Decoding
Feb 24, 2026In sequence-to-sequence Transformer ASR, autoregressive (AR) models achieve strong accuracy but suffer from slow decoding, while non-autoregressive (NAR) models enable parallel decoding at the cost of degraded performance. We propose a principled NAR ASR framework based on Masked Diffusion Models to reduce this gap. A pre-trained speech encoder is coupled with a Transformer diffusion decoder conditioned on acoustic features and partially masked transcripts for parallel token prediction. To mitigate the training-inference mismatch, we introduce Iterative Self-Correction Training that exposes the model to its own intermediate predictions. We also design a Position-Biased Entropy-Bounded Confidence-based sampler with positional bias to further boost results. Experiments across multiple benchmarks demonstrate consistent gains over prior NAR models and competitive performance with strong AR baselines, while retaining parallel decoding efficiency.
A Bottom-up Framework with Language-universal Speech Attribute Modeling for Syllable-based ASR
Sep 09, 2025We propose a bottom-up framework for automatic speech recognition (ASR) in syllable-based languages by unifying language-universal articulatory attribute modeling with syllable-level prediction. The system first recognizes sequences or lattices of articulatory attributes that serve as a language-universal, interpretable representation of pronunciation, and then transforms them into syllables through a structured knowledge integration process. We introduce two evaluation metrics, namely Pronunciation Error Rate (PrER) and Syllable Homonym Error Rate (SHER), to evaluate the model's ability to capture pronunciation and handle syllable ambiguities. Experimental results on the AISHELL-1 Mandarin corpus demonstrate that the proposed bottom-up framework achieves competitive performance and exhibits better robustness under low-resource conditions compared to the direct syllable prediction model. Furthermore, we investigate the zero-shot cross-lingual transferability on Japanese and demonstrate significant improvements over character- and phoneme-based baselines by 40% error rate reduction.
An Investigation on Combining Geometry and Consistency Constraints into Phase Estimation for Speech Enhancement
Jul 02, 2025



We propose a novel iterative phase estimation framework, termed multi-source Griffin-Lim algorithm (MSGLA), for speech enhancement (SE) under additive noise conditions. The core idea is to leverage the ad-hoc consistency constraint of complex-valued short-time Fourier transform (STFT) spectrograms to address the sign ambiguity challenge commonly encountered in geometry-based phase estimation. Furthermore, we introduce a variant of the geometric constraint framework based on the law of sines and cosines, formulating a new phase reconstruction algorithm using noise phase estimates. We first validate the proposed technique through a series of oracle experiments, demonstrating its effectiveness under ideal conditions. We then evaluate its performance on the VB-DMD and WSJ0-CHiME3 data sets, and show that the proposed MSGLA variants match well or slightly outperform existing algorithms, including direct phase estimation and DNN-based sign prediction, especially in terms of background noise suppression.
Generative Speech Foundation Model Pretraining for High-Quality Speech Extraction and Restoration
Sep 25, 2024



This paper proposes a generative pretraining foundation model for high-quality speech restoration tasks. By directly operating on complex-valued short-time Fourier transform coefficients, our model does not rely on any vocoders for time-domain signal reconstruction. As a result, our model simplifies the synthesis process and removes the quality upper-bound introduced by any mel-spectrogram vocoder compared to prior work SpeechFlow. The proposed method is evaluated on multiple speech restoration tasks, including speech denoising, bandwidth extension, codec artifact removal, and target speaker extraction. In all scenarios, finetuning our pretrained model results in superior performance over strong baselines. Notably, in the target speaker extraction task, our model outperforms existing systems, including those leveraging SSL-pretrained encoders like WavLM. The code and the pretrained checkpoints are publicly available in the NVIDIA NeMo framework.
An Explicit Consistency-Preserving Loss Function for Phase Reconstruction and Speech Enhancement
Sep 24, 2024



In this work, we propose a novel consistency-preserving loss function for recovering the phase information in the context of phase reconstruction (PR) and speech enhancement (SE). Different from conventional techniques that directly estimate the phase using a deep model, our idea is to exploit ad-hoc constraints to directly generate a consistent pair of magnitude and phase. Specifically, the proposed loss forces a set of complex numbers to be a consistent short-time Fourier transform (STFT) representation, i.e., to be the spectrogram of a real signal. Our approach thus avoids the difficulty of estimating the original phase, which is highly unstructured and sensitive to time shift. The influence of our proposed loss is first assessed on a PR task, experimentally demonstrating that our approach is viable. Next, we show its effectiveness on an SE task, using both the VB-DMD and WSJ0-CHiME3 data sets. On VB-DMD, our approach is competitive with conventional solutions. On the challenging WSJ0-CHiME3 set, the proposed framework compares favourably over those techniques that explicitly estimate the phase.
Language-Universal Speech Attributes Modeling for Zero-Shot Multilingual Spoken Keyword Recognition
Jun 04, 2024



We propose a novel language-universal approach to end-to-end automatic spoken keyword recognition (SKR) leveraging upon (i) a self-supervised pre-trained model, and (ii) a set of universal speech attributes (manner and place of articulation). Specifically, Wav2Vec2.0 is used to generate robust speech representations, followed by a linear output layer to produce attribute sequences. A non-trainable pronunciation model then maps sequences of attributes into spoken keywords in a multilingual setting. Experiments on the Multilingual Spoken Words Corpus show comparable performances to character- and phoneme-based SKR in seen languages. The inclusion of domain adversarial training (DAT) improves the proposed framework, outperforming both character- and phoneme-based SKR approaches with 13.73% and 17.22% relative word error rate (WER) reduction in seen languages, and achieves 32.14% and 19.92% WER reduction for unseen languages in zero-shot settings.
A Multi-dimensional Deep Structured State Space Approach to Speech Enhancement Using Small-footprint Models
Jun 01, 2023



We propose a multi-dimensional structured state space (S4) approach to speech enhancement. To better capture the spectral dependencies across the frequency axis, we focus on modifying the multi-dimensional S4 layer with whitening transformation to build new small-footprint models that also achieve good performance. We explore several S4-based deep architectures in time (T) and time-frequency (TF) domains. The 2-D S4 layer can be considered a particular convolutional layer with an infinite receptive field although it utilizes fewer parameters than a conventional convolutional layer. Evaluated on the VoiceBank-DEMAND data set, when compared with the conventional U-net model based on convolutional layers, the proposed TF-domain S4-based model is 78.6% smaller in size, yet it still achieves competitive results with a PESQ score of 3.15 with data augmentation. By increasing the model size, we can even reach a PESQ score of 3.18.
A Neural State-Space Model Approach to Efficient Speech Separation
May 26, 2023



In this work, we introduce S4M, a new efficient speech separation framework based on neural state-space models (SSM). Motivated by linear time-invariant systems for sequence modeling, our SSM-based approach can efficiently model input signals into a format of linear ordinary differential equations (ODEs) for representation learning. To extend the SSM technique into speech separation tasks, we first decompose the input mixture into multi-scale representations with different resolutions. This mechanism enables S4M to learn globally coherent separation and reconstruction. The experimental results show that S4M performs comparably to other separation backbones in terms of SI-SDRi, while having a much lower model complexity with significantly fewer trainable parameters. In addition, our S4M-tiny model (1.8M parameters) even surpasses attention-based Sepformer (26.0M parameters) in noisy conditions with only 9.2 of multiply-accumulate operation (MACs).
A Study of Low-Resource Speech Commands Recognition based on Adversarial Reprogramming
Oct 08, 2021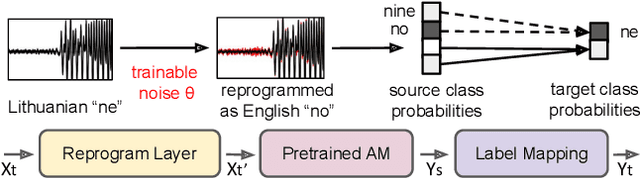
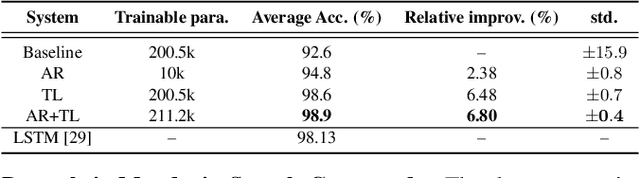
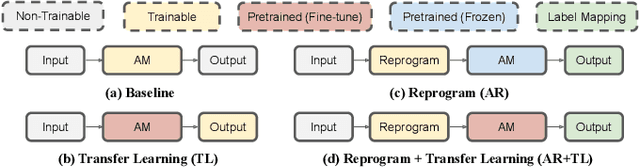
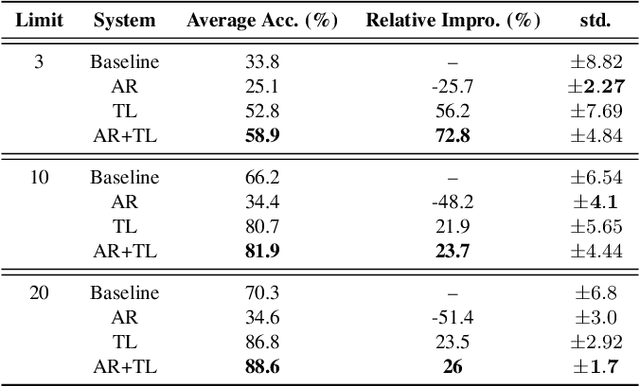
In this study, we propose a novel adversarial reprogramming (AR) approach for low-resource spoken command recognition (SCR), and build an AR-SCR system. The AR procedure aims to modify the acoustic signals (from the target domain) to repurpose a pretrained SCR model (from the source domain). To solve the label mismatches between source and target domains, and further improve the stability of AR, we propose a novel similarity-based label mapping technique to align classes. In addition, the transfer learning (TL) technique is combined with the original AR process to improve the model adaptation capability. We evaluate the proposed AR-SCR system on three low-resource SCR datasets, including Arabic, Lithuanian, and dysarthric Mandarin speech. Experimental results show that with a pretrained AM trained on a large-scale English dataset, the proposed AR-SCR system outperforms the current state-of-the-art results on Arabic and Lithuanian speech commands datasets, with only a limited amount of training data.
The AS-NU System for the M2VoC Challenge
Apr 07, 2021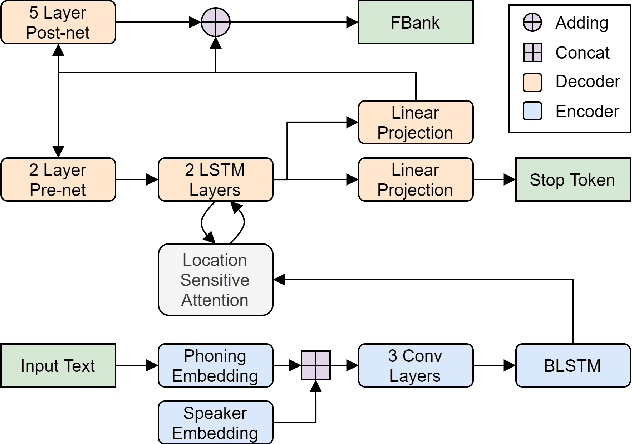
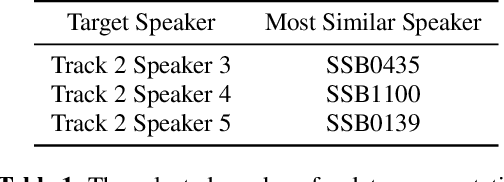
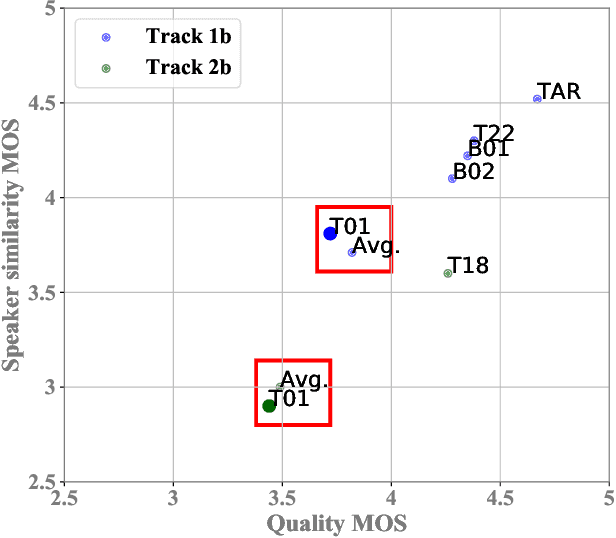
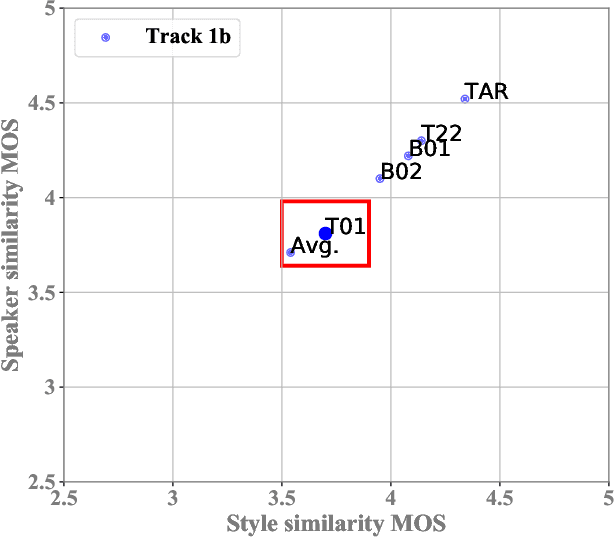
This paper describes the AS-NU systems for two tracks in MultiSpeaker Multi-Style Voice Cloning Challenge (M2VoC). The first track focuses on using a small number of 100 target utterances for voice cloning, while the second track focuses on using only 5 target utterances for voice cloning. Due to the serious lack of data in the second track, we selected the speaker most similar to the target speaker from the training data of the TTS system, and used the speaker's utterances and the given 5 target utterances to fine-tune our model. The evaluation results show that our systems on the two tracks perform similarly in terms of quality, but there is still a clear gap between the similarity score of the second track and the similarity score of the first track.