 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Discovering Multi-Hardware Mobile Models via Architecture Search
Aug 18, 2020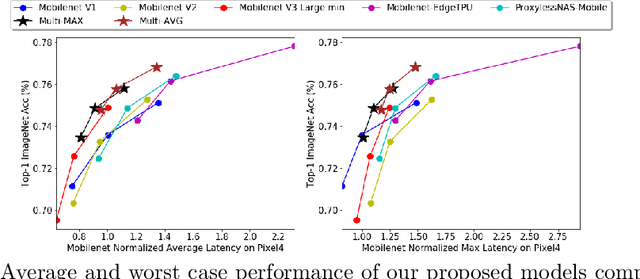

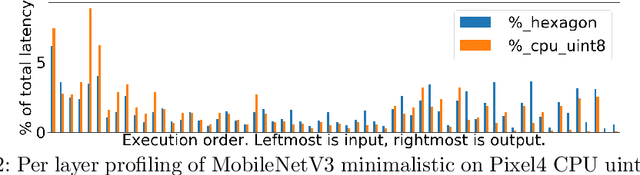
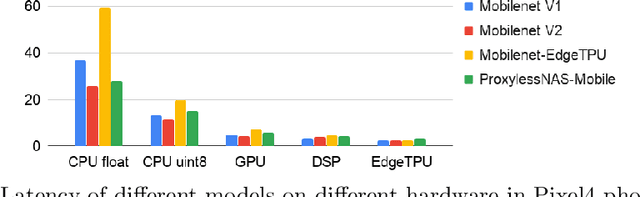
Developing efficient models for mobile phones or other on-device deployments has been a popular topic in both industry and academia. In such scenarios, it is often convenient to deploy the same model on a diverse set of hardware devices owned by different end users to minimize the costs of development, deployment and maintenance. Despite the importance, designing a single neural network that can perform well on multiple devices is difficult as each device has its own specialty and restrictions: A model optimized for one device may not perform well on another. While most existing work proposes different models optimized for each single hardware, this paper is the first which explores the problem of finding a single model that performs well on multiple hardware. Specifically, we leverage architecture search to help us find the best model, where given a set of diverse hardware to optimize for, we first introduce a multi-hardware search space that is compatible with all examined hardware. Then, to measure the performance of a neural network over multiple hardware, we propose metrics that can characterize the overall latency performance in an average case and worst case scenario. With the multi-hardware search space and new metrics applied to Pixel4 CPU, GPU, DSP and EdgeTPU, we found models that perform on par or better than state-of-the-art (SOTA) models on each of our target accelerators and generalize well on many un-targeted hardware. Comparing with single-hardware searches, multi-hardware search gives a better trade-off between computation cost and model performance.
MobileDets: Searching for Object Detection Architectures for Mobile Accelerators
Apr 30, 2020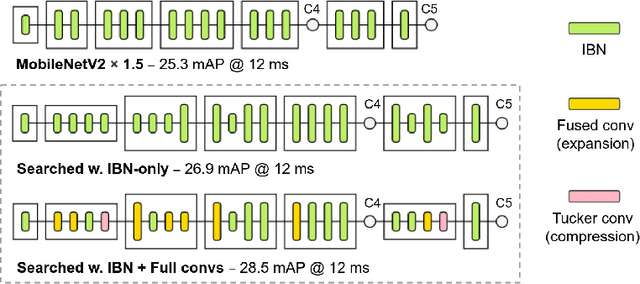
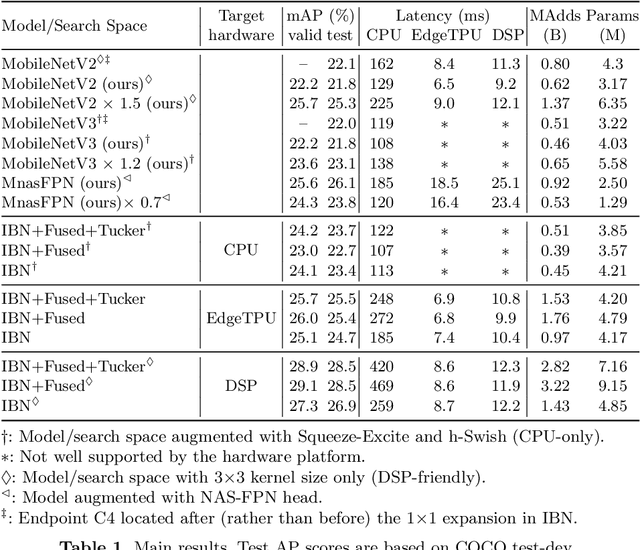
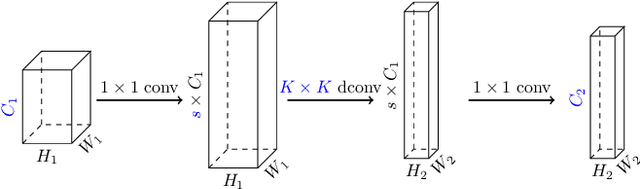
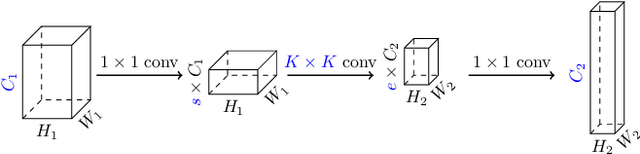
Inverted bottleneck layers, which are built upon depthwise convolutions, have been the predominant building blocks in state-of-the-art object detection models on mobile devices. In this work, we question the optimality of this design pattern over a broad range of mobile accelerators by revisiting the usefulness of regular convolutions. We achieve substantial improvements in the latency-accuracy trade-off by incorporating regular convolutions in the search space, and effectively placing them in the network via neural architecture search. We obtain a family of object detection models, MobileDets, that achieve state-of-the-art results across mobile accelerators. On the COCO object detection task, MobileDets outperform MobileNetV3+SSDLite by 1.7 mAP at comparable mobile CPU inference latencies. MobileDets also outperform MobileNetV2+SSDLite by 1.9 mAP on mobile CPUs, 3.7 mAP on EdgeTPUs and 3.4 mAP on DSPs while running equally fast. Moreover, MobileDets are comparable with the state-of-the-art MnasFPN on mobile CPUs even without using the feature pyramid, and achieve better mAP scores on both EdgeTPUs and DSPs with up to 2X speedup.
Accelerator-aware Neural Network Design using AutoML
Mar 05, 2020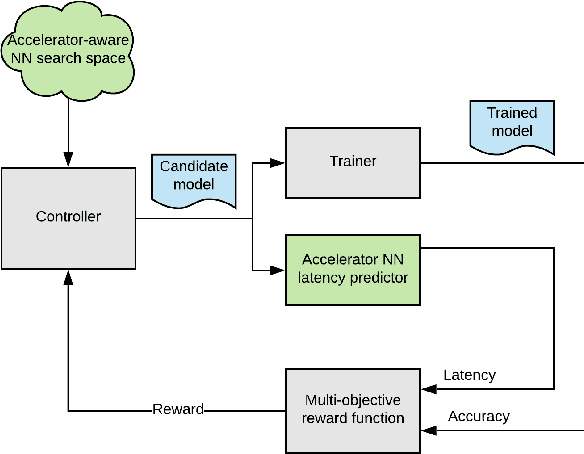
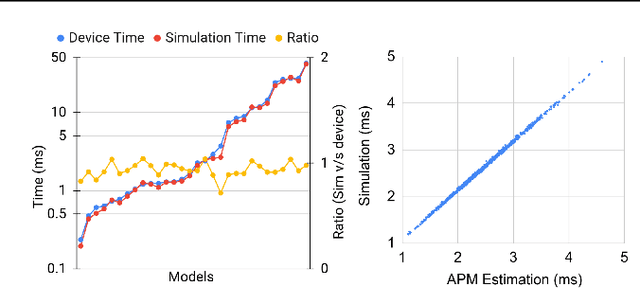
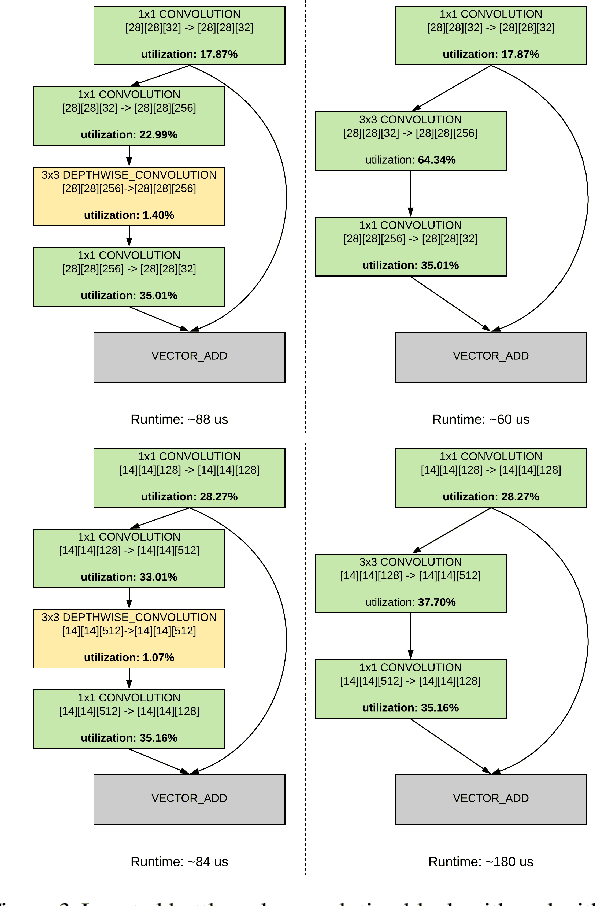
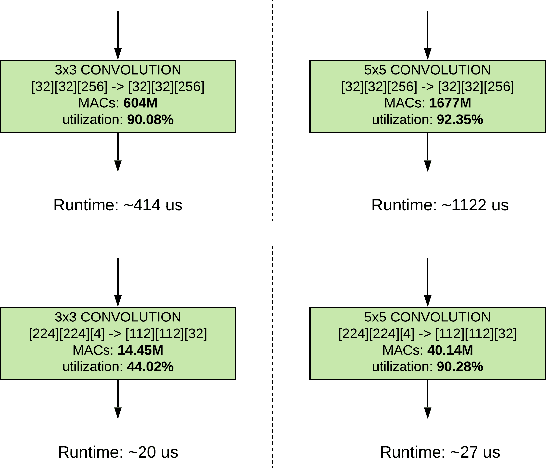
While neural network hardware accelerators provide a substantial amount of raw compute throughput, the models deployed on them must be co-designed for the underlying hardware architecture to obtain the optimal system performance. We present a class of computer vision models designed using hardware-aware neural architecture search and customized to run on the Edge TPU, Google's neural network hardware accelerator for low-power, edge devices. For the Edge TPU in Coral devices, these models enable real-time image classification performance while achieving accuracy typically seen only with larger, compute-heavy models running in data centers. On Pixel 4's Edge TPU, these models improve the accuracy-latency tradeoff over existing SoTA mobile models.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
To prune, or not to prune: exploring the efficacy of pruning for model compression
Nov 13, 2017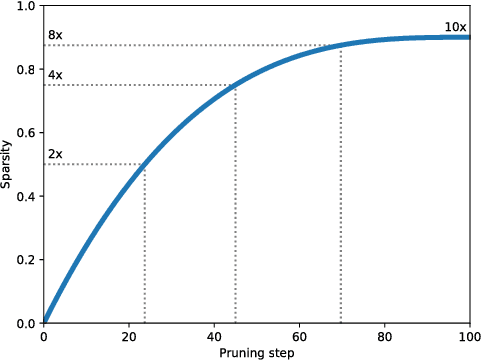
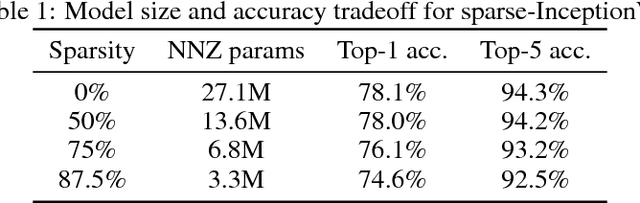
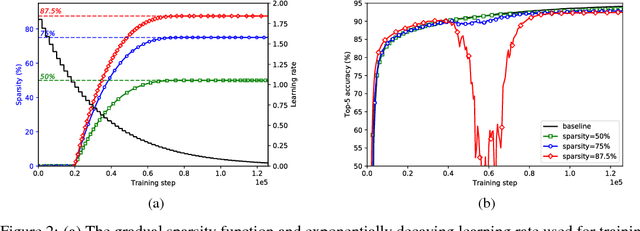
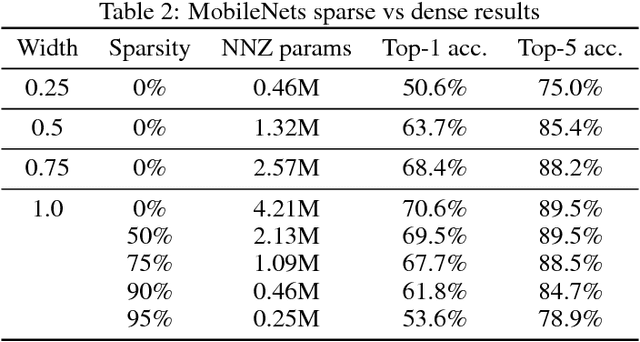
Model pruning seeks to induce sparsity in a deep neural network's various connection matrices, thereby reducing the number of nonzero-valued parameters in the model. Recent reports (Han et al., 2015; Narang et al., 2017) prune deep networks at the cost of only a marginal loss in accuracy and achieve a sizable reduction in model size. This hints at the possibility that the baseline models in these experiments are perhaps severely over-parameterized at the outset and a viable alternative for model compression might be to simply reduce the number of hidden units while maintaining the model's dense connection structure, exposing a similar trade-off in model size and accuracy. We investigate these two distinct paths for model compression within the context of energy-efficient inference in resource-constrained environments and propose a new gradual pruning technique that is simple and straightforward to apply across a variety of models/datasets with minimal tuning and can be seamlessly incorporated within the training process. We compare the accuracy of large, but pruned models (large-sparse) and their smaller, but dense (small-dense) counterparts with identical memory footprint. Across a broad range of neural network architectures (deep CNNs, stacked LSTM, and seq2seq LSTM models), we find large-sparse models to consistently outperform small-dense models and achieve up to 10x reduction in number of non-zero parameters with minimal loss in accuracy.
Model Accuracy and Runtime Tradeoff in Distributed Deep Learning:A Systematic Study
Dec 05, 2016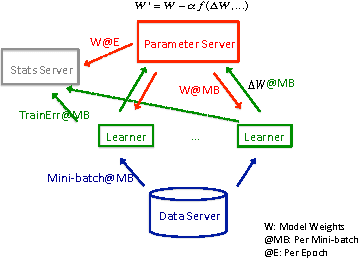
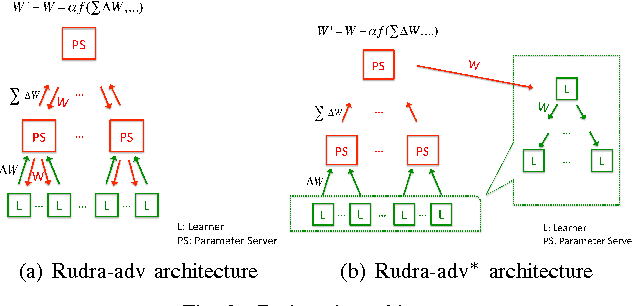
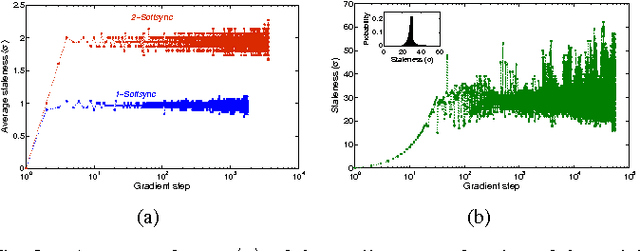
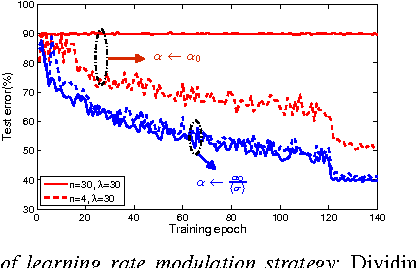
This paper presents Rudra, a parameter server based distributed computing framework tuned for training large-scale deep neural networks. Using variants of the asynchronous stochastic gradient descent algorithm we study the impact of synchronization protocol, stale gradient updates, minibatch size, learning rates, and number of learners on runtime performance and model accuracy. We introduce a new learning rate modulation strategy to counter the effect of stale gradients and propose a new synchronization protocol that can effectively bound the staleness in gradients, improve runtime performance and achieve good model accuracy. Our empirical investigation reveals a principled approach for distributed training of neural networks: the mini-batch size per learner should be reduced as more learners are added to the system to preserve the model accuracy. We validate this approach using commonly-used image classification benchmarks: CIFAR10 and ImageNet.
Staleness-aware Async-SGD for Distributed Deep Learning
Apr 05, 2016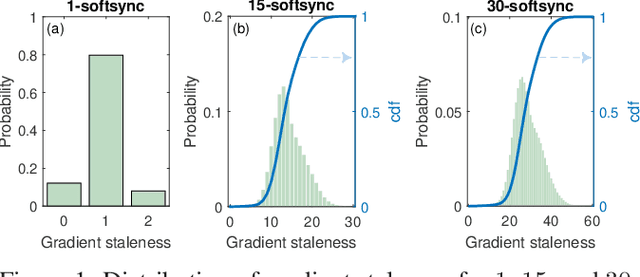
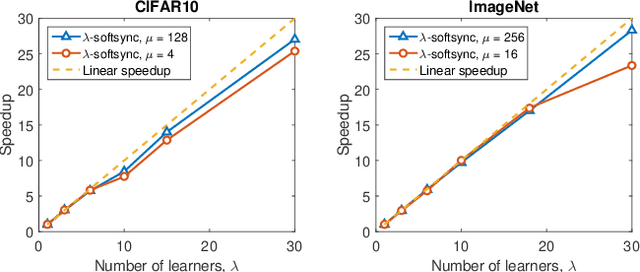
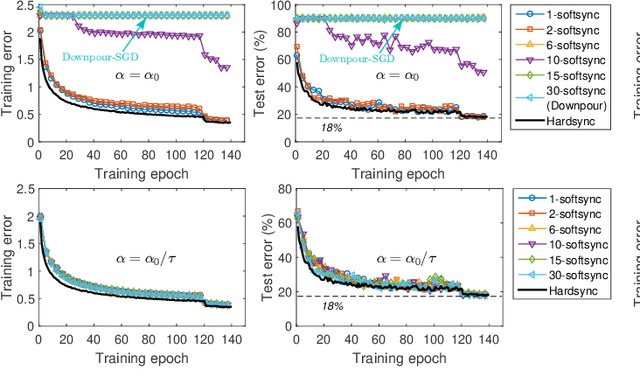
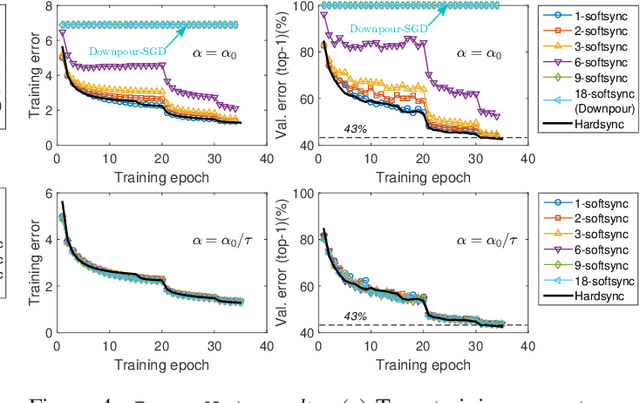
Deep neural networks have been shown to achieve state-of-the-art performance in several machine learning tasks. Stochastic Gradient Descent (SGD) is the preferred optimization algorithm for training these networks and asynchronous SGD (ASGD) has been widely adopted for accelerating the training of large-scale deep networks in a distributed computing environment. However, in practice it is quite challenging to tune the training hyperparameters (such as learning rate) when using ASGD so as achieve convergence and linear speedup, since the stability of the optimization algorithm is strongly influenced by the asynchronous nature of parameter updates. In this paper, we propose a variant of the ASGD algorithm in which the learning rate is modulated according to the gradient staleness and provide theoretical guarantees for convergence of this algorithm. Experimental verification is performed on commonly-used image classification benchmarks: CIFAR10 and Imagenet to demonstrate the superior effectiveness of the proposed approach, compared to SSGD (Synchronous SGD) and the conventional ASGD algorithm.
Deep Learning with Limited Numerical Precision
Feb 09, 2015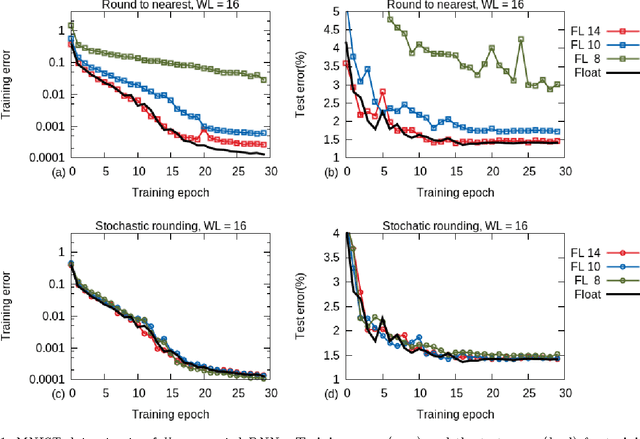
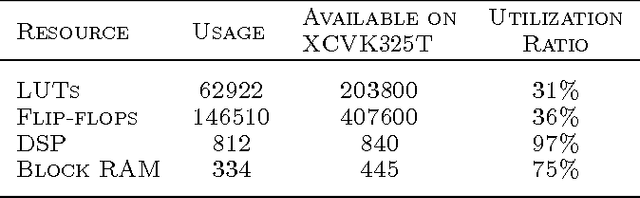
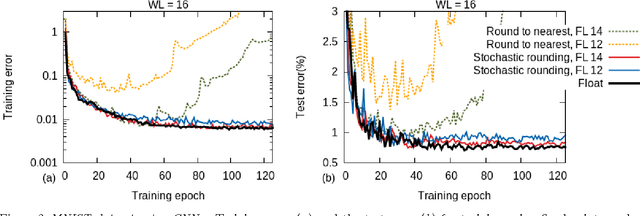
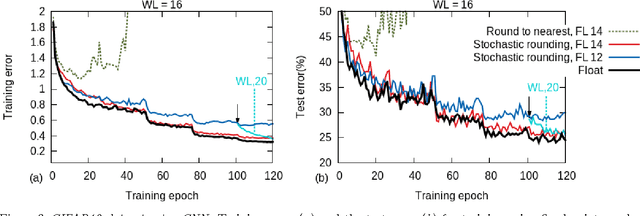
Training of large-scale deep neural networks is often constrained by the available computational resources. We study the effect of limited precision data representation and computation on neural network training. Within the context of low-precision fixed-point computations, we observe the rounding scheme to play a crucial role in determining the network's behavior during training. Our results show that deep networks can be trained using only 16-bit wide fixed-point number representation when using stochastic rounding, and incur little to no degradation in the classification accuracy. We also demonstrate an energy-efficient hardware accelerator that implements low-precision fixed-point arithmetic with stochastic rounding.