 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning Approaches for Building Cross-Language Dense Retrieval Models
Jan 20, 2022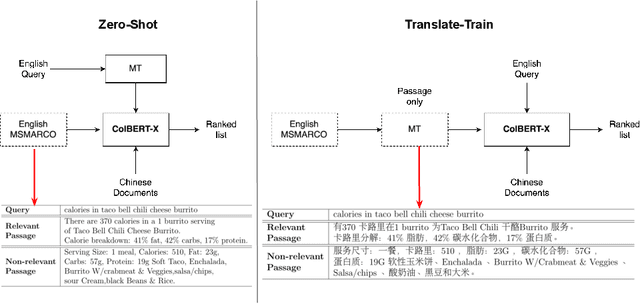
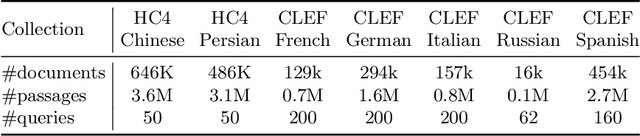
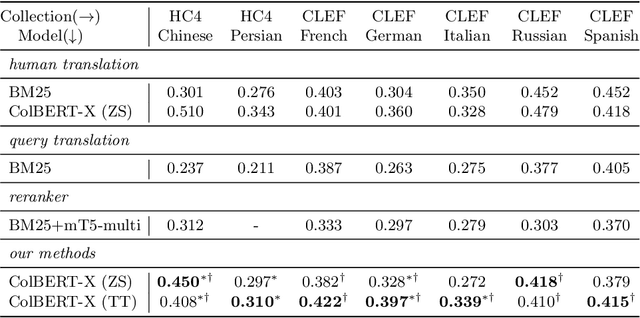
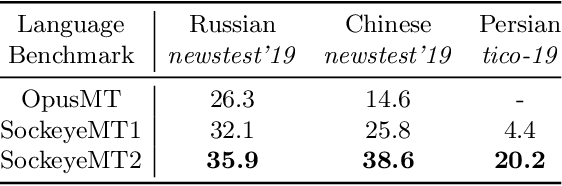
The advent of transformer-based models such as BERT has led to the rise of neural ranking models. These models have improved the effectiveness of retrieval systems well beyond that of lexical term matching models such as BM25. While monolingual retrieval tasks have benefited from large-scale training collections such as MS MARCO and advances in neural architectures, cross-language retrieval tasks have fallen behind these advancements. This paper introduces ColBERT-X, a generalization of the ColBERT multi-representation dense retrieval model that uses the XLM-RoBERTa (XLM-R) encoder to support cross-language information retrieval (CLIR). ColBERT-X can be trained in two ways. In zero-shot training, the system is trained on the English MS MARCO collection, relying on the XLM-R encoder for cross-language mappings. In translate-train, the system is trained on the MS MARCO English queries coupled with machine translations of the associated MS MARCO passages. Results on ad hoc document ranking tasks in several languages demonstrate substantial and statistically significant improvements of these trained dense retrieval models over traditional lexical CLIR baselines.
MESA: Offline Meta-RL for Safe Adaptation and Fault Tolerance
Dec 07, 2021
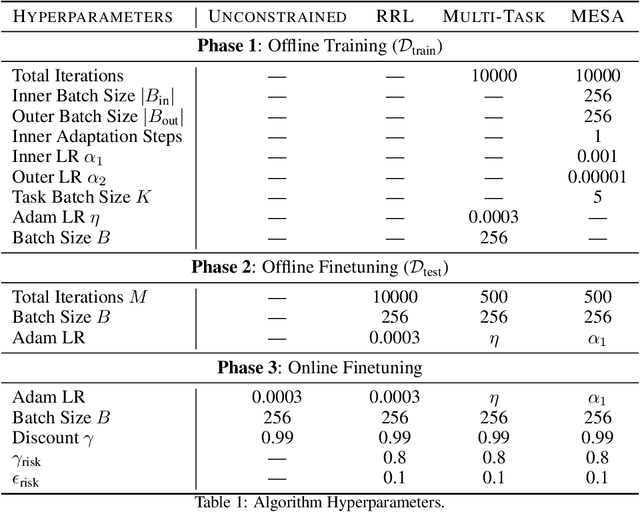
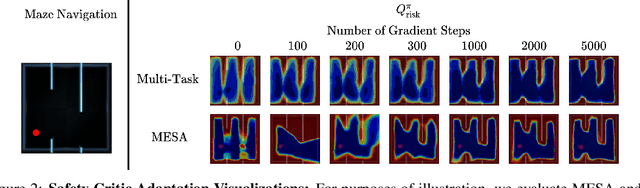

Safe exploration is critical for using reinforcement learning (RL) in risk-sensitive environments. Recent work learns risk measures which measure the probability of violating constraints, which can then be used to enable safety. However, learning such risk measures requires significant interaction with the environment, resulting in excessive constraint violations during learning. Furthermore, these measures are not easily transferable to new environments. We cast safe exploration as an offline meta-RL problem, where the objective is to leverage examples of safe and unsafe behavior across a range of environments to quickly adapt learned risk measures to a new environment with previously unseen dynamics. We then propose MEta-learning for Safe Adaptation (MESA), an approach for meta-learning a risk measure for safe RL. Simulation experiments across 5 continuous control domains suggest that MESA can leverage offline data from a range of different environments to reduce constraint violations in unseen environments by up to a factor of 2 while maintaining task performance. See https://tinyurl.com/safe-meta-rl for code and supplementary material.
Cross-language Information Retrieval
Nov 10, 2021Two key assumptions shape the usual view of ranked retrieval: (1) that the searcher can choose words for their query that might appear in the documents that they wish to see, and (2) that ranking retrieved documents will suffice because the searcher will be able to recognize those which they wished to find. When the documents to be searched are in a language not known by the searcher, neither assumption is true. In such cases, Cross-Language Information Retrieval (CLIR) is needed. This chapter reviews the state of the art for cross-language information retrieval and outlines some open research questions.
Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks
Sep 21, 2021
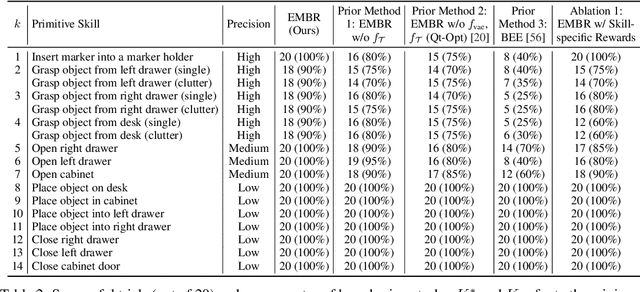
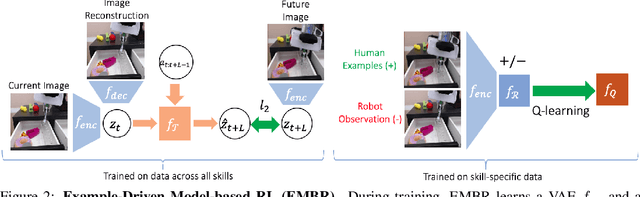

In this paper, we study the problem of learning a repertoire of low-level skills from raw images that can be sequenced to complete long-horizon visuomotor tasks. Reinforcement learning (RL) is a promising approach for acquiring short-horizon skills autonomously. However, the focus of RL algorithms has largely been on the success of those individual skills, more so than learning and grounding a large repertoire of skills that can be sequenced to complete extended multi-stage tasks. The latter demands robustness and persistence, as errors in skills can compound over time, and may require the robot to have a number of primitive skills in its repertoire, rather than just one. To this end, we introduce EMBR, a model-based RL method for learning primitive skills that are suitable for completing long-horizon visuomotor tasks. EMBR learns and plans using a learned model, critic, and success classifier, where the success classifier serves both as a reward function for RL and as a grounding mechanism to continuously detect if the robot should retry a skill when unsuccessful or under perturbations. Further, the learned model is task-agnostic and trained using data from all skills, enabling the robot to efficiently learn a number of distinct primitives. These visuomotor primitive skills and their associated pre- and post-conditions can then be directly combined with off-the-shelf symbolic planners to complete long-horizon tasks. On a Franka Emika robot arm, we find that EMBR enables the robot to complete three long-horizon visuomotor tasks at 85% success rate, such as organizing an office desk, a file cabinet, and drawers, which require sequencing up to 12 skills, involve 14 unique learned primitives, and demand generalization to novel objects.
Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation
Sep 02, 2021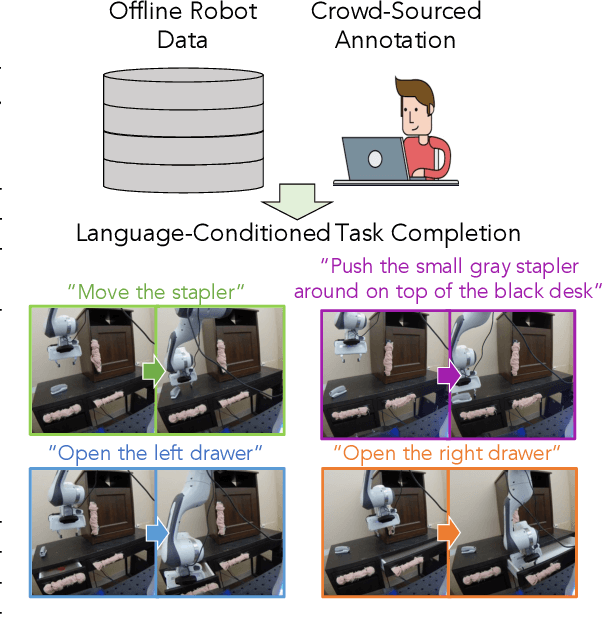
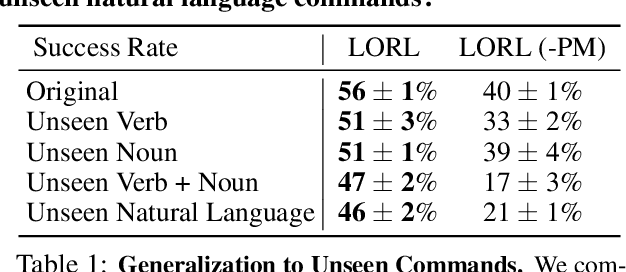
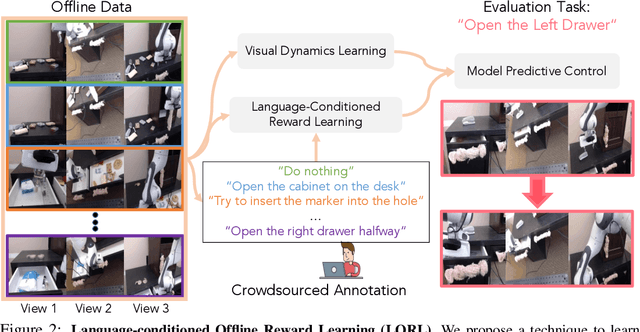

We study the problem of learning a range of vision-based manipulation tasks from a large offline dataset of robot interaction. In order to accomplish this, humans need easy and effective ways of specifying tasks to the robot. Goal images are one popular form of task specification, as they are already grounded in the robot's observation space. However, goal images also have a number of drawbacks: they are inconvenient for humans to provide, they can over-specify the desired behavior leading to a sparse reward signal, or under-specify task information in the case of non-goal reaching tasks. Natural language provides a convenient and flexible alternative for task specification, but comes with the challenge of grounding language in the robot's observation space. To scalably learn this grounding we propose to leverage offline robot datasets (including highly sub-optimal, autonomously collected data) with crowd-sourced natural language labels. With this data, we learn a simple classifier which predicts if a change in state completes a language instruction. This provides a language-conditioned reward function that can then be used for offline multi-task RL. In our experiments, we find that on language-conditioned manipulation tasks our approach outperforms both goal-image specifications and language conditioned imitation techniques by more than 25%, and is able to perform visuomotor tasks from natural language, such as "open the right drawer" and "move the stapler", on a Franka Emika Panda robot.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
FitVid: Overfitting in Pixel-Level Video Prediction
Jun 24, 2021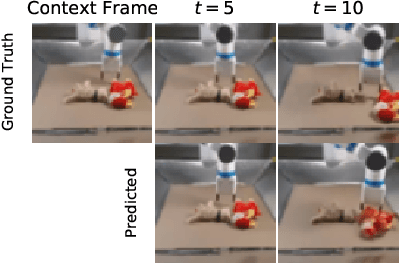

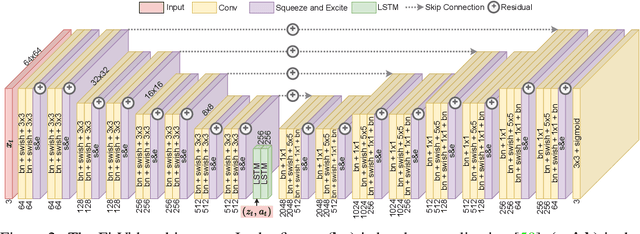

An agent that is capable of predicting what happens next can perform a variety of tasks through planning with no additional training. Furthermore, such an agent can internally represent the complex dynamics of the real-world and therefore can acquire a representation useful for a variety of visual perception tasks. This makes predicting the future frames of a video, conditioned on the observed past and potentially future actions, an interesting task which remains exceptionally challenging despite many recent advances. Existing video prediction models have shown promising results on simple narrow benchmarks but they generate low quality predictions on real-life datasets with more complicated dynamics or broader domain. There is a growing body of evidence that underfitting on the training data is one of the primary causes for the low quality predictions. In this paper, we argue that the inefficient use of parameters in the current video models is the main reason for underfitting. Therefore, we introduce a new architecture, named FitVid, which is capable of severe overfitting on the common benchmarks while having similar parameter count as the current state-of-the-art models. We analyze the consequences of overfitting, illustrating how it can produce unexpected outcomes such as generating high quality output by repeating the training data, and how it can be mitigated using existing image augmentation techniques. As a result, FitVid outperforms the current state-of-the-art models across four different video prediction benchmarks on four different metrics.
Cross-language Sentence Selection via Data Augmentation and Rationale Training
Jun 04, 2021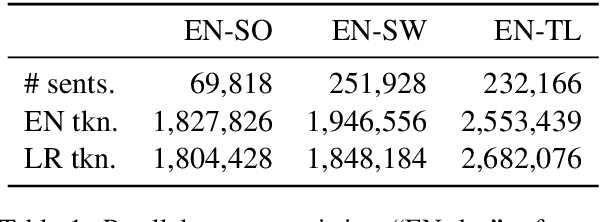
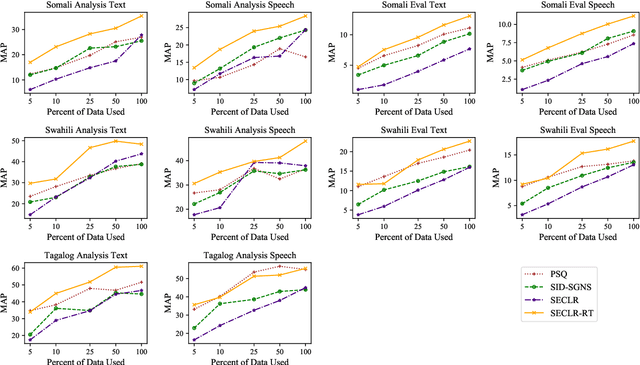
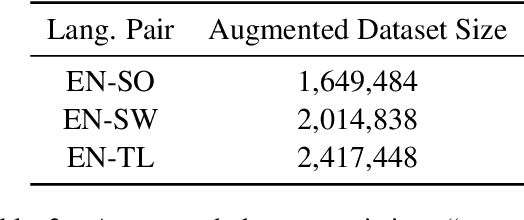
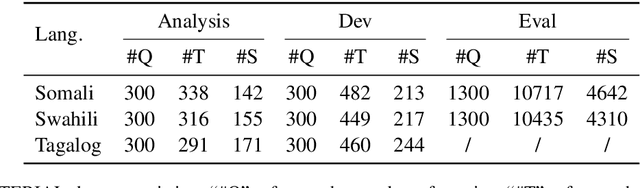
This paper proposes an approach to cross-language sentence selection in a low-resource setting. It uses data augmentation and negative sampling techniques on noisy parallel sentence data to directly learn a cross-lingual embedding-based query relevance model. Results show that this approach performs as well as or better than multiple state-of-the-art machine translation + monolingual retrieval systems trained on the same parallel data. Moreover, when a rationale training secondary objective is applied to encourage the model to match word alignment hints from a phrase-based statistical machine translation model, consistent improvements are seen across three language pairs (English-Somali, English-Swahili and English-Tagalog) over a variety of state-of-the-art baselines.
Learning Generalizable Robotic Reward Functions from "In-The-Wild" Human Videos
Mar 31, 2021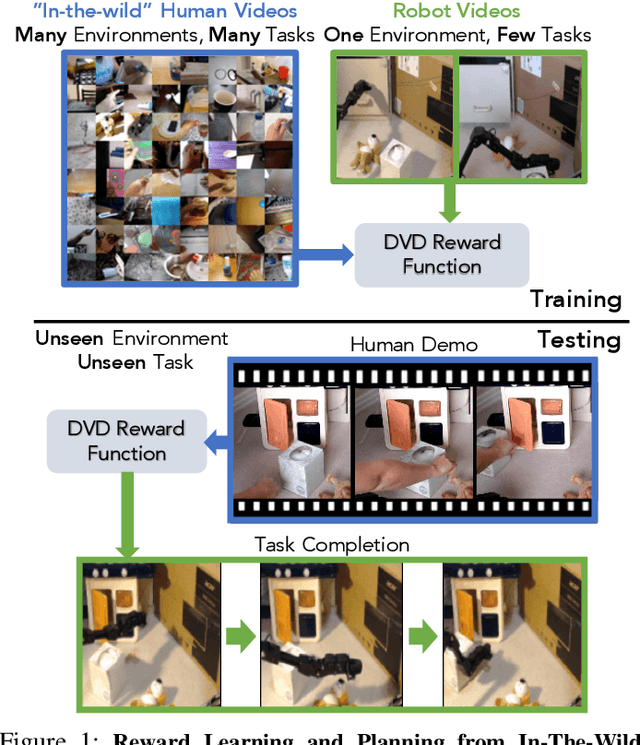
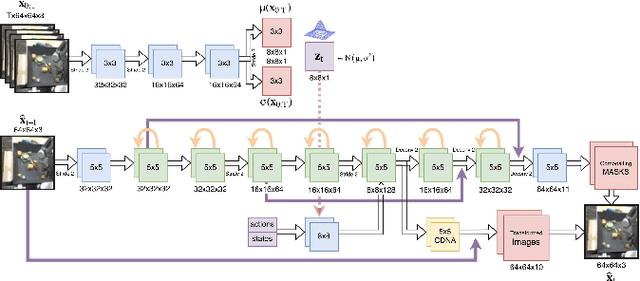
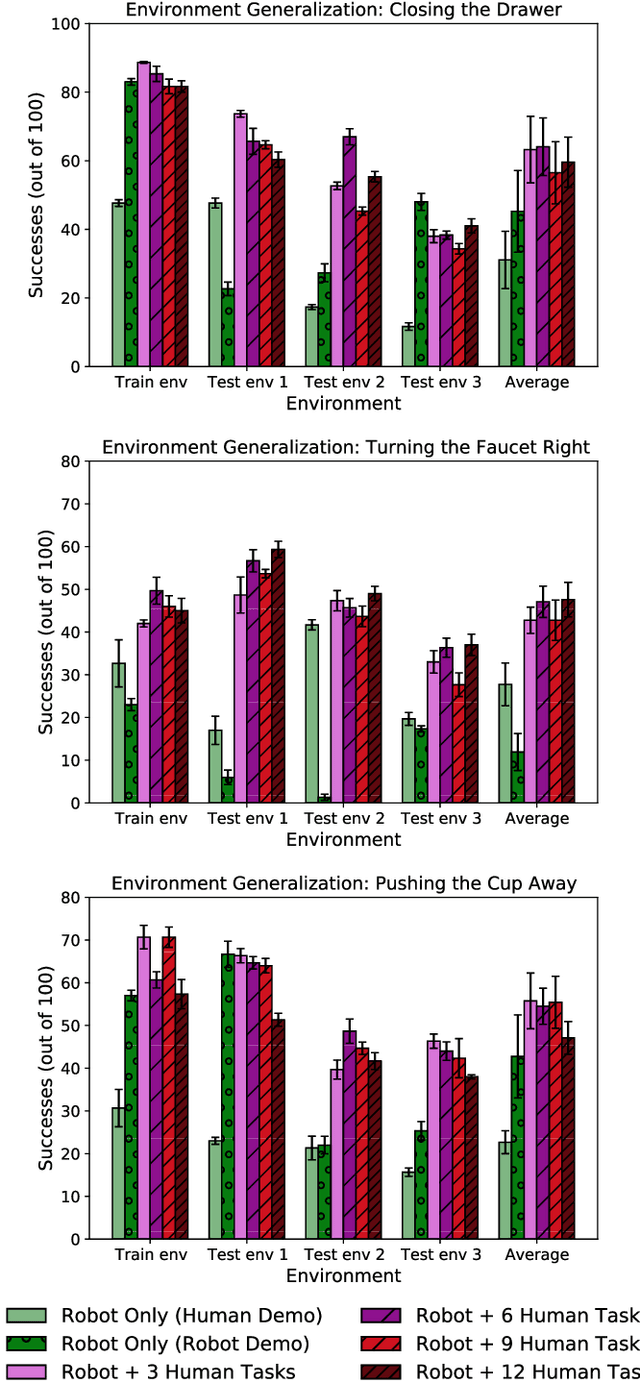
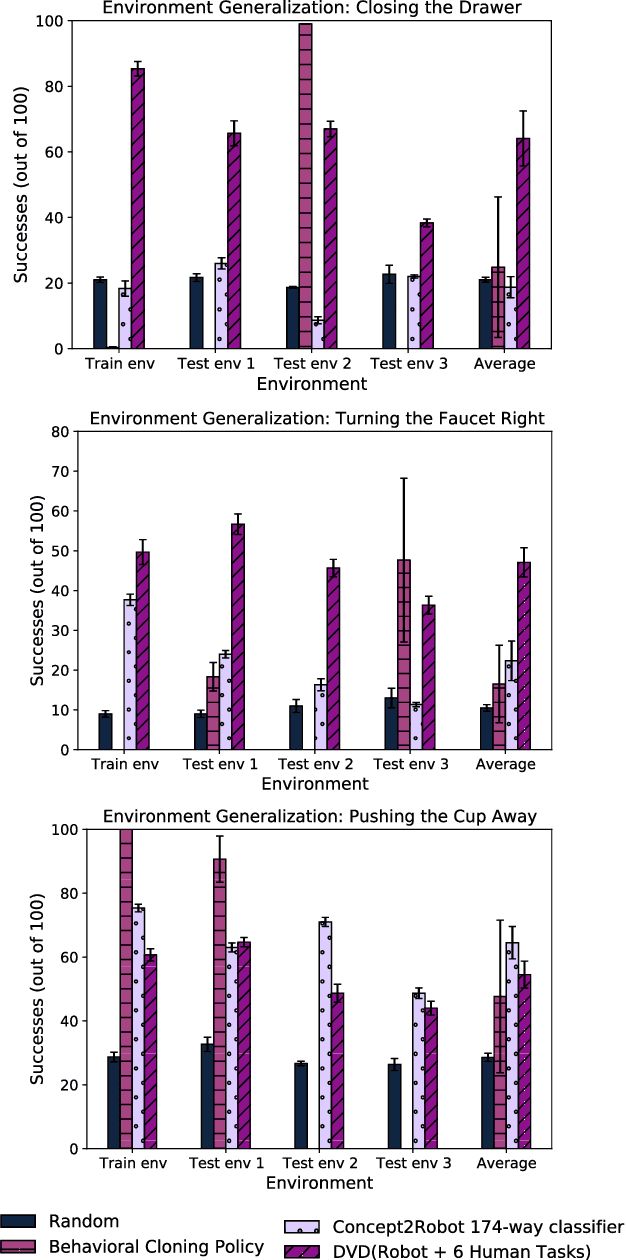
We are motivated by the goal of generalist robots that can complete a wide range of tasks across many environments. Critical to this is the robot's ability to acquire some metric of task success or reward, which is necessary for reinforcement learning, planning, or knowing when to ask for help. For a general-purpose robot operating in the real world, this reward function must also be able to generalize broadly across environments, tasks, and objects, while depending only on on-board sensor observations (e.g. RGB images). While deep learning on large and diverse datasets has shown promise as a path towards such generalization in computer vision and natural language, collecting high quality datasets of robotic interaction at scale remains an open challenge. In contrast, "in-the-wild" videos of humans (e.g. YouTube) contain an extensive collection of people doing interesting tasks across a diverse range of settings. In this work, we propose a simple approach, Domain-agnostic Video Discriminator (DVD), that learns multitask reward functions by training a discriminator to classify whether two videos are performing the same task, and can generalize by virtue of learning from a small amount of robot data with a broad dataset of human videos. We find that by leveraging diverse human datasets, this reward function (a) can generalize zero shot to unseen environments, (b) generalize zero shot to unseen tasks, and (c) can be combined with visual model predictive control to solve robotic manipulation tasks on a real WidowX200 robot in an unseen environment from a single human demo.
Greedy Hierarchical Variational Autoencoders for Large-Scale Video Prediction
Mar 26, 2021
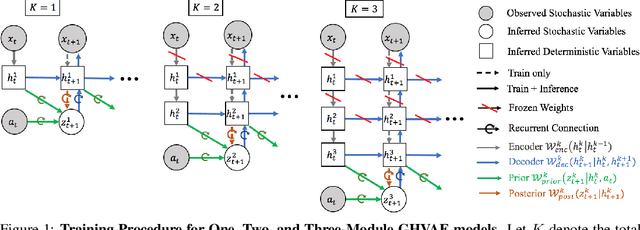

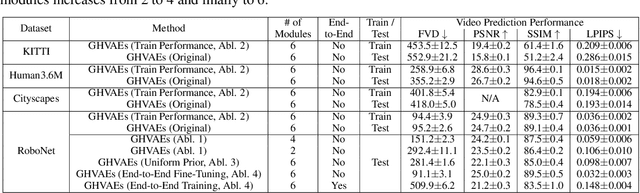
A video prediction model that generalizes to diverse scenes would enable intelligent agents such as robots to perform a variety of tasks via planning with the model. However, while existing video prediction models have produced promising results on small datasets, they suffer from severe underfitting when trained on large and diverse datasets. To address this underfitting challenge, we first observe that the ability to train larger video prediction models is often bottlenecked by the memory constraints of GPUs or TPUs. In parallel, deep hierarchical latent variable models can produce higher quality predictions by capturing the multi-level stochasticity of future observations, but end-to-end optimization of such models is notably difficult. Our key insight is that greedy and modular optimization of hierarchical autoencoders can simultaneously address both the memory constraints and the optimization challenges of large-scale video prediction. We introduce Greedy Hierarchical Variational Autoencoders (GHVAEs), a method that learns high-fidelity video predictions by greedily training each level of a hierarchical autoencoder. In comparison to state-of-the-art models, GHVAEs provide 17-55% gains in prediction performance on four video datasets, a 35-40% higher success rate on real robot tasks, and can improve performance monotonically by simply adding more modules.