 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Image-Text Metrics Respect Semantic Invariances?
May 23, 2026Reference-free image-to-text evaluators are now standard for scoring image-caption alignment, yet it is unclear whether they respect semantic invariances. We present an invariance probe on five popular evaluators (CLIPScore, PAC-S, UMIC, FLEUR, and a deterministic LLM judge) under semantics-preserving perturbations along three axes -- spatial (flips, context-preserving repositioning, light rotations), object (scale, category), and socio-linguistic framing (cultural/economic adjectives with neutral and length-matched controls). Across curated slices of three detection datasets and three caption evaluation suites, we find consistent non-semantic sensitivities, where benign spatial edits and simple phrasing changes shift scores by $\approx$6--9\% on average, and for systems separated by just 0.7\%, these shifts can cause ranking flips in up to $\sim$37\% of cases, particularly under spatial changes. A small human study also supports this finding and confirms that annotators generally judge perturbed pairs as equally correct, so these shifts reflect metric behavior rather than semantic change. We further propose invariance-calibrated scoring, a post-hoc adjustment that roughly halves median absolute sensitivity while retaining correlation with learned caption evaluators.
Robust Audio-Text Retrieval via Cross-Modal Attention and Hybrid Loss
Apr 25, 2026Audio-text retrieval enables semantic alignment between audio content and natural language queries, supporting applications in multimedia search, accessibility, and surveillance. However, current state-of-the-art approaches struggle with long, noisy, and weakly labeled audio due to their reliance on contrastive learning and large-batch training. We propose a novel multimodal retrieval framework that refines audio and text embeddings using a cross-modal embedding refinement module combining transformer-based projection, linear mapping, and bidirectional attention. To further improve robustness, we introduce a hybrid loss function blending cosine similarity, $\mathcal{L}_{1}$, and contrastive objectives, enabling stable training even under small-batch constraints. Our approach efficiently handles long-form and noisy audio (SNR 5 to 15) via silence-aware chunking and attention-based pooling. Experiments on benchmark datasets demonstrate improvements over prior methods.
Lightweight and Production-Ready PDF Visual Element Parsing
Apr 25, 2026PDF documents contain critical visual elements such as figures, tables, and forms whose accurate extraction is essential for document understanding and multimodal retrieval-augmented generation (RAG). Existing PDF parsers often miss complex visuals, extract non-informative artifacts (e.g., watermarks, logos), produce fragmented elements, and fail to reliably associate captions with their corresponding elements, which degrades downstream retrieval and question answering. We present a lightweight and production level PDF parsing framework that can accurately detect visual elements and associates captions using a combination of spatial heuristics, layout analysis, and semantic similarity. On popular benchmark datasets and internal product data, the proposed solution achieves $\geq96\%$ visual element detection accuracy and $93\%$ caption association accuracy. When used as a preprocessing step for multimodal RAG, it significantly outperforms state-of-the-art parsers and large vision-language models on both internal data and the MMDocRAG benchmark, while reducing latency by over $2\times$. We have deployed the proposed system in challenging production environment.
MACEst: The reliable and trustworthy Model Agnostic Confidence Estimator
Sep 02, 2021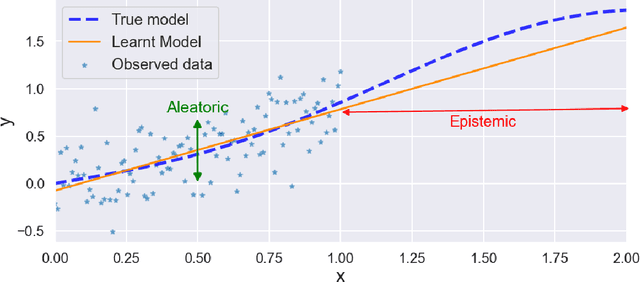
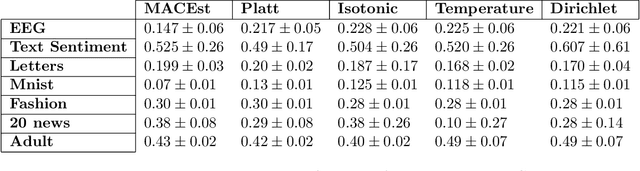
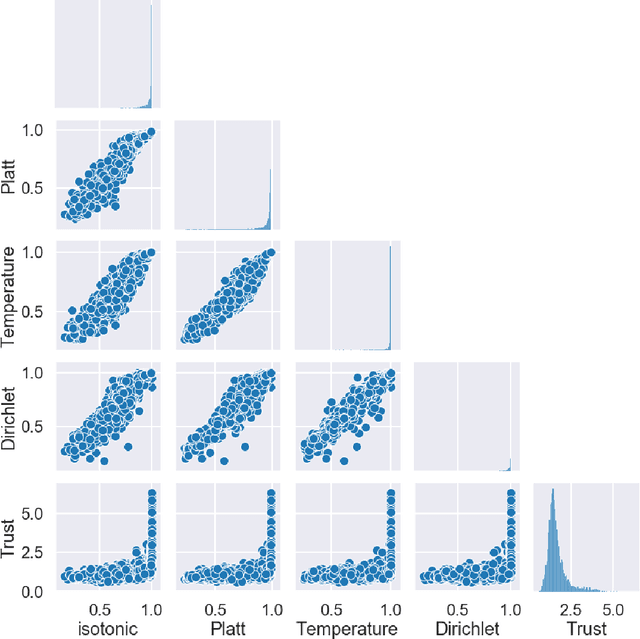
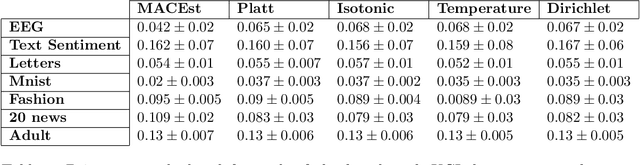
Reliable Confidence Estimates are hugely important for any machine learning model to be truly useful. In this paper, we argue that any confidence estimates based upon standard machine learning point prediction algorithms are fundamentally flawed and under situations with a large amount of epistemic uncertainty are likely to be untrustworthy. To address these issues, we present MACEst, a Model Agnostic Confidence Estimator, which provides reliable and trustworthy confidence estimates. The algorithm differs from current methods by estimating confidence independently as a local quantity which explicitly accounts for both aleatoric and epistemic uncertainty. This approach differs from standard calibration methods that use a global point prediction model as a starting point for the confidence estimate.
Tracking the Diffusion of Named Entities
Dec 29, 2017
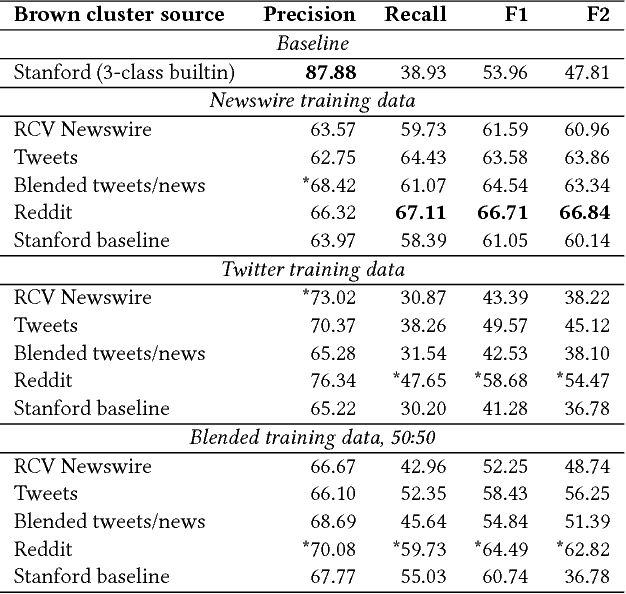
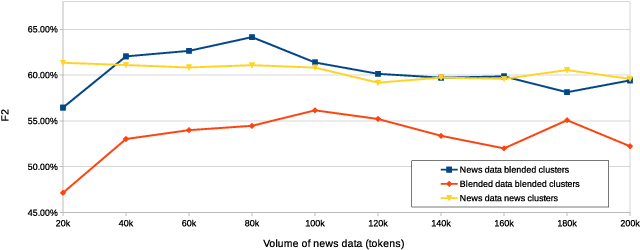
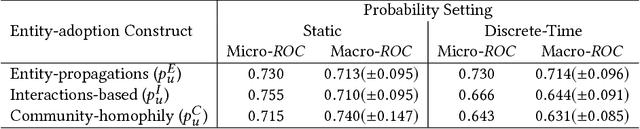
Existing studies of how information diffuses across social networks have thus far concentrated on analysing and recovering the spread of deterministic innovations such as URLs, hashtags, and group membership. However investigating how mentions of real-world entities appear and spread has yet to be explored, largely due to the computationally intractable nature of performing large-scale entity extraction. In this paper we present, to the best of our knowledge, one of the first pieces of work to closely examine the diffusion of named entities on social media, using Reddit as our case study platform. We first investigate how named entities can be accurately recognised and extracted from discussion posts. We then use these extracted entities to study the patterns of entity cascades and how the probability of a user adopting an entity (i.e. mentioning it) is associated with exposures to the entity. We put these pieces together by presenting a parallelised diffusion model that can forecast the probability of entity adoption, finding that the influence of adoption between users can be characterised by their prior interactions -- as opposed to whether the users propagated entity-adoptions beforehand. Our findings have important implications for researchers studying influence and language, and for community analysts who wish to understand entity-level influence dynamics.
Daleel: Simplifying Cloud Instance Selection Using Machine Learning
Feb 05, 2016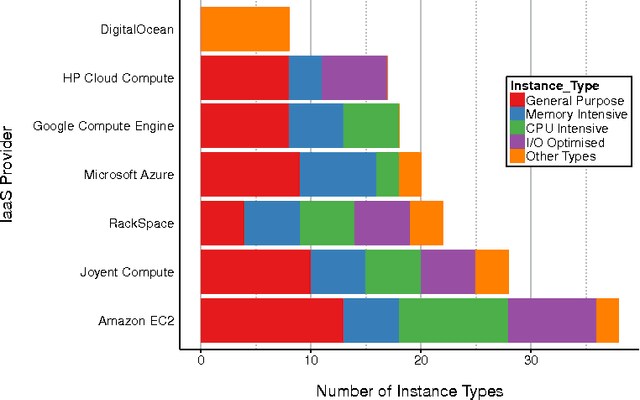
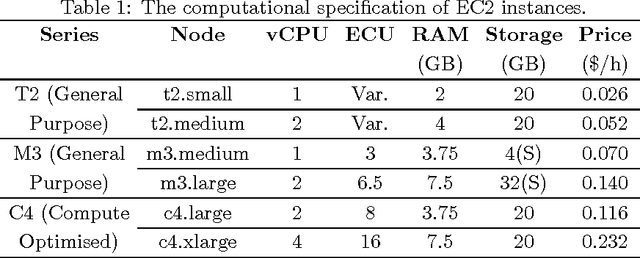
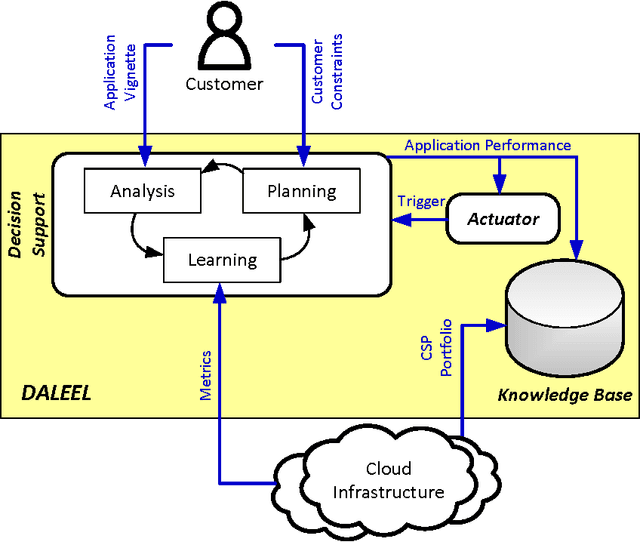
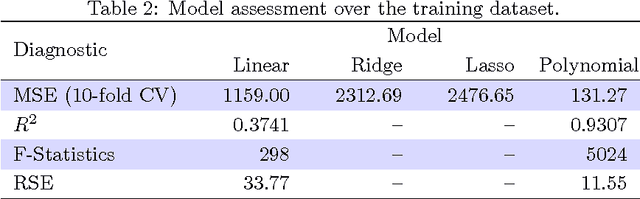
Decision making in cloud environments is quite challenging due to the diversity in service offerings and pricing models, especially considering that the cloud market is an incredibly fast moving one. In addition, there are no hard and fast rules, each customer has a specific set of constraints (e.g. budget) and application requirements (e.g. minimum computational resources). Machine learning can help address some of the complicated decisions by carrying out customer-specific analytics to determine the most suitable instance type(s) and the most opportune time for starting or migrating instances. We employ machine learning techniques to develop an adaptive deployment policy, providing an optimal match between the customer demands and the available cloud service offerings. We provide an experimental study based on extensive set of job executions over a major public cloud infrastructure.