 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualNet: Continual Learning, Fast and Slow
Oct 01, 2021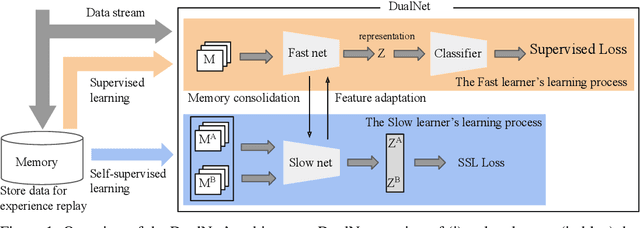
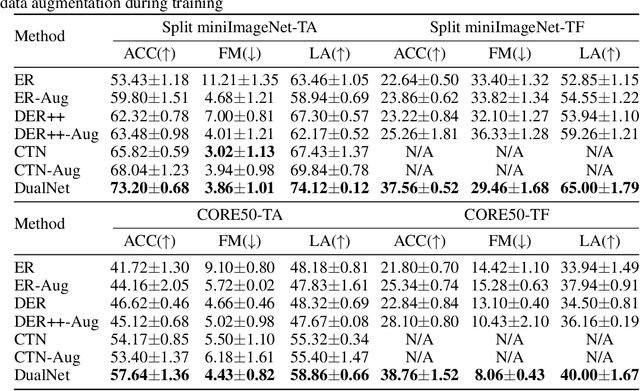
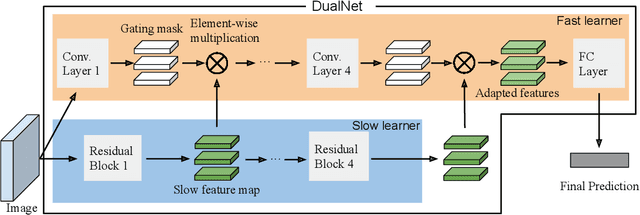
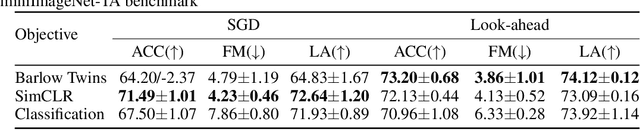
According to Complementary Learning Systems (CLS) theory~\citep{mcclelland1995there} in neuroscience, humans do effective \emph{continual learning} through two complementary systems: a fast learning system centered on the hippocampus for rapid learning of the specifics and individual experiences, and a slow learning system located in the neocortex for the gradual acquisition of structured knowledge about the environment. Motivated by this theory, we propose a novel continual learning framework named "DualNet", which comprises a fast learning system for supervised learning of pattern-separated representation from specific tasks and a slow learning system for unsupervised representation learning of task-agnostic general representation via a Self-Supervised Learning (SSL) technique. The two fast and slow learning systems are complementary and work seamlessly in a holistic continual learning framework. Our extensive experiments on two challenging continual learning benchmarks of CORE50 and miniImageNet show that DualNet outperforms state-of-the-art continual learning methods by a large margin. We further conduct ablation studies of different SSL objectives to validate DualNet's efficacy, robustness, and scalability. Code will be made available upon acceptance.
Merlion: A Machine Learning Library for Time Series
Sep 20, 2021
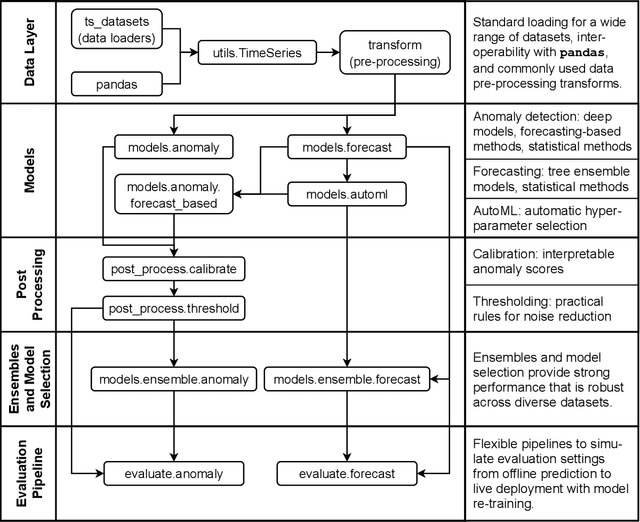
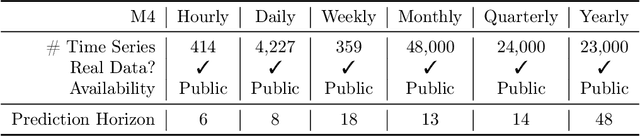

We introduce Merlion, an open-source machine learning library for time series. It features a unified interface for many commonly used models and datasets for anomaly detection and forecasting on both univariate and multivariate time series, along with standard pre/post-processing layers. It has several modules to improve ease-of-use, including visualization, anomaly score calibration to improve interpetability, AutoML for hyperparameter tuning and model selection, and model ensembling. Merlion also provides a unique evaluation framework that simulates the live deployment and re-training of a model in production. This library aims to provide engineers and researchers a one-stop solution to rapidly develop models for their specific time series needs and benchmark them across multiple time series datasets. In this technical report, we highlight Merlion's architecture and major functionalities, and we report benchmark numbers across different baseline models and ensembles.
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Jul 16, 2021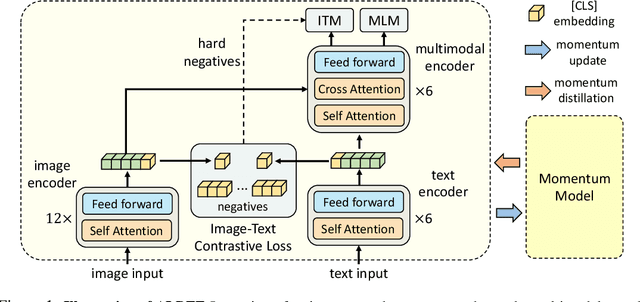
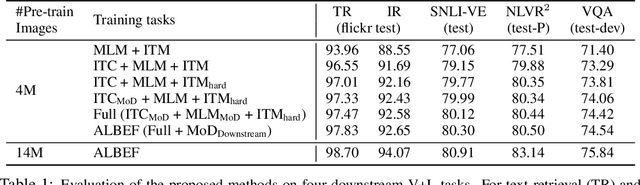

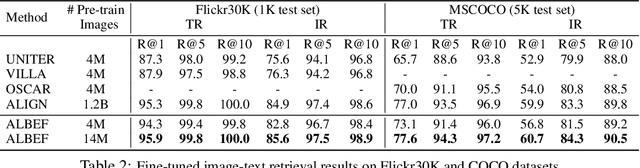
Large-scale vision and language representation learning has shown promising improvements on various vision-language tasks. Most existing methods employ a transformer-based multimodal encoder to jointly model visual tokens (region-based image features) and word tokens. Because the visual tokens and word tokens are unaligned, it is challenging for the multimodal encoder to learn image-text interactions. In this paper, we introduce a contrastive loss to ALign the image and text representations BEfore Fusing (ALBEF) them through cross-modal attention, which enables more grounded vision and language representation learning. Unlike most existing methods, our method does not require bounding box annotations nor high-resolution images. In order to improve learning from noisy web data, we propose momentum distillation, a self-training method which learns from pseudo-targets produced by a momentum model. We provide a theoretical analysis of ALBEF from a mutual information maximization perspective, showing that different training tasks can be interpreted as different ways to generate views for an image-text pair. ALBEF achieves state-of-the-art performance on multiple downstream vision-language tasks. On image-text retrieval, ALBEF outperforms methods that are pre-trained on orders of magnitude larger datasets. On VQA and NLVR$^2$, ALBEF achieves absolute improvements of 2.37% and 3.84% compared to the state-of-the-art, while enjoying faster inference speed. Code and pre-trained models are available at https://github.com/salesforce/ALBEF/.
A Theory-Driven Self-Labeling Refinement Method for Contrastive Representation Learning
Jun 28, 2021
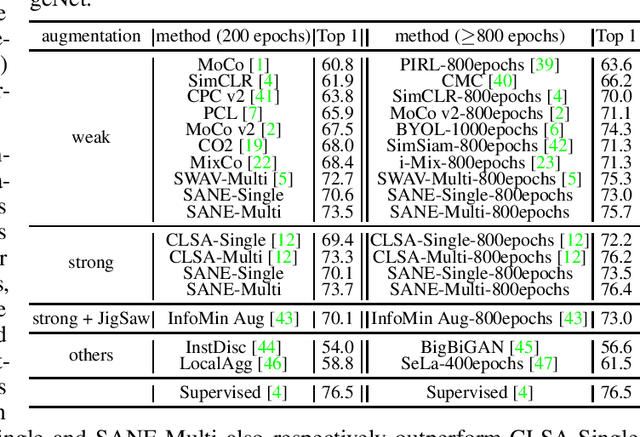
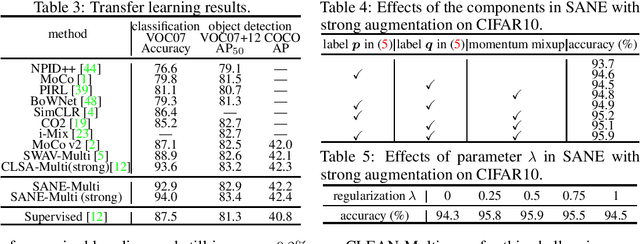

For an image query, unsupervised contrastive learning labels crops of the same image as positives, and other image crops as negatives. Although intuitive, such a native label assignment strategy cannot reveal the underlying semantic similarity between a query and its positives and negatives, and impairs performance, since some negatives are semantically similar to the query or even share the same semantic class as the query. In this work, we first prove that for contrastive learning, inaccurate label assignment heavily impairs its generalization for semantic instance discrimination, while accurate labels benefit its generalization. Inspired by this theory, we propose a novel self-labeling refinement approach for contrastive learning. It improves the label quality via two complementary modules: (i) self-labeling refinery (SLR) to generate accurate labels and (ii) momentum mixup (MM) to enhance similarity between query and its positive. SLR uses a positive of a query to estimate semantic similarity between a query and its positive and negatives, and combines estimated similarity with vanilla label assignment in contrastive learning to iteratively generate more accurate and informative soft labels. We theoretically show that our SLR can exactly recover the true semantic labels of label-corrupted data, and supervises networks to achieve zero prediction error on classification tasks. MM randomly combines queries and positives to increase semantic similarity between the generated virtual queries and their positives so as to improves label accuracy. Experimental results on CIFAR10, ImageNet, VOC and COCO show the effectiveness of our method. PyTorch code and model will be released online.
Detection and Rectification of Arbitrary Shaped Scene Texts by using Text Keypoints and Links
Mar 01, 2021
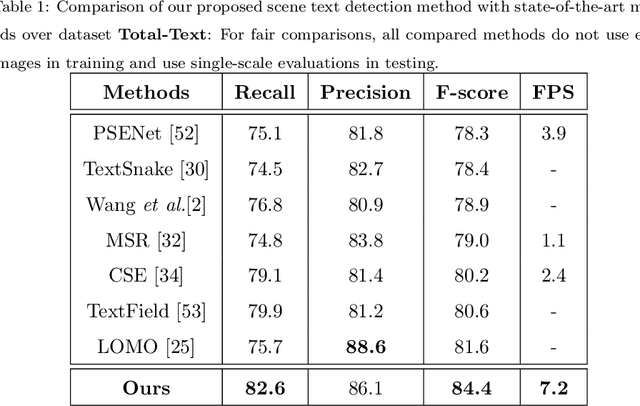

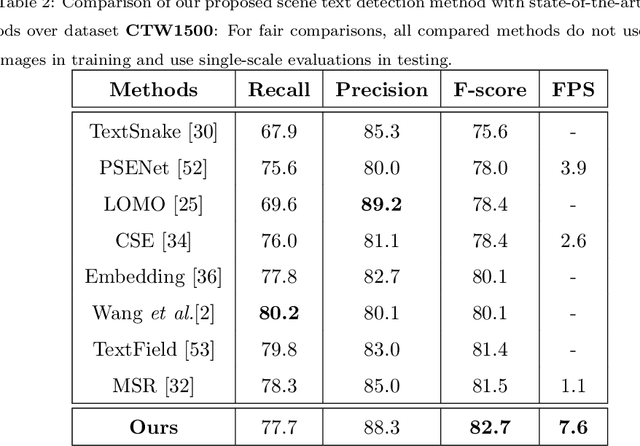
Detection and recognition of scene texts of arbitrary shapes remain a grand challenge due to the super-rich text shape variation in text line orientations, lengths, curvatures, etc. This paper presents a mask-guided multi-task network that detects and rectifies scene texts of arbitrary shapes reliably. Three types of keypoints are detected which specify the centre line and so the shape of text instances accurately. In addition, four types of keypoint links are detected of which the horizontal links associate the detected keypoints of each text instance and the vertical links predict a pair of landmark points (for each keypoint) along the upper and lower text boundary, respectively. Scene texts can be located and rectified by linking up the associated landmark points (giving localization polygon boxes) and transforming the polygon boxes via thin plate spline, respectively. Extensive experiments over several public datasets show that the use of text keypoints is tolerant to the variation in text orientations, lengths, and curvatures, and it achieves superior scene text detection and rectification performance as compared with state-of-the-art methods.
RegNet: Self-Regulated Network for Image Classification
Jan 03, 2021
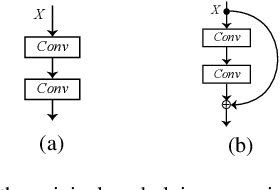
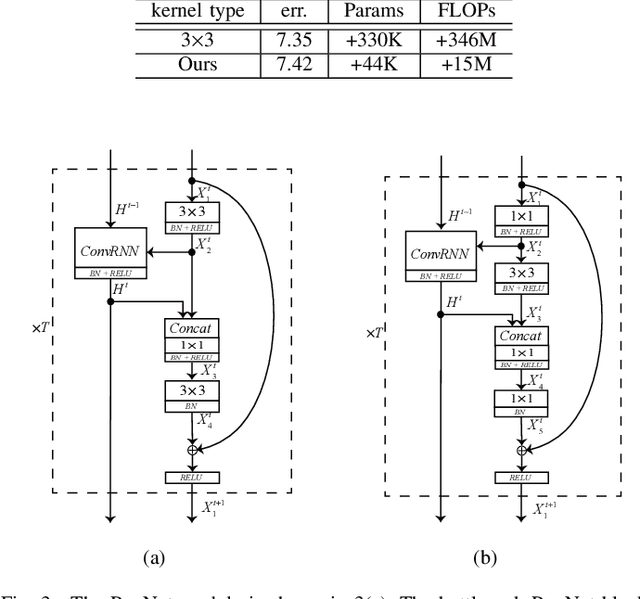
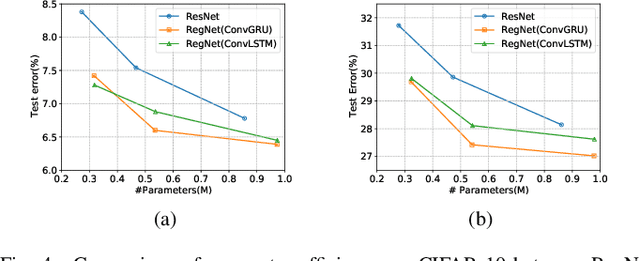
The ResNet and its variants have achieved remarkable successes in various computer vision tasks. Despite its success in making gradient flow through building blocks, the simple shortcut connection mechanism limits the ability of re-exploring new potentially complementary features due to the additive function. To address this issue, in this paper, we propose to introduce a regulator module as a memory mechanism to extract complementary features, which are further fed to the ResNet. In particular, the regulator module is composed of convolutional RNNs (e.g., Convolutional LSTMs or Convolutional GRUs), which are shown to be good at extracting Spatio-temporal information. We named the new regulated networks as RegNet. The regulator module can be easily implemented and appended to any ResNet architecture. We also apply the regulator module for improving the Squeeze-and-Excitation ResNet to show the generalization ability of our method. Experimental results on three image classification datasets have demonstrated the promising performance of the proposed architecture compared with the standard ResNet, SE-ResNet, and other state-of-the-art architectures.
Adapt-and-Adjust: Overcoming the Long-Tail Problem of Multilingual Speech Recognition
Dec 03, 2020
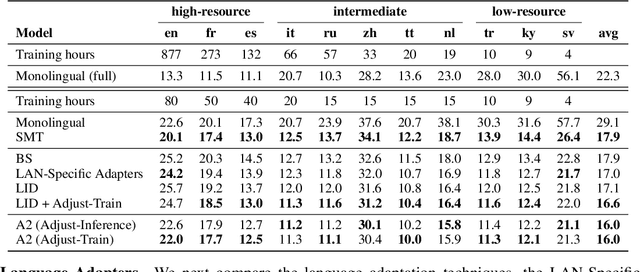
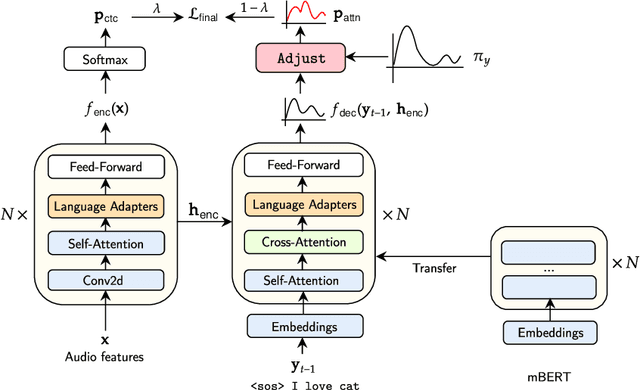
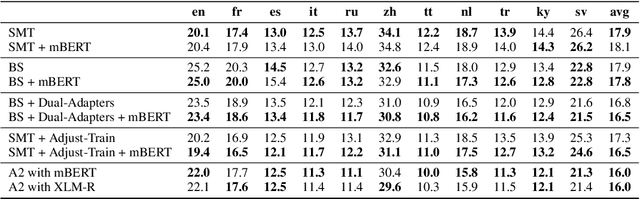
One crucial challenge of real-world multilingual speech recognition is the long-tailed distribution problem, where some resource-rich languages like English have abundant training data, but a long tail of low-resource languages have varying amounts of limited training data. To overcome the long-tail problem, in this paper, we propose Adapt-and-Adjust (A2), a transformer-based multi-task learning framework for end-to-end multilingual speech recognition. The A2 framework overcomes the long-tail problem via three techniques: (1) exploiting a pretrained multilingual language model (mBERT) to improve the performance of low-resource languages; (2) proposing dual adapters consisting of both language-specific and language-agnostic adaptation with minimal additional parameters; and (3) overcoming the class imbalance, either by imposing class priors in the loss during training or adjusting the logits of the softmax output during inference. Extensive experiments on the CommonVoice corpus show that A2 significantly outperforms conventional approaches.
CoMatch: Semi-supervised Learning with Contrastive Graph Regularization
Nov 23, 2020
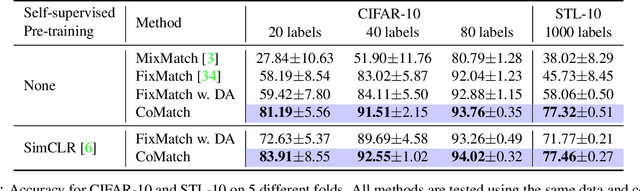
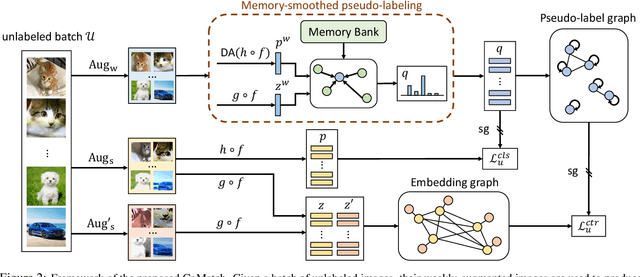
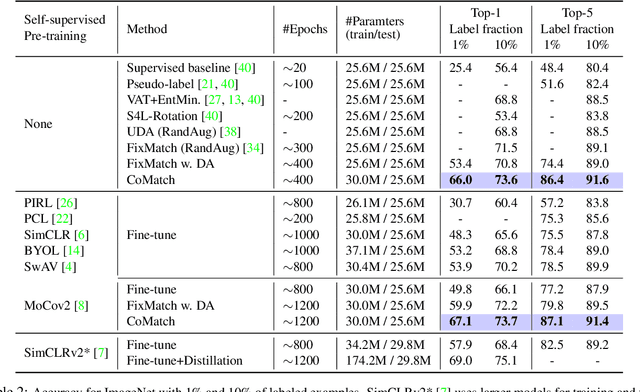
Semi-supervised learning has been an effective paradigm for leveraging unlabeled data to reduce the reliance on labeled data. We propose CoMatch, a new semi-supervised learning method that unifies dominant approaches and addresses their limitations. CoMatch jointly learns two representations of the training data, their class probabilities and low-dimensional embeddings. The two representations interact with each other to jointly evolve. The embeddings impose a smoothness constraint on the class probabilities to improve the pseudo-labels, whereas the pseudo-labels regularize the structure of the embeddings through graph-based contrastive learning. CoMatch achieves state-of-the-art performance on multiple datasets. It achieves ~20% accuracy improvement on the label-scarce CIFAR-10 and STL-10. On ImageNet with 1% labels, CoMatch achieves a top-1 accuracy of 66.0%, outperforming FixMatch by 12.6%. The accuracy further increases to 67.1% with self-supervised pre-training. Furthermore, CoMatch achieves better representation learning performance on downstream tasks, outperforming both supervised learning and self-supervised learning.
Improving Limited Labeled Dialogue State Tracking with Self-Supervision
Oct 26, 2020
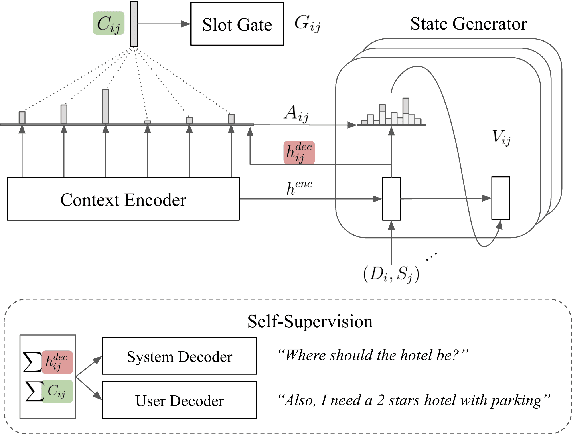
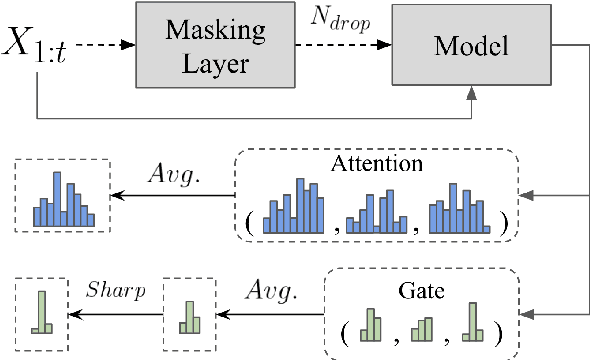
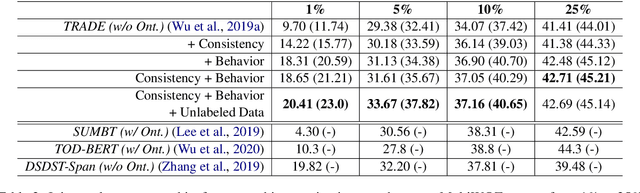
Existing dialogue state tracking (DST) models require plenty of labeled data. However, collecting high-quality labels is costly, especially when the number of domains increases. In this paper, we address a practical DST problem that is rarely discussed, i.e., learning efficiently with limited labeled data. We present and investigate two self-supervised objectives: preserving latent consistency and modeling conversational behavior. We encourage a DST model to have consistent latent distributions given a perturbed input, making it more robust to an unseen scenario. We also add an auxiliary utterance generation task, modeling a potential correlation between conversational behavior and dialogue states. The experimental results show that our proposed self-supervised signals can improve joint goal accuracy by 8.95\% when only 1\% labeled data is used on the MultiWOZ dataset. We can achieve an additional 1.76\% improvement if some unlabeled data is jointly trained as semi-supervised learning. We analyze and visualize how our proposed self-supervised signals help the DST task and hope to stimulate future data-efficient DST research.
Partially Observable Online Change Detection via Smooth-Sparse Decomposition
Sep 22, 2020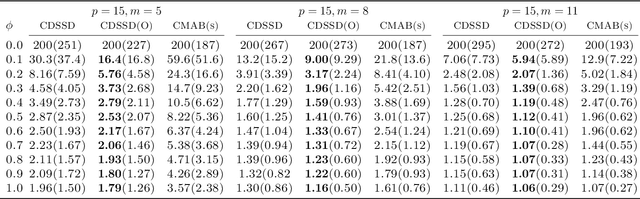
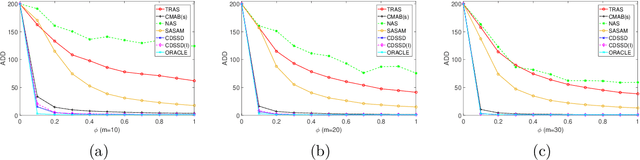
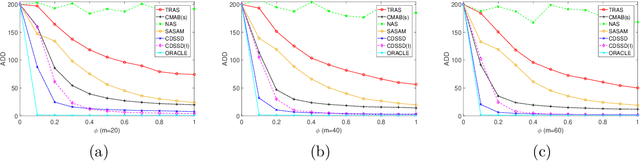
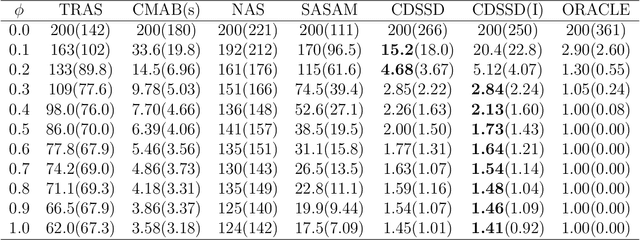
We consider online change detection of high dimensional data streams with sparse changes, where only a subset of data streams can be observed at each sensing time point due to limited sensing capacities. On the one hand, the detection scheme should be able to deal with partially observable data and meanwhile have efficient detection power for sparse changes. On the other, the scheme should be able to adaptively and actively select the most important variables to observe to maximize the detection power. To address these two points, in this paper, we propose a novel detection scheme called CDSSD. In particular, it describes the structure of high dimensional data with sparse changes by smooth-sparse decomposition, whose parameters can be learned via spike-slab variational Bayesian inference. Then the posterior Bayes factor, which incorporates the learned parameters and sparse change information, is formulated as a detection statistic. Finally, by formulating the statistic as the reward of a combinatorial multi-armed bandit problem, an adaptive sampling strategy based on Thompson sampling is proposed. The efficacy and applicability of our method in practice are demonstrated with numerical studies and a real case study.