 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-3.1-FoundationAI-SecurityLLM-Reasoning-8B Technical Report
Jan 28, 2026We present Foundation-Sec-8B-Reasoning, the first open-source native reasoning model for cybersecurity. Built upon our previously released Foundation-Sec-8B base model (derived from Llama-3.1-8B-Base), the model is trained through a two-stage process combining supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR). Our training leverages proprietary reasoning data spanning cybersecurity analysis, instruction-following, and mathematical reasoning. Evaluation across 10 cybersecurity benchmarks and 10 general-purpose benchmarks demonstrates performance competitive with significantly larger models on cybersecurity tasks while maintaining strong general capabilities. The model shows effective generalization on multi-hop reasoning tasks and strong safety performance when deployed with appropriate system prompts and guardrails. This work demonstrates that domain-specialized reasoning models can achieve strong performance on specialized tasks while maintaining broad general capabilities. We release the model publicly at https://huggingface.co/fdtn-ai/Foundation-Sec-8B-Reasoning.
Capability-Based Scaling Laws for LLM Red-Teaming
May 26, 2025As large language models grow in capability and agency, identifying vulnerabilities through red-teaming becomes vital for safe deployment. However, traditional prompt-engineering approaches may prove ineffective once red-teaming turns into a weak-to-strong problem, where target models surpass red-teamers in capabilities. To study this shift, we frame red-teaming through the lens of the capability gap between attacker and target. We evaluate more than 500 attacker-target pairs using LLM-based jailbreak attacks that mimic human red-teamers across diverse families, sizes, and capability levels. Three strong trends emerge: (i) more capable models are better attackers, (ii) attack success drops sharply once the target's capability exceeds the attacker's, and (iii) attack success rates correlate with high performance on social science splits of the MMLU-Pro benchmark. From these trends, we derive a jailbreaking scaling law that predicts attack success for a fixed target based on attacker-target capability gap. These findings suggest that fixed-capability attackers (e.g., humans) may become ineffective against future models, increasingly capable open-source models amplify risks for existing systems, and model providers must accurately measure and control models' persuasive and manipulative abilities to limit their effectiveness as attackers.
Llama-3.1-FoundationAI-SecurityLLM-Base-8B Technical Report
Apr 28, 2025



As transformer-based large language models (LLMs) increasingly permeate society, they have revolutionized domains such as software engineering, creative writing, and digital arts. However, their adoption in cybersecurity remains limited due to challenges like scarcity of specialized training data and complexity of representing cybersecurity-specific knowledge. To address these gaps, we present Foundation-Sec-8B, a cybersecurity-focused LLM built on the Llama 3.1 architecture and enhanced through continued pretraining on a carefully curated cybersecurity corpus. We evaluate Foundation-Sec-8B across both established and new cybersecurity benchmarks, showing that it matches Llama 3.1-70B and GPT-4o-mini in certain cybersecurity-specific tasks. By releasing our model to the public, we aim to accelerate progress and adoption of AI-driven tools in both public and private cybersecurity contexts.
Adversarial Reasoning at Jailbreaking Time
Feb 03, 2025As large language models (LLMs) are becoming more capable and widespread, the study of their failure cases is becoming increasingly important. Recent advances in standardizing, measuring, and scaling test-time compute suggest new methodologies for optimizing models to achieve high performance on hard tasks. In this paper, we apply these advances to the task of model jailbreaking: eliciting harmful responses from aligned LLMs. We develop an adversarial reasoning approach to automatic jailbreaking via test-time computation that achieves SOTA attack success rates (ASR) against many aligned LLMs, even the ones that aim to trade inference-time compute for adversarial robustness. Our approach introduces a new paradigm in understanding LLM vulnerabilities, laying the foundation for the development of more robust and trustworthy AI systems.
Tree of Attacks: Jailbreaking Black-Box LLMs Automatically
Dec 04, 2023While Large Language Models (LLMs) display versatile functionality, they continue to generate harmful, biased, and toxic content, as demonstrated by the prevalence of human-designed jailbreaks. In this work, we present Tree of Attacks with Pruning (TAP), an automated method for generating jailbreaks that only requires black-box access to the target LLM. TAP utilizes an LLM to iteratively refine candidate (attack) prompts using tree-of-thoughts reasoning until one of the generated prompts jailbreaks the target. Crucially, before sending prompts to the target, TAP assesses them and prunes the ones unlikely to result in jailbreaks. Using tree-of-thought reasoning allows TAP to navigate a large search space of prompts and pruning reduces the total number of queries sent to the target. In empirical evaluations, we observe that TAP generates prompts that jailbreak state-of-the-art LLMs (including GPT4 and GPT4-Turbo) for more than 80% of the prompts using only a small number of queries. This significantly improves upon the previous state-of-the-art black-box method for generating jailbreaks.
BigIssue: A Realistic Bug Localization Benchmark
Jul 21, 2022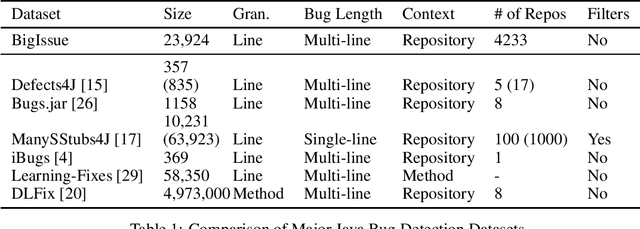



As machine learning tools progress, the inevitable question arises: How can machine learning help us write better code? With significant progress being achieved in natural language processing with models like GPT-3 and Bert, the applications of natural language processing techniques to code are starting to be explored. Most of the research has been focused on automatic program repair (APR), and while the results on synthetic or highly filtered datasets are promising, such models are hard to apply in real-world scenarios because of inadequate bug localization. We propose BigIssue: a benchmark for realistic bug localization. The goal of the benchmark is two-fold. We provide (1) a general benchmark with a diversity of real and synthetic Java bugs and (2) a motivation to improve bug localization capabilities of models through attention to the full repository context. With the introduction of BigIssue, we hope to advance the state of the art in bug localization, in turn improving APR performance and increasing its applicability to the modern development cycle.
Merlion: A Machine Learning Library for Time Series
Sep 20, 2021
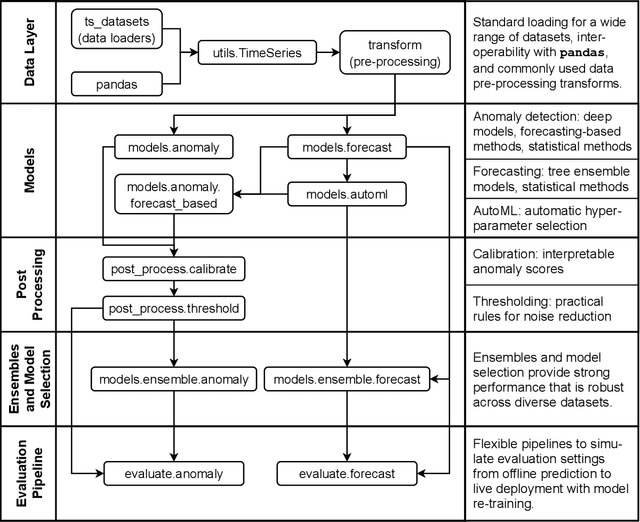
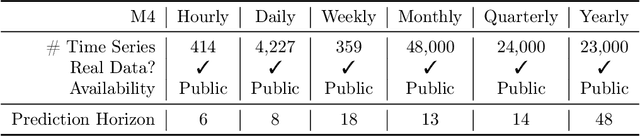

We introduce Merlion, an open-source machine learning library for time series. It features a unified interface for many commonly used models and datasets for anomaly detection and forecasting on both univariate and multivariate time series, along with standard pre/post-processing layers. It has several modules to improve ease-of-use, including visualization, anomaly score calibration to improve interpetability, AutoML for hyperparameter tuning and model selection, and model ensembling. Merlion also provides a unique evaluation framework that simulates the live deployment and re-training of a model in production. This library aims to provide engineers and researchers a one-stop solution to rapidly develop models for their specific time series needs and benchmark them across multiple time series datasets. In this technical report, we highlight Merlion's architecture and major functionalities, and we report benchmark numbers across different baseline models and ensembles.