 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic MapNet: Building Allocentric SemanticMaps and Representations from Egocentric Views
Oct 02, 2020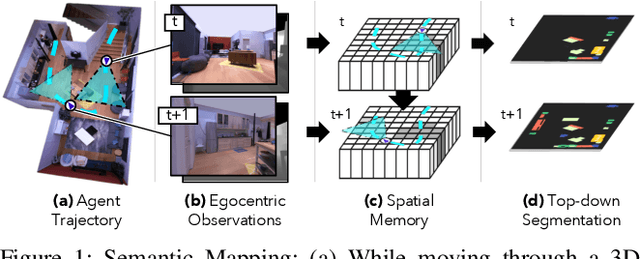

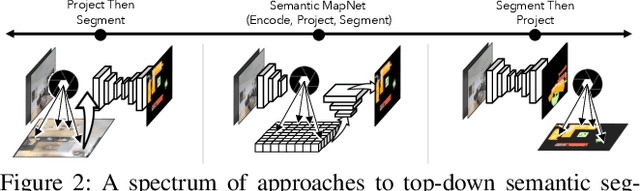

We study the task of semantic mapping - specifically, an embodied agent (a robot or an egocentric AI assistant) is given a tour of a new environment and asked to build an allocentric top-down semantic map ("what is where?") from egocentric observations of an RGB-D camera with known pose (via localization sensors). Towards this goal, we present SemanticMapNet (SMNet), which consists of: (1) an Egocentric Visual Encoder that encodes each egocentric RGB-D frame, (2) a Feature Projector that projects egocentric features to appropriate locations on a floor-plan, (3) a Spatial Memory Tensor of size floor-plan length x width x feature-dims that learns to accumulate projected egocentric features, and (4) a Map Decoder that uses the memory tensor to produce semantic top-down maps. SMNet combines the strengths of (known) projective camera geometry and neural representation learning. On the task of semantic mapping in the Matterport3D dataset, SMNet significantly outperforms competitive baselines by 4.01-16.81% (absolute) on mean-IoU and 3.81-19.69% (absolute) on Boundary-F1 metrics. Moreover, we show how to use the neural episodic memories and spatio-semantic allocentric representations build by SMNet for subsequent tasks in the same space - navigating to objects seen during the tour("Find chair") or answering questions about the space ("How many chairs did you see in the house?").
Integrating Egocentric Localization for More Realistic Point-Goal Navigation Agents
Sep 07, 2020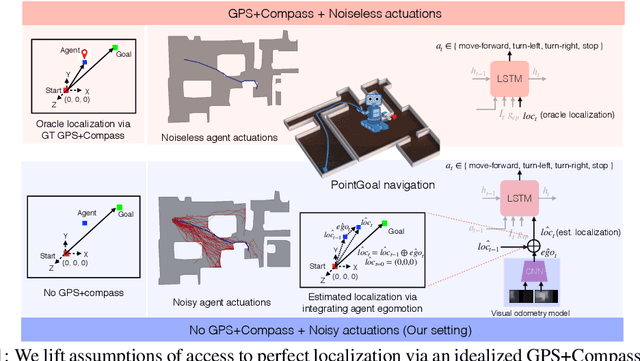
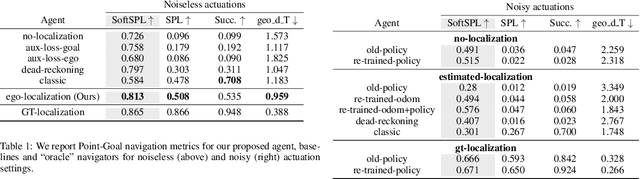
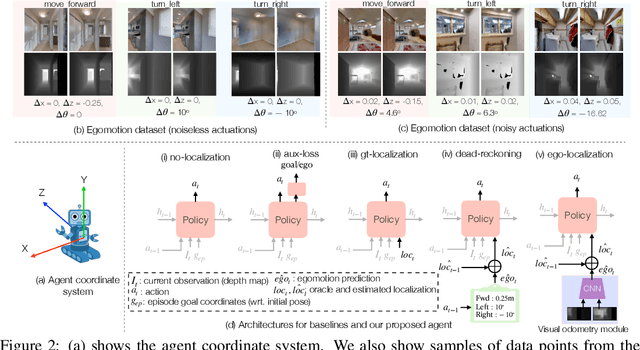
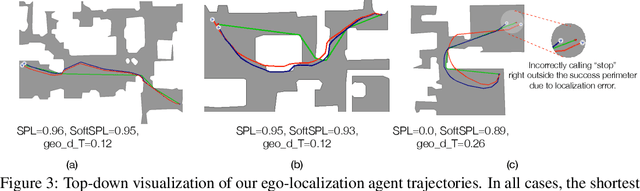
Recent work has presented embodied agents that can navigate to point-goal targets in novel indoor environments with near-perfect accuracy. However, these agents are equipped with idealized sensors for localization and take deterministic actions. This setting is practically sterile by comparison to the dirty reality of noisy sensors and actuations in the real world -- wheels can slip, motion sensors have error, actuations can rebound. In this work, we take a step towards this noisy reality, developing point-goal navigation agents that rely on visual estimates of egomotion under noisy action dynamics. We find these agents outperform naive adaptions of current point-goal agents to this setting as well as those incorporating classic localization baselines. Further, our model conceptually divides learning agent dynamics or odometry (where am I?) from task-specific navigation policy (where do I want to go?). This enables a seamless adaption to changing dynamics (a different robot or floor type) by simply re-calibrating the visual odometry model -- circumventing the expense of re-training of the navigation policy. Our agent was the runner-up in the PointNav track of CVPR 2020 Habitat Challenge.
Dialog without Dialog Data: Learning Visual Dialog Agents from VQA Data
Jul 24, 2020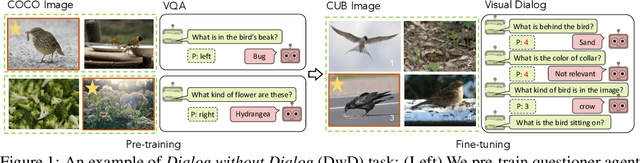
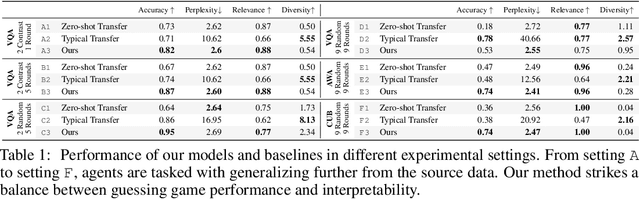
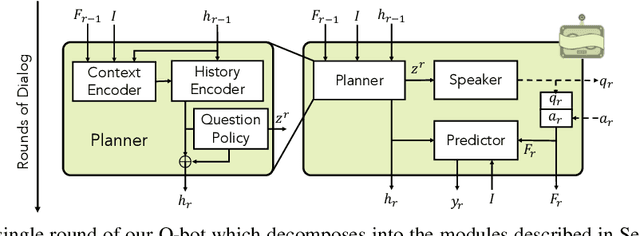
Can we develop visually grounded dialog agents that can efficiently adapt to new tasks without forgetting how to talk to people? Such agents could leverage a larger variety of existing data to generalize to new tasks, minimizing expensive data collection and annotation. In this work, we study a setting we call "Dialog without Dialog", which requires agents to develop visually grounded dialog models that can adapt to new tasks without language level supervision. By factorizing intention and language, our model minimizes linguistic drift after fine-tuning for new tasks. We present qualitative results, automated metrics, and human studies that all show our model can adapt to new tasks and maintain language quality. Baselines either fail to perform well at new tasks or experience language drift, becoming unintelligible to humans. Code has been made available at https://github.com/mcogswell/dialog_without_dialog
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web
May 01, 2020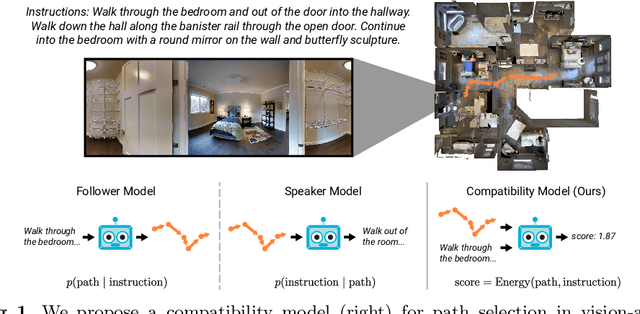
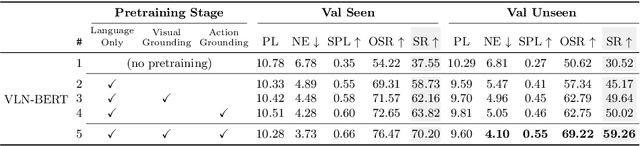

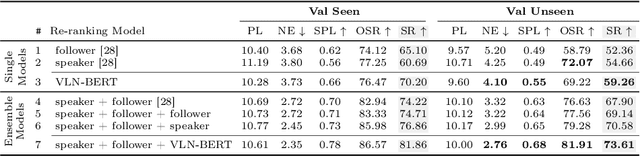
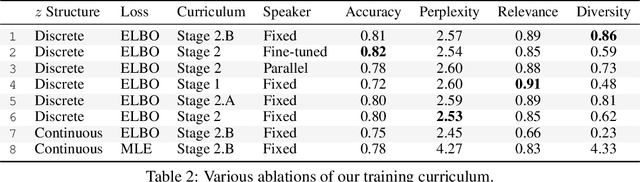
Following a navigation instruction such as 'Walk down the stairs and stop at the brown sofa' requires embodied AI agents to ground scene elements referenced via language (e.g. 'stairs') to visual content in the environment (pixels corresponding to 'stairs'). We ask the following question -- can we leverage abundant 'disembodied' web-scraped vision-and-language corpora (e.g. Conceptual Captions) to learn visual groundings (what do 'stairs' look like?) that improve performance on a relatively data-starved embodied perception task (Vision-and-Language Navigation)? Specifically, we develop VLN-BERT, a visiolinguistic transformer-based model for scoring the compatibility between an instruction ('...stop at the brown sofa') and a sequence of panoramic RGB images captured by the agent. We demonstrate that pretraining VLN-BERT on image-text pairs from the web before fine-tuning on embodied path-instruction data significantly improves performance on VLN -- outperforming the prior state-of-the-art in the fully-observed setting by 4 absolute percentage points on success rate. Ablations of our pretraining curriculum show each stage to be impactful -- with their combination resulting in further positive synergistic effects.
Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments
Apr 06, 2020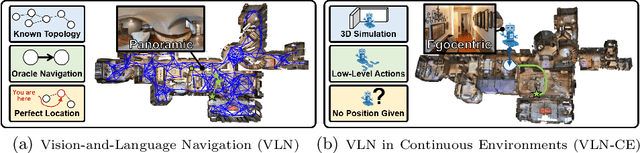


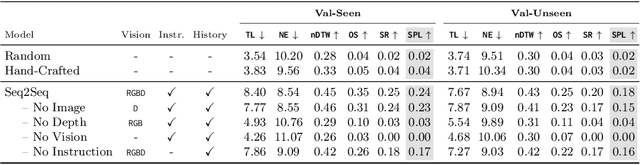
We develop a language-guided navigation task set in a continuous 3D environment where agents must execute low-level actions to follow natural language navigation directions. By being situated in continuous environments, this setting lifts a number of assumptions implicit in prior work that represents environments as a sparse graph of panoramas with edges corresponding to navigability. Specifically, our setting drops the presumptions of known environment topologies, short-range oracle navigation, and perfect agent localization. To contextualize this new task, we develop models that mirror many of the advances made in prior settings as well as single-modality baselines. While some of these techniques transfer, we find significantly lower absolute performance in the continuous setting -- suggesting that performance in prior `navigation-graph' settings may be inflated by the strong implicit assumptions.
Are We Making Real Progress in Simulated Environments? Measuring the Sim2Real Gap in Embodied Visual Navigation
Dec 13, 2019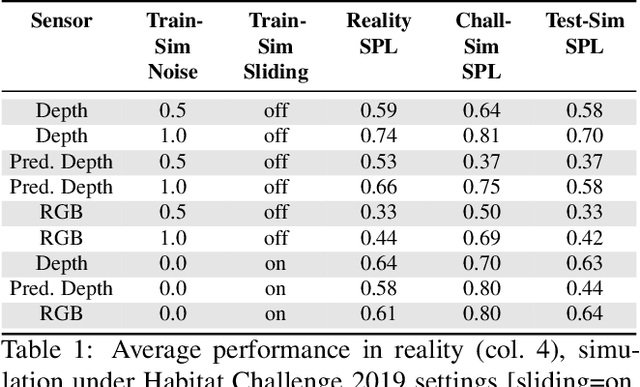

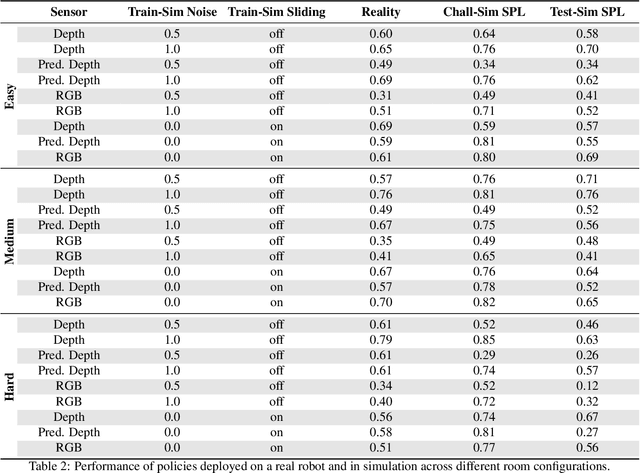

Does progress in simulation translate to progress in robotics? Specifically, if method A outperforms method B in simulation, how likely is the trend to hold in reality on a robot? We examine this question for embodied (PointGoal) navigation, developing engineering tools and a research paradigm for evaluating a simulator by its sim2real predictivity, revealing surprising findings about prior work. First, we develop Habitat-PyRobot Bridge (HaPy), a library for seamless execution of identical code on a simulated agent and a physical robot. Habitat-to-Locobot transfer with HaPy involves just one line change in config, essentially treating reality as just another simulator! Second, we investigate sim2real predictivity of Habitat-Sim for PointGoal navigation. We 3D-scan a physical lab space to create a virtualized replica, and run parallel tests of 9 different models in reality and simulation. We present a new metric called Sim-vs-Real Correlation Coefficient (SRCC) to quantify sim2real predictivity. Our analysis reveals several important findings. We find that SRCC for Habitat as used for the CVPR19 challenge is low (0.18 for the success metric), which suggests that performance improvements for this simulator-based challenge would not transfer well to a physical robot. We find that this gap is largely due to AI agents learning to 'cheat' by exploiting simulator imperfections: specifically, the way Habitat allows for 'sliding' along walls on collision. Essentially, the virtual robot is capable of cutting corners, leading to unrealistic shortcuts through non-navigable spaces. Naturally, such exploits do not work in the real world where the robot stops on contact with walls. Our experiments show that it is possible to optimize simulation parameters to enable robots trained in imperfect simulators to generalize learned skills to reality (e.g. improving $SRCC_{Succ}$ from 0.18 to 0.844).
12-in-1: Multi-Task Vision and Language Representation Learning
Dec 05, 2019
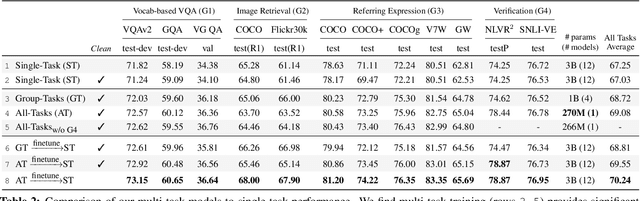
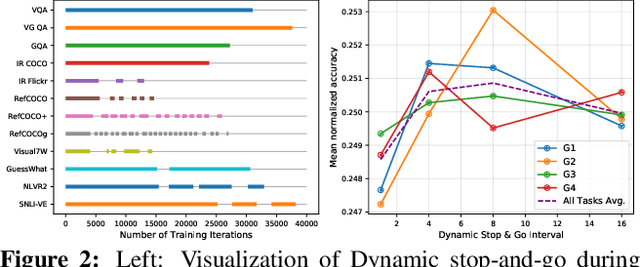
Much of vision-and-language research focuses on a small but diverse set of independent tasks and supporting datasets often studied in isolation; however, the visually-grounded language understanding skills required for success at these tasks overlap significantly. In this work, we investigate these relationships between vision-and-language tasks by developing a large-scale, multi-task training regime. Our approach culminates in a single model on 12 datasets from four broad categories of task including visual question answering, caption-based image retrieval, grounding referring expressions, and multi-modal verification. Compared to independently trained single-task models, this represents a reduction from approximately 3 billion parameters to 270 million while simultaneously improving performance by 2.05 points on average across tasks. We use our multi-task framework to perform in-depth analysis of the effect of joint training diverse tasks. Further, we show that finetuning task-specific models from our single multi-task model can lead to further improvements, achieving performance at or above the state-of-the-art.
Question-Conditioned Counterfactual Image Generation for VQA
Nov 14, 2019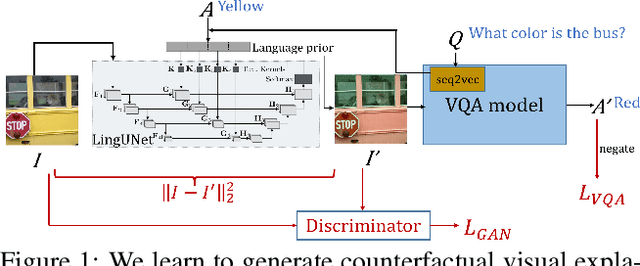

While Visual Question Answering (VQA) models continue to push the state-of-the-art forward, they largely remain black-boxes - failing to provide insight into how or why an answer is generated. In this ongoing work, we propose addressing this shortcoming by learning to generate counterfactual images for a VQA model - i.e. given a question-image pair, we wish to generate a new image such that i) the VQA model outputs a different answer, ii) the new image is minimally different from the original, and iii) the new image is realistic. Our hope is that providing such counterfactual examples allows users to investigate and understand the VQA model's internal mechanisms.
Decentralized Distributed PPO: Solving PointGoal Navigation
Nov 01, 2019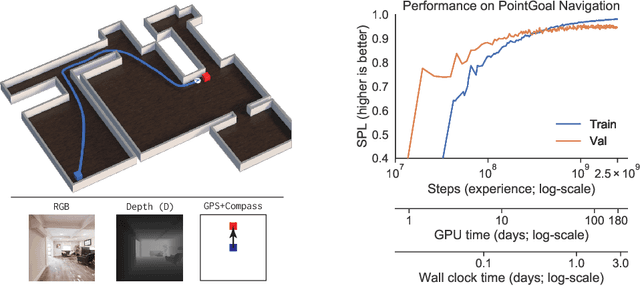

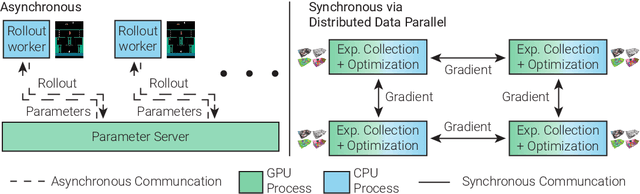
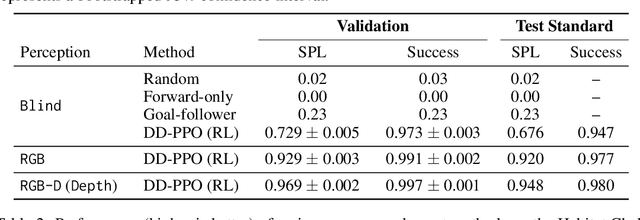
We present Decentralized Distributed Proximal Policy Optimization (DD-PPO), a method for distributed reinforcement learning in resource-intensive simulated environments. DD-PPO is distributed (uses multiple machines), decentralized (lacks a centralized server), and synchronous (no computation is ever "stale"), making it conceptually simple and easy to implement. In our experiments on training virtual robots to navigate in Habitat-Sim, DD-PPO exhibits near-linear scaling -- achieving a speedup of 107x on 128 GPUs over a serial implementation. We leverage this scaling to train an agent for 2.5 Billion steps of experience (the equivalent of 80 years of human experience) -- over 6 months of GPU-time training in under 3 days of wall-clock time with 64 GPUs. This massive-scale training not only sets the state of art on Habitat Autonomous Navigation Challenge 2019, but essentially "solves" the task -- near-perfect autonomous navigation in an unseen environment without access to a map, directly from an RGB-D camera and a GPS+Compass sensor. Fortuitously, error vs computation exhibits a power-law-like distribution; thus, 90% of peak performance is obtained relatively early (at 100 million steps) and relatively cheaply (under 1 day with 8 GPUs). Finally, we show that the scene understanding and navigation policies learned can be transferred to other navigation tasks -- the analog of "ImageNet pre-training + task-specific fine-tuning" for embodied AI. Our model outperforms ImageNet pre-trained CNNs on these transfer tasks and can serve as a universal resource (all models + code will be publicly available).
Sunny and Dark Outside?! Improving Answer Consistency in VQA through Entailed Question Generation
Sep 10, 2019
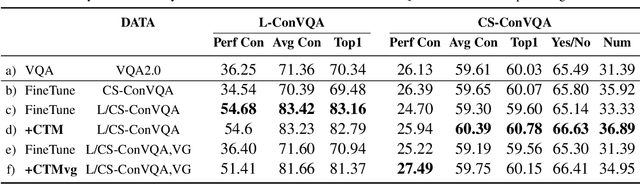
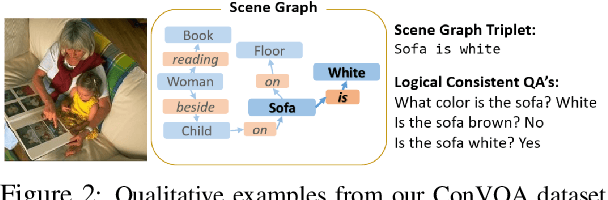

While models for Visual Question Answering (VQA) have steadily improved over the years, interacting with one quickly reveals that these models lack consistency. For instance, if a model answers "red" to "What color is the balloon?", it might answer "no" if asked, "Is the balloon red?". These responses violate simple notions of entailment and raise questions about how effectively VQA models ground language. In this work, we introduce a dataset, ConVQA, and metrics that enable quantitative evaluation of consistency in VQA. For a given observable fact in an image (e.g. the balloon's color), we generate a set of logically consistent question-answer (QA) pairs (e.g. Is the balloon red?) and also collect a human-annotated set of common-sense based consistent QA pairs (e.g. Is the balloon the same color as tomato sauce?). Further, we propose a consistency-improving data augmentation module, a Consistency Teacher Module (CTM). CTM automatically generates entailed (or similar-intent) questions for a source QA pair and fine-tunes the VQA model if the VQA's answer to the entailed question is consistent with the source QA pair. We demonstrate that our CTM-based training improves the consistency of VQA models on the ConVQA datasets and is a strong baseline for further research.