 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindIt: A Format-Informed Visual Detection Benchmark for Generalist Multimodal LLMs
Jun 02, 2026Multimodal large language models (MLLMs) are predominantly evaluated on free-form vision-language tasks such as visual question answering, captioning, and summarization. However, their practical use is rapidly expanding to more structured computer vision settings, where users prompt models to perform localization-centric tasks such as object detection, often within larger agentic or decision-making systems. Despite this shift, there is currently no standardized benchmark that systematically evaluates these capabilities at scale. In this work, we introduce the first comprehensive benchmark specifically designed to assess the promptable localization abilities of generalist MLLMs. Our benchmark spans four core task categories: object detection, referring expression detection, instance-level detection, and video-based detection. To enable consistent and fair evaluation, we develop a unified framework that standardizes inputs, enforces parsable bounding box outputs, and defines transparent evaluation protocols across tasks. Using this suite, we evaluate a diverse set of open-source and proprietary MLLMs, providing an in-depth analysis of their performance and limitations. Beyond accuracy, we examine models' ability to adhere to output format specifications, showing that current systems are highly sensitive to formatting constraints and often fail to generalize even to minor variations. Our results highlight both the strengths and shortcomings of state-of-the-art MLLMs in localization settings, and point toward important directions for improving multimodal model design and evaluation.
CaST-Bench: Benchmarking Causal Chain-Grounded Spatio-Temporal Reasoning for Video Question Answering
May 22, 2026Cause-and-effect reasoning in video is a significant challenge for Vision-Language Models (VLMs), as it requires going beyond surface-level perception to a deeper understanding of causal mechanisms. However, existing benchmarks rarely provide the fine-grained, grounded evidence needed to rigorously evaluate this capability. To address this gap, we introduce CaST-Bench, a benchmark for Causal Chain-Grounded Spatio-Temporal Video Reasoning. CaST-Bench presents complex causal questions that require models to identify and localize a chain of multiple spatio-temporal evidences. Through a human-AI collaborative pipeline, we construct a high-quality dataset of 2,066 questions over 1,015 videos, with causal chains annotated by temporal segments and bounding-box tracks. Furthermore, we design a comprehensive evaluation suite with novel metrics that assess not only answer correctness but also the capability for visual evidence grounded reasoning. This grounding is crucial for improving accuracy by mitigating spurious correlations and for enhancing user trust by making models more transparent. Our experiments show that current VLMs struggle with causal questions, largely due to their limited ability to construct precise and grounded causal chains. This highlights an important direction for improving future VLMs.
InstAP: Instance-Aware Vision-Language Pre-Train for Spatial-Temporal Understanding
Apr 09, 2026Current vision-language pre-training (VLP) paradigms excel at global scene understanding but struggle with instance-level reasoning due to global-only supervision. We introduce InstAP, an Instance-Aware Pre-training framework that jointly optimizes global vision-text alignment and fine-grained, instance-level contrastive alignment by grounding textual mentions to specific spatial-temporal regions. To support this, we present InstVL, a large-scale dataset (2 million images, 50,000 videos) with dual-granularity annotations: holistic scene captions and dense, grounded instance descriptions. On the InstVL benchmark, InstAP substantially outperforms existing VLP models on instance-level retrieval, and also surpasses a strong VLP baseline trained on the exact same data corpus, isolating the benefit of our instance-aware objective. Moreover, instance-centric pre-training improves global understanding: InstAP achieves competitive zero-shot performance on multiple video benchmarks, including MSR-VTT and DiDeMo. Qualitative visualizations further show that InstAP localizes textual mentions to the correct instances, while global-only models exhibit more diffuse, scene-level attention.
WTS: A Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding
Jul 22, 2024



In this paper, we address the challenge of fine-grained video event understanding in traffic scenarios, vital for autonomous driving and safety. Traditional datasets focus on driver or vehicle behavior, often neglecting pedestrian perspectives. To fill this gap, we introduce the WTS dataset, highlighting detailed behaviors of both vehicles and pedestrians across over 1.2k video events in hundreds of traffic scenarios. WTS integrates diverse perspectives from vehicle ego and fixed overhead cameras in a vehicle-infrastructure cooperative environment, enriched with comprehensive textual descriptions and unique 3D Gaze data for a synchronized 2D/3D view, focusing on pedestrian analysis. We also pro-vide annotations for 5k publicly sourced pedestrian-related traffic videos. Additionally, we introduce LLMScorer, an LLM-based evaluation metric to align inference captions with ground truth. Using WTS, we establish a benchmark for dense video-to-text tasks, exploring state-of-the-art Vision-Language Models with an instance-aware VideoLLM method as a baseline. WTS aims to advance fine-grained video event understanding, enhancing traffic safety and autonomous driving development.
DEXTER: Deep Encoding of External Knowledge for Named Entity Recognition in Virtual Assistants
Aug 15, 2021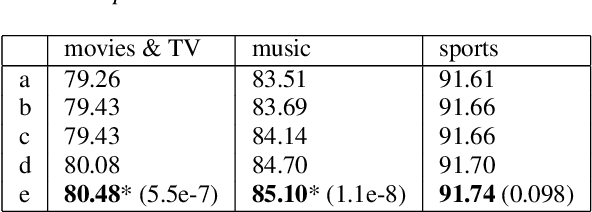
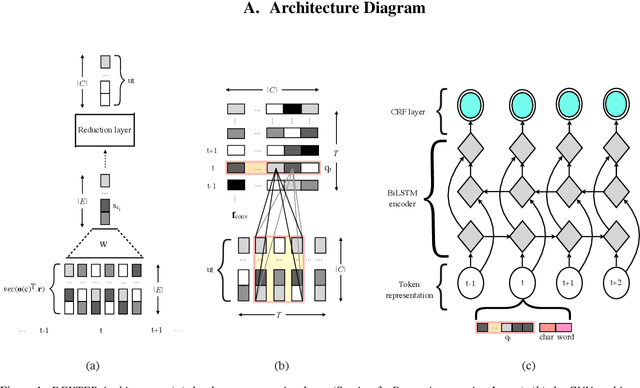
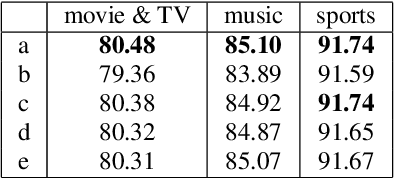
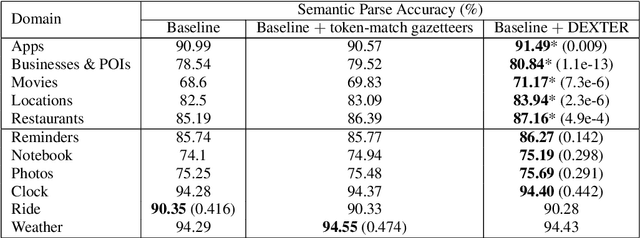
Named entity recognition (NER) is usually developed and tested on text from well-written sources. However, in intelligent voice assistants, where NER is an important component, input to NER may be noisy because of user or speech recognition error. In applications, entity labels may change frequently, and non-textual properties like topicality or popularity may be needed to choose among alternatives. We describe a NER system intended to address these problems. We test and train this system on a proprietary user-derived dataset. We compare with a baseline text-only NER system; the baseline enhanced with external gazetteers; and the baseline enhanced with the search and indirect labelling techniques we describe below. The final configuration gives around 6% reduction in NER error rate. We also show that this technique improves related tasks, such as semantic parsing, with an improvement of up to 5% in error rate.
Question-Conditioned Counterfactual Image Generation for VQA
Nov 14, 2019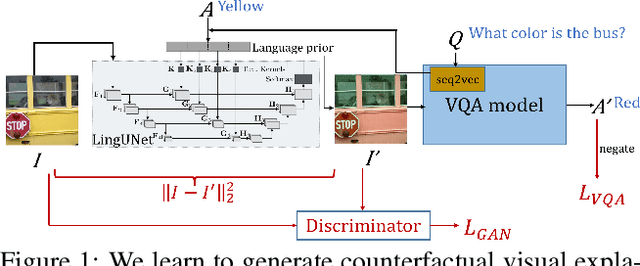

While Visual Question Answering (VQA) models continue to push the state-of-the-art forward, they largely remain black-boxes - failing to provide insight into how or why an answer is generated. In this ongoing work, we propose addressing this shortcoming by learning to generate counterfactual images for a VQA model - i.e. given a question-image pair, we wish to generate a new image such that i) the VQA model outputs a different answer, ii) the new image is minimally different from the original, and iii) the new image is realistic. Our hope is that providing such counterfactual examples allows users to investigate and understand the VQA model's internal mechanisms.