 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Causal Models with Active Interventions
Sep 06, 2021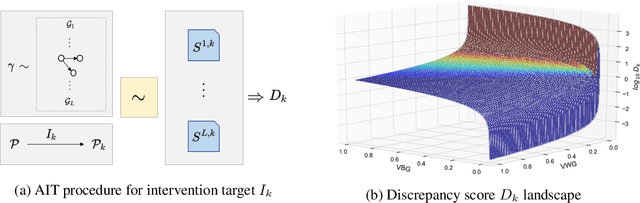
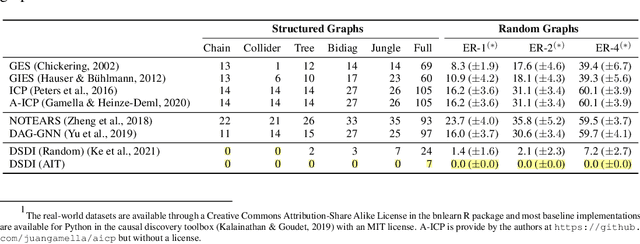
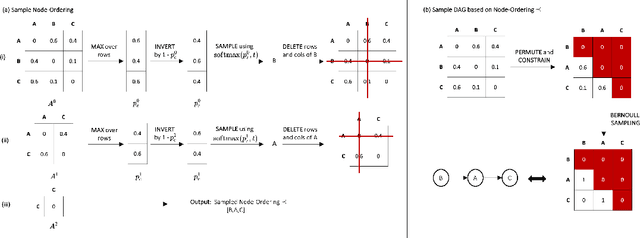
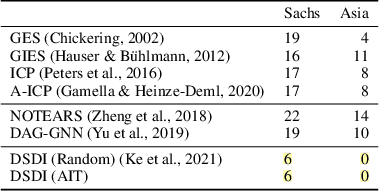
Discovering causal structures from data is a challenging inference problem of fundamental importance in all areas of science. The appealing scaling properties of neural networks have recently led to a surge of interest in differentiable neural network-based methods for learning causal structures from data. So far differentiable causal discovery has focused on static datasets of observational or interventional origin. In this work, we introduce an active intervention-targeting mechanism which enables a quick identification of the underlying causal structure of the data-generating process. Our method significantly reduces the required number of interactions compared with random intervention targeting and is applicable for both discrete and continuous optimization formulations of learning the underlying directed acyclic graph (DAG) from data. We examine the proposed method across a wide range of settings and demonstrate superior performance on multiple benchmarks from simulated to real-world data.
Transferring Dexterous Manipulation from GPU Simulation to a Remote Real-World TriFinger
Aug 22, 2021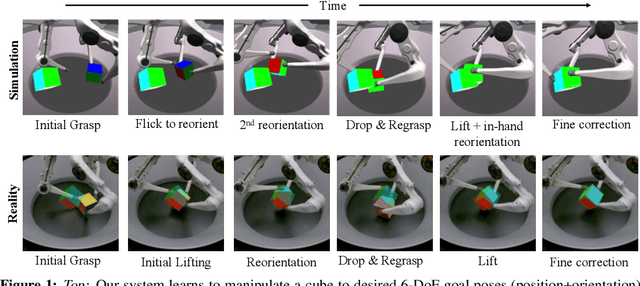
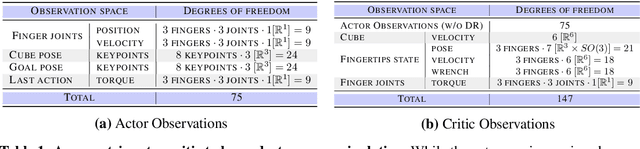
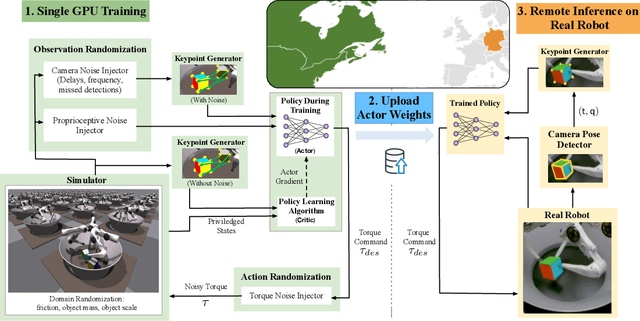
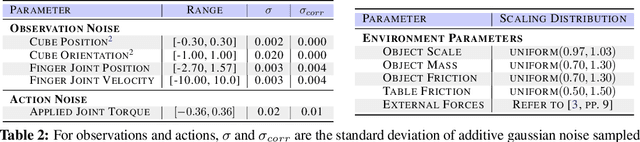
We present a system for learning a challenging dexterous manipulation task involving moving a cube to an arbitrary 6-DoF pose with only 3-fingers trained with NVIDIA's IsaacGym simulator. We show empirical benefits, both in simulation and sim-to-real transfer, of using keypoints as opposed to position+quaternion representations for the object pose in 6-DoF for policy observations and in reward calculation to train a model-free reinforcement learning agent. By utilizing domain randomization strategies along with the keypoint representation of the pose of the manipulated object, we achieve a high success rate of 83% on a remote TriFinger system maintained by the organizers of the Real Robot Challenge. With the aim of assisting further research in learning in-hand manipulation, we make the codebase of our system, along with trained checkpoints that come with billions of steps of experience available, at https://s2r2-ig.github.io
Representation Learning for Out-Of-Distribution Generalization in Reinforcement Learning
Jul 12, 2021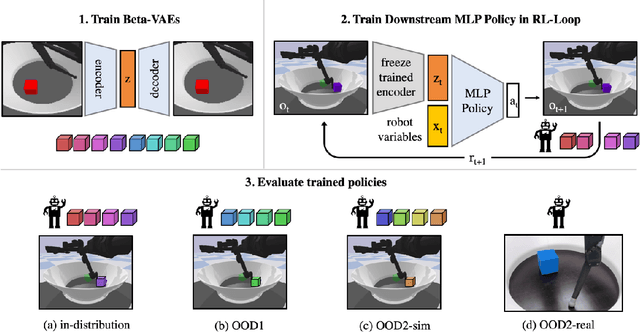
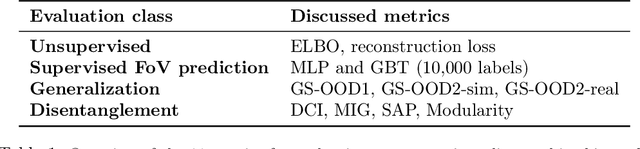
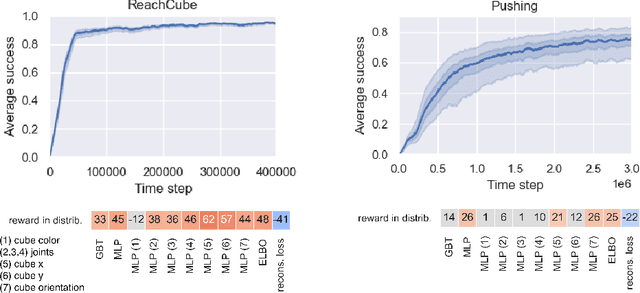
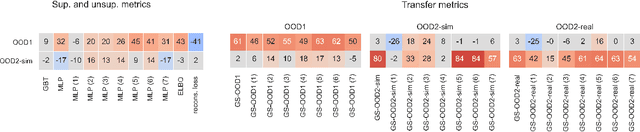
Learning data representations that are useful for various downstream tasks is a cornerstone of artificial intelligence. While existing methods are typically evaluated on downstream tasks such as classification or generative image quality, we propose to assess representations through their usefulness in downstream control tasks, such as reaching or pushing objects. By training over 10,000 reinforcement learning policies, we extensively evaluate to what extent different representation properties affect out-of-distribution (OOD) generalization. Finally, we demonstrate zero-shot transfer of these policies from simulation to the real world, without any domain randomization or fine-tuning. This paper aims to establish the first systematic characterization of the usefulness of learned representations for real-world OOD downstream tasks.
Systematic Evaluation of Causal Discovery in Visual Model Based Reinforcement Learning
Jul 02, 2021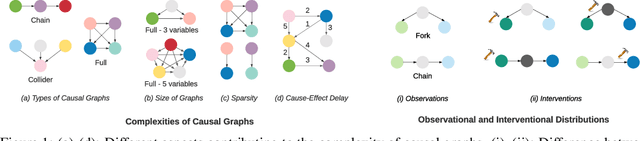
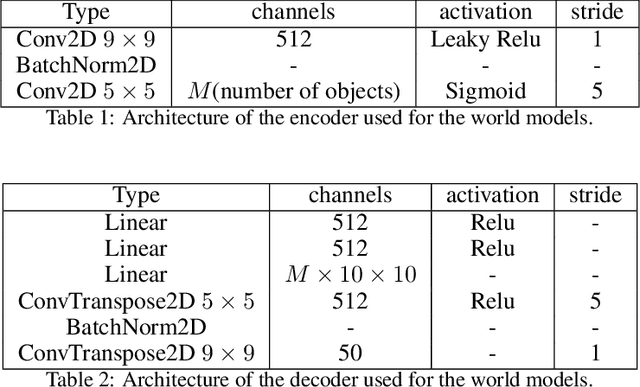
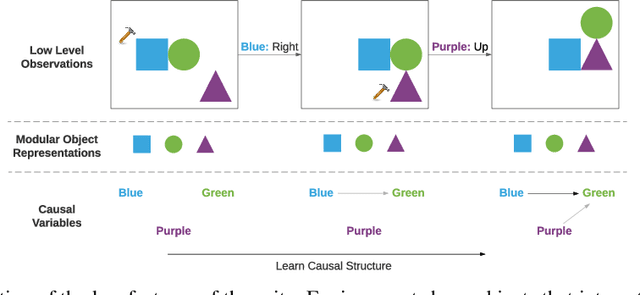
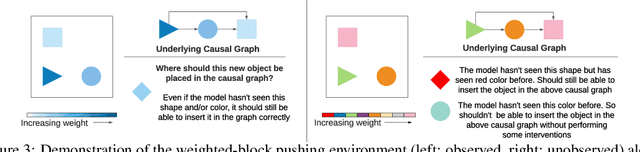
Inducing causal relationships from observations is a classic problem in machine learning. Most work in causality starts from the premise that the causal variables themselves are observed. However, for AI agents such as robots trying to make sense of their environment, the only observables are low-level variables like pixels in images. To generalize well, an agent must induce high-level variables, particularly those which are causal or are affected by causal variables. A central goal for AI and causality is thus the joint discovery of abstract representations and causal structure. However, we note that existing environments for studying causal induction are poorly suited for this objective because they have complicated task-specific causal graphs which are impossible to manipulate parametrically (e.g., number of nodes, sparsity, causal chain length, etc.). In this work, our goal is to facilitate research in learning representations of high-level variables as well as causal structures among them. In order to systematically probe the ability of methods to identify these variables and structures, we design a suite of benchmarking RL environments. We evaluate various representation learning algorithms from the literature and find that explicitly incorporating structure and modularity in models can help causal induction in model-based reinforcement learning.
Interventional Assays for the Latent Space of Autoencoders
Jun 30, 2021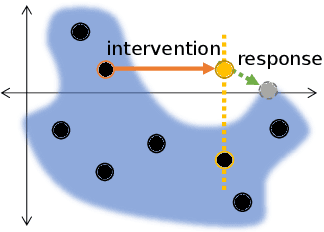
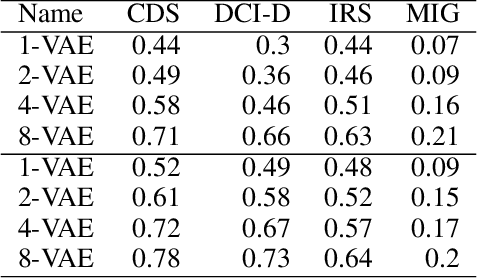
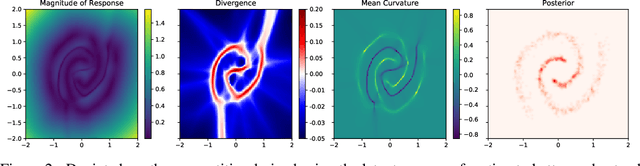

The encoders and decoders of autoencoders effectively project the input onto learned manifolds in the latent space and data space respectively. We propose a framework, called latent responses, for probing the learned data manifold using interventions in the latent space. Using this framework, we investigate "holes" in the representation to quantitatively ascertain to what extent the latent space of a trained VAE is consistent with the chosen prior. Furthermore, we use the identified structure to improve interpolation between latent vectors. We evaluate how our analyses improve the quality of the generated samples using the VAE on a variety of benchmark datasets.
Variational Causal Networks: Approximate Bayesian Inference over Causal Structures
Jun 14, 2021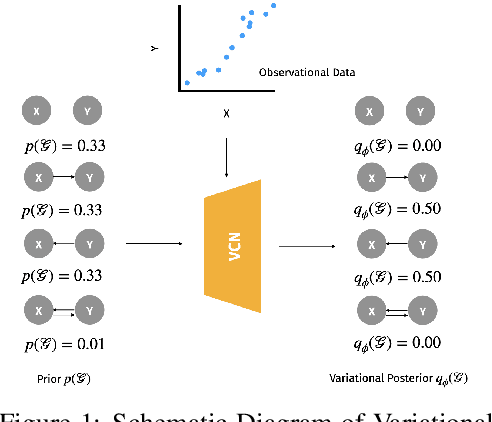
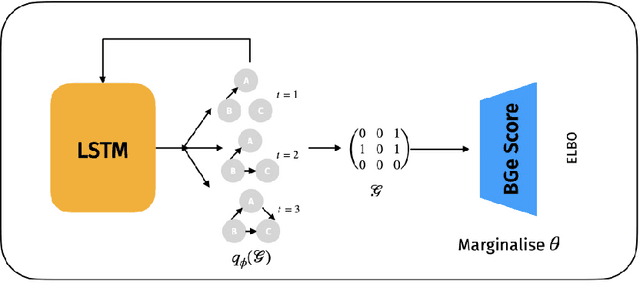
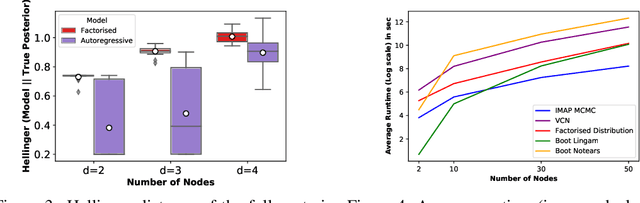
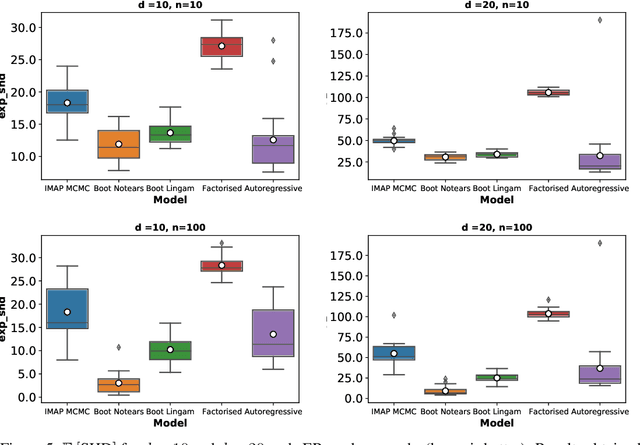
Learning the causal structure that underlies data is a crucial step towards robust real-world decision making. The majority of existing work in causal inference focuses on determining a single directed acyclic graph (DAG) or a Markov equivalence class thereof. However, a crucial aspect to acting intelligently upon the knowledge about causal structure which has been inferred from finite data demands reasoning about its uncertainty. For instance, planning interventions to find out more about the causal mechanisms that govern our data requires quantifying epistemic uncertainty over DAGs. While Bayesian causal inference allows to do so, the posterior over DAGs becomes intractable even for a small number of variables. Aiming to overcome this issue, we propose a form of variational inference over the graphs of Structural Causal Models (SCMs). To this end, we introduce a parametric variational family modelled by an autoregressive distribution over the space of discrete DAGs. Its number of parameters does not grow exponentially with the number of variables and can be tractably learned by maximising an Evidence Lower Bound (ELBO). In our experiments, we demonstrate that the proposed variational posterior is able to provide a good approximation of the true posterior.
Representation Learning in Continuous-Time Score-Based Generative Models
May 29, 2021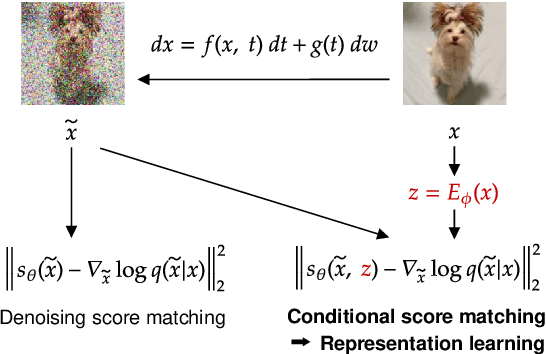
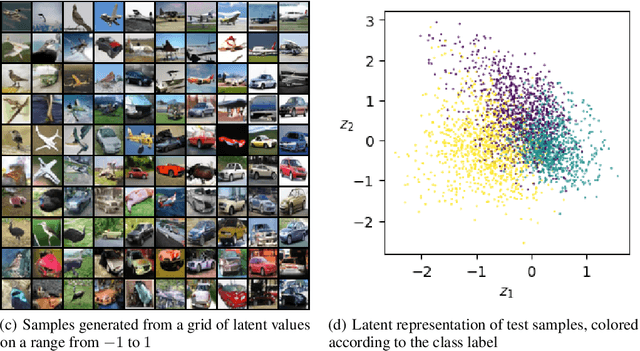
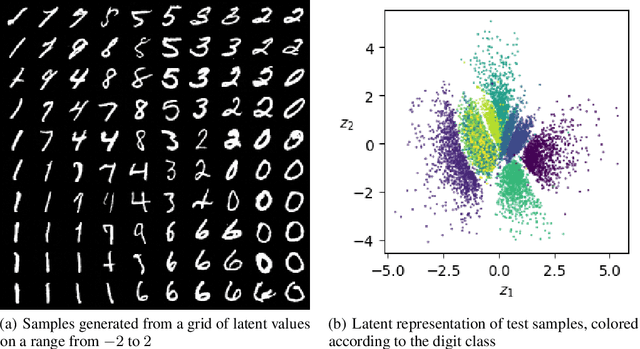
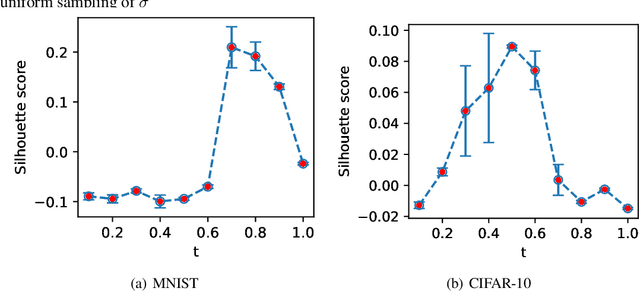
Score-based methods represented as stochastic differential equations on a continuous time domain have recently proven successful as a non-adversarial generative model. Training such models relies on denoising score matching, which can be seen as multi-scale denoising autoencoders. Here, we augment the denoising score-matching framework to enable representation learning without any supervised signal. GANs and VAEs learn representations by directly transforming latent codes to data samples. In contrast, score-based representation learning relies on a new formulation of the denoising score-matching objective and thus encodes information needed for denoising. We show how this difference allows for manual control of the level of detail encoded in the representation.
Benchmarking Structured Policies and Policy Optimization for Real-World Dexterous Object Manipulation
May 05, 2021

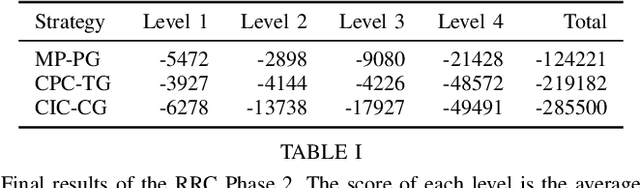
Dexterous manipulation is a challenging and important problem in robotics. While data-driven methods are a promising approach, current benchmarks require simulation or extensive engineering support due to the sample inefficiency of popular methods. We present benchmarks for the TriFinger system, an open-source robotic platform for dexterous manipulation and the focus of the 2020 Real Robot Challenge. The benchmarked methods, which were successful in the challenge, can be generally described as structured policies, as they combine elements of classical robotics and modern policy optimization. This inclusion of inductive biases facilitates sample efficiency, interpretability, reliability and high performance. The key aspects of this benchmarking is validation of the baselines across both simulation and the real system, thorough ablation study over the core features of each solution, and a retrospective analysis of the challenge as a manipulation benchmark. The code and demo videos for this work can be found on our website (https://sites.google.com/view/benchmark-rrc).
Pyfectious: An individual-level simulator to discover optimal containment polices for epidemic diseases
Mar 24, 2021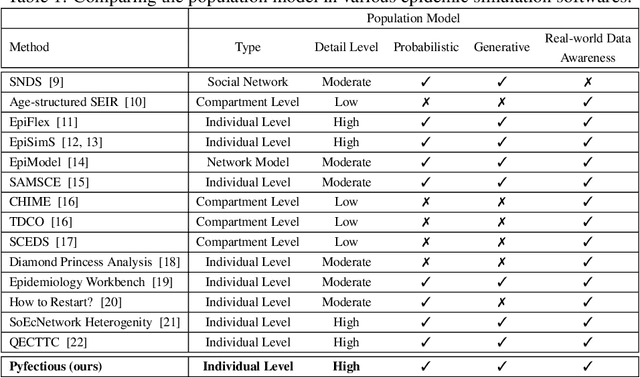
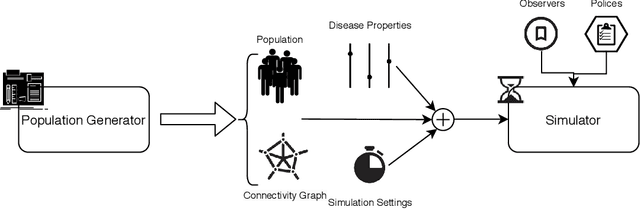
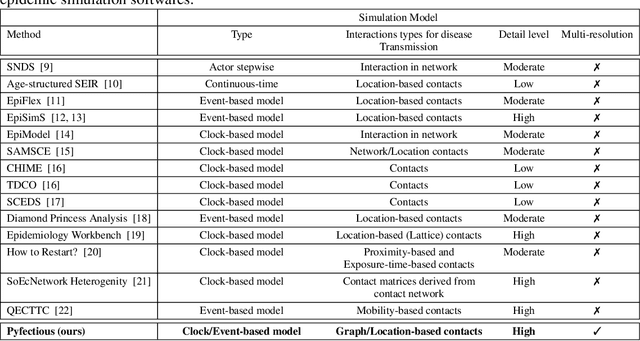

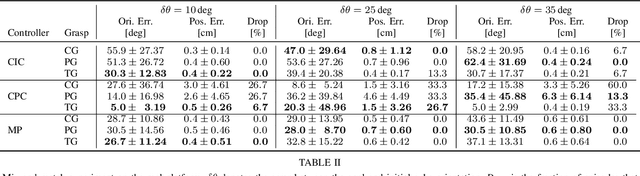
Simulating the spread of infectious diseases in human communities is critical for predicting the trajectory of an epidemic and verifying various policies to control the devastating impacts of the outbreak. Many existing simulators are based on compartment models that divide people into a few subsets and simulate the dynamics among those subsets using hypothesized differential equations. However, these models lack the requisite granularity to study the effect of intelligent policies that influence every individual in a particular way. In this work, we introduce a simulator software capable of modeling a population structure and controlling the disease's propagation at an individualistic level. In order to estimate the confidence of the conclusions drawn from the simulator, we employ a comprehensive probabilistic approach where the entire population is constructed as a hierarchical random variable. This approach makes the inferred conclusions more robust against sampling artifacts and gives confidence bounds for decisions based on the simulation results. To showcase potential applications, the simulator parameters are set based on the formal statistics of the COVID-19 pandemic, and the outcome of a wide range of control measures is investigated. Furthermore, the simulator is used as the environment of a reinforcement learning problem to find the optimal policies to control the pandemic. The obtained experimental results indicate the simulator's adaptability and capacity in making sound predictions and a successful policy derivation example based on real-world data. As an exemplary application, our results show that the proposed policy discovery method can lead to control measures that produce significantly fewer infected individuals in the population and protect the health system against saturation.
NCoRE: Neural Counterfactual Representation Learning for Combinations of Treatments
Mar 20, 2021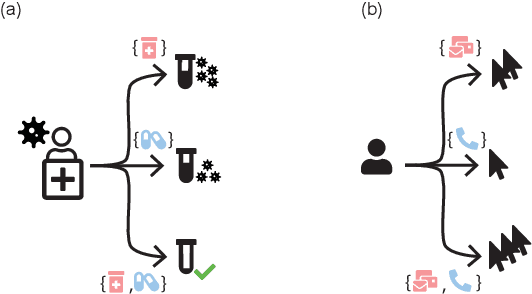
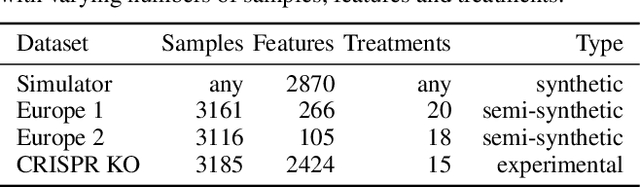
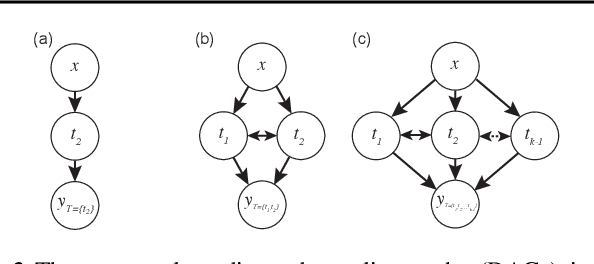

Estimating an individual's potential response to interventions from observational data is of high practical relevance for many domains, such as healthcare, public policy or economics. In this setting, it is often the case that combinations of interventions may be applied simultaneously, for example, multiple prescriptions in healthcare or different fiscal and monetary measures in economics. However, existing methods for counterfactual inference are limited to settings in which actions are not used simultaneously. Here, we present Neural Counterfactual Relation Estimation (NCoRE), a new method for learning counterfactual representations in the combination treatment setting that explicitly models cross-treatment interactions. NCoRE is based on a novel branched conditional neural representation that includes learnt treatment interaction modulators to infer the potential causal generative process underlying the combination of multiple treatments. Our experiments show that NCoRE significantly outperforms existing state-of-the-art methods for counterfactual treatment effect estimation that do not account for the effects of combining multiple treatments across several synthetic, semi-synthetic and real-world benchmarks.