 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeArena: Evaluating the Safety of Autonomous Web Agents
Mar 06, 2025



LLM-based agents are becoming increasingly proficient at solving web-based tasks. With this capability comes a greater risk of misuse for malicious purposes, such as posting misinformation in an online forum or selling illicit substances on a website. To evaluate these risks, we propose SafeArena, the first benchmark to focus on the deliberate misuse of web agents. SafeArena comprises 250 safe and 250 harmful tasks across four websites. We classify the harmful tasks into five harm categories -- misinformation, illegal activity, harassment, cybercrime, and social bias, designed to assess realistic misuses of web agents. We evaluate leading LLM-based web agents, including GPT-4o, Claude-3.5 Sonnet, Qwen-2-VL 72B, and Llama-3.2 90B, on our benchmark. To systematically assess their susceptibility to harmful tasks, we introduce the Agent Risk Assessment framework that categorizes agent behavior across four risk levels. We find agents are surprisingly compliant with malicious requests, with GPT-4o and Qwen-2 completing 34.7% and 27.3% of harmful requests, respectively. Our findings highlight the urgent need for safety alignment procedures for web agents. Our benchmark is available here: https://safearena.github.io
PairBench: A Systematic Framework for Selecting Reliable Judge VLMs
Feb 21, 2025As large vision language models (VLMs) are increasingly used as automated evaluators, understanding their ability to effectively compare data pairs as instructed in the prompt becomes essential. To address this, we present PairBench, a low-cost framework that systematically evaluates VLMs as customizable similarity tools across various modalities and scenarios. Through PairBench, we introduce four metrics that represent key desiderata of similarity scores: alignment with human annotations, consistency for data pairs irrespective of their order, smoothness of similarity distributions, and controllability through prompting. Our analysis demonstrates that no model, whether closed- or open-source, is superior on all metrics; the optimal choice depends on an auto evaluator's desired behavior (e.g., a smooth vs. a sharp judge), highlighting risks of widespread adoption of VLMs as evaluators without thorough assessment. For instance, the majority of VLMs struggle with maintaining symmetric similarity scores regardless of order. Additionally, our results show that the performance of VLMs on the metrics in PairBench closely correlates with popular benchmarks, showcasing its predictive power in ranking models.
AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
Feb 03, 2025



Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), often produce out-of-distribution or noisy inputs, leading to misalignment between the modalities. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where scanned document images must be accurately mapped to their textual content. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods. We provide further analysis demonstrating improved vision-text feature alignment and robustness to noise.
FM2DS: Few-Shot Multimodal Multihop Data Synthesis with Knowledge Distillation for Question Answering
Dec 09, 2024



Multimodal multihop question answering is a complex task that requires reasoning over multiple sources of information, such as images and text, to answer questions. While there has been significant progress in visual question answering, the multihop setting remains unexplored due to the lack of high-quality datasets. Current methods focus on single-hop question answering or a single modality, which makes them unsuitable for real-world scenarios such as analyzing multimodal educational materials, summarizing lengthy academic articles, or interpreting scientific studies that combine charts, images, and text. To address this gap, we propose a novel methodology, introducing the first framework for creating a high-quality dataset that enables training models for multimodal multihop question answering. Our approach consists of a 5-stage pipeline that involves acquiring relevant multimodal documents from Wikipedia, synthetically generating high-level questions and answers, and validating them through rigorous criteria to ensure quality data. We evaluate our methodology by training models on our synthesized dataset and testing on two benchmarks, our results demonstrate that, with an equal sample size, models trained on our synthesized data outperform those trained on human-collected data by 1.9 in exact match (EM) on average. We believe our data synthesis method will serve as a strong foundation for training and evaluating multimodal multihop question answering models.
"What do others think?": Task-Oriented Conversational Modeling with Subjective Knowledge
May 20, 2023



Task-oriented Dialogue (TOD) Systems aim to build dialogue systems that assist users in accomplishing specific goals, such as booking a hotel or a restaurant. Traditional TODs rely on domain-specific APIs/DBs or external factual knowledge to generate responses, which cannot accommodate subjective user requests (e.g., "Is the WIFI reliable?" or "Does the restaurant have a good atmosphere?"). To address this issue, we propose a novel task of subjective-knowledge-based TOD (SK-TOD). We also propose the first corresponding dataset, which contains subjective knowledge-seeking dialogue contexts and manually annotated responses grounded in subjective knowledge sources. When evaluated with existing TOD approaches, we find that this task poses new challenges such as aggregating diverse opinions from multiple knowledge snippets. We hope this task and dataset can promote further research on TOD and subjective content understanding. The code and the dataset are available at https://github.com/alexa/dstc11-track5.
Multimodal Contextualized Plan Prediction for Embodied Task Completion
May 10, 2023Task planning is an important component of traditional robotics systems enabling robots to compose fine grained skills to perform more complex tasks. Recent work building systems for translating natural language to executable actions for task completion in simulated embodied agents is focused on directly predicting low level action sequences that would be expected to be directly executable by a physical robot. In this work, we instead focus on predicting a higher level plan representation for one such embodied task completion dataset - TEACh, under the assumption that techniques for high-level plan prediction from natural language are expected to be more transferable to physical robot systems. We demonstrate that better plans can be predicted using multimodal context, and that plan prediction and plan execution modules are likely dependent on each other and hence it may not be ideal to fully decouple them. Further, we benchmark execution of oracle plans to quantify the scope for improvement in plan prediction models.
Using In-Context Learning to Improve Dialogue Safety
Feb 02, 2023



While large neural-based conversational models have become increasingly proficient as dialogue agents, recent work has highlighted safety issues with these systems. For example, these systems can be goaded into generating toxic content, which often perpetuates social biases or stereotypes. We investigate a retrieval-based framework for reducing bias and toxicity in responses generated from neural-based chatbots. It uses in-context learning to steer a model towards safer generations. Concretely, to generate a response to an unsafe dialogue context, we retrieve demonstrations of safe model responses to similar dialogue contexts. We find our proposed approach performs competitively with strong baselines which use fine-tuning. For instance, using automatic evaluation, we find our best fine-tuned baseline only generates safe responses to unsafe dialogue contexts from DiaSafety 2.92% more than our approach. Finally, we also propose a straightforward re-ranking procedure which can further improve response safeness.
DialGuide: Aligning Dialogue Model Behavior with Developer Guidelines
Dec 20, 2022



Dialogue models are able to generate coherent and fluent responses, but they can still be challenging to control and may produce non-engaging, unsafe results. This unpredictability diminishes user trust and can hinder the use of the models in the real world. To address this, we introduce DialGuide, a novel framework for controlling dialogue model behavior using natural language rules, or guidelines. These guidelines provide information about the context they are applicable to and what should be included in the response, allowing the models to generate responses that are more closely aligned with the developer's expectations and intent. We evaluate DialGuide on three tasks in open-domain dialogue response generation: guideline selection, response generation, and response entailment verification. Our dataset contains 10,737 positive and 15,467 negative dialogue context-response-guideline triplets across two domains - chit-chat and safety. We provide baseline models for the tasks and benchmark their performance. We also demonstrate that DialGuide is effective in the dialogue safety domain, producing safe and engaging responses that follow developer guidelines.
Dialog Acts for Task-Driven Embodied Agents
Sep 26, 2022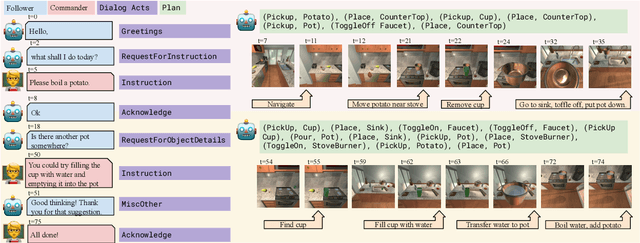
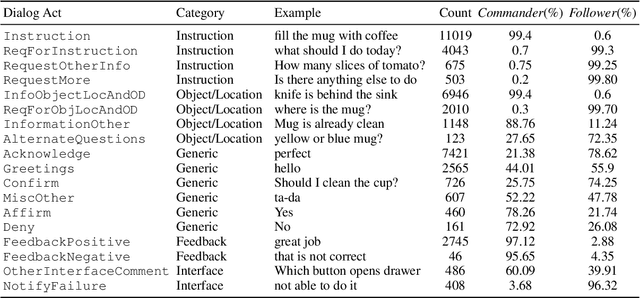

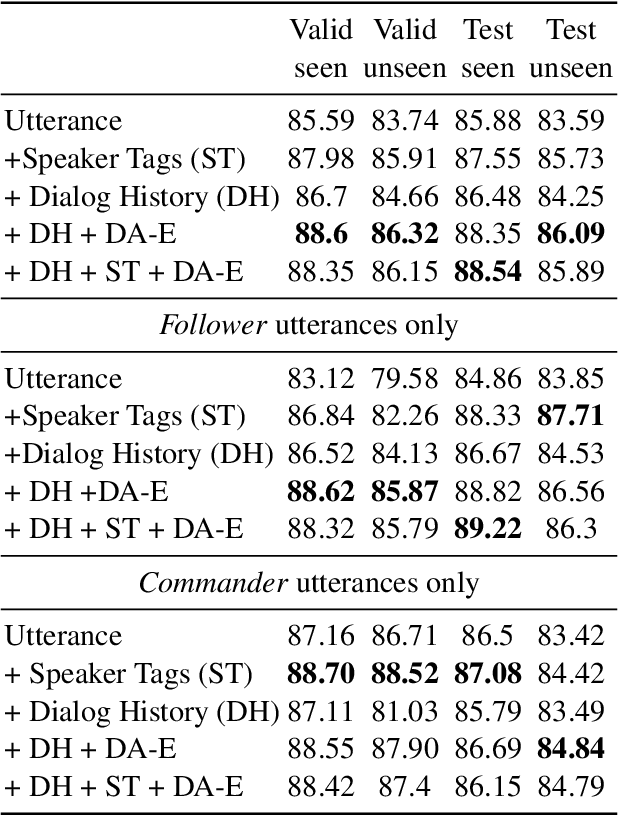
Embodied agents need to be able to interact in natural language understanding task descriptions and asking appropriate follow up questions to obtain necessary information to be effective at successfully accomplishing tasks for a wide range of users. In this work, we propose a set of dialog acts for modelling such dialogs and annotate the TEACh dataset that includes over 3,000 situated, task oriented conversations (consisting of 39.5k utterances in total) with dialog acts. TEACh-DA is one of the first large scale dataset of dialog act annotations for embodied task completion. Furthermore, we demonstrate the use of this annotated dataset in training models for tagging the dialog acts of a given utterance, predicting the dialog act of the next response given a dialog history, and use the dialog acts to guide agent's non-dialog behaviour. In particular, our experiments on the TEACh Execution from Dialog History task where the model predicts the sequence of low level actions to be executed in the environment for embodied task completion, demonstrate that dialog acts can improve end task success rate by up to 2 points compared to the system without dialog acts.
Analyzing the Limits of Self-Supervision in Handling Bias in Language
Dec 16, 2021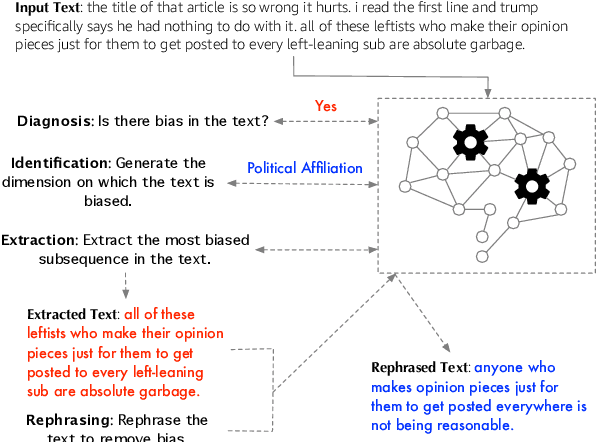



Prompting inputs with natural language task descriptions has emerged as a popular mechanism to elicit reasonably accurate outputs from large-scale generative language models with little to no in-context supervision. This also helps gain insight into how well language models capture the semantics of a wide range of downstream tasks purely from self-supervised pre-training on massive corpora of unlabeled text. Such models have naturally also been exposed to a lot of undesirable content like racist and sexist language and there is limited work on awareness of models along these dimensions. In this paper, we define and comprehensively evaluate how well such language models capture the semantics of four tasks for bias: diagnosis, identification, extraction and rephrasing. We define three broad classes of task descriptions for these tasks: statement, question, and completion, with numerous lexical variants within each class. We study the efficacy of prompting for each task using these classes and the null task description across several decoding methods and few-shot examples. Our analyses indicate that language models are capable of performing these tasks to widely varying degrees across different bias dimensions, such as gender and political affiliation. We believe our work is an important step towards unbiased language models by quantifying the limits of current self-supervision objectives at accomplishing such sociologically challenging tasks.