 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can we learn about a generated image corrupting its latent representation?
Oct 12, 2022Generative adversarial networks (GANs) offer an effective solution to the image-to-image translation problem, thereby allowing for new possibilities in medical imaging. They can translate images from one imaging modality to another at a low cost. For unpaired datasets, they rely mostly on cycle loss. Despite its effectiveness in learning the underlying data distribution, it can lead to a discrepancy between input and output data. The purpose of this work is to investigate the hypothesis that we can predict image quality based on its latent representation in the GANs bottleneck. We achieve this by corrupting the latent representation with noise and generating multiple outputs. The degree of differences between them is interpreted as the strength of the representation: the more robust the latent representation, the fewer changes in the output image the corruption causes. Our results demonstrate that our proposed method has the ability to i) predict uncertain parts of synthesized images, and ii) identify samples that may not be reliable for downstream tasks, e.g., liver segmentation task.
RIGA: Rotation-Invariant and Globally-Aware Descriptors for Point Cloud Registration
Sep 27, 2022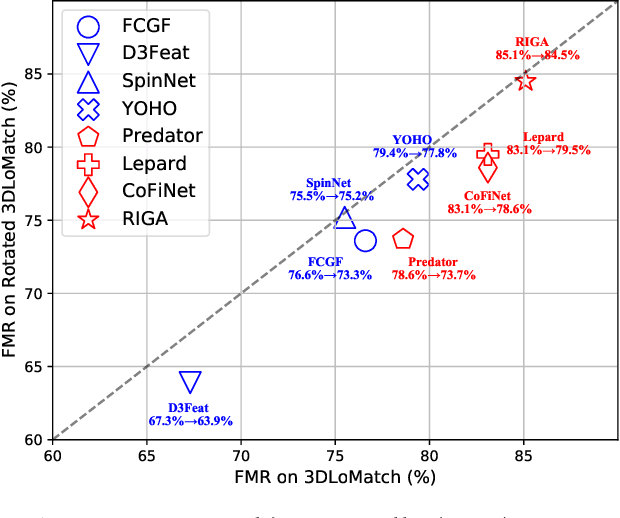
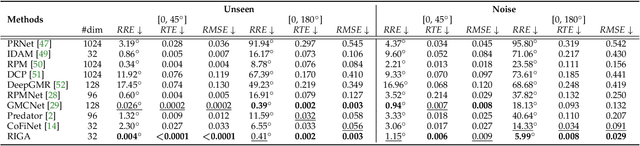
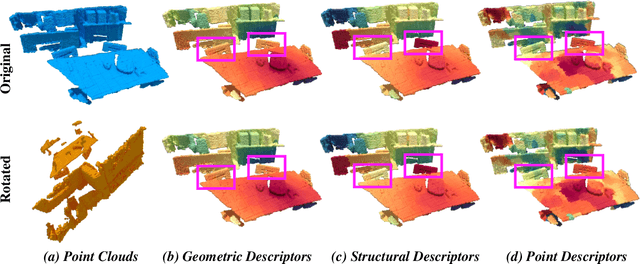
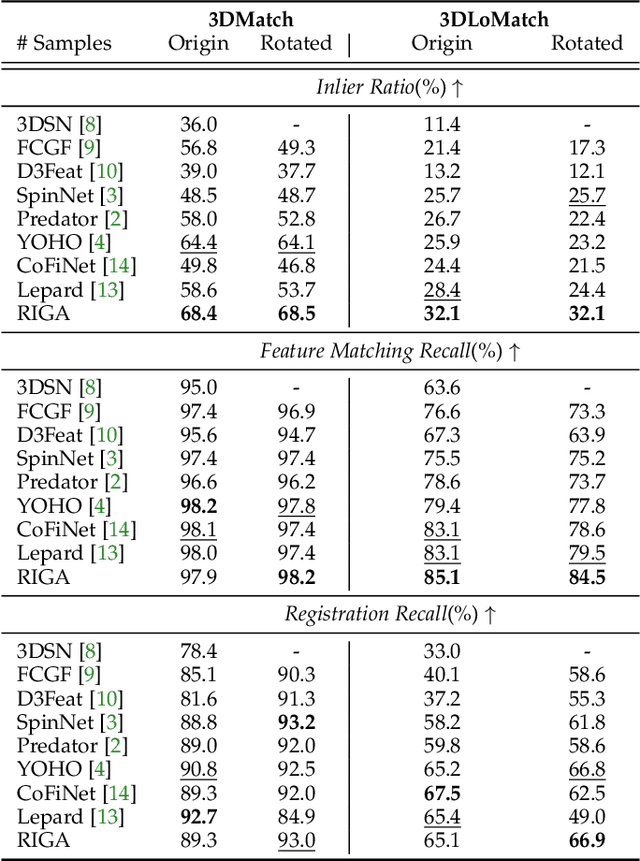
Successful point cloud registration relies on accurate correspondences established upon powerful descriptors. However, existing neural descriptors either leverage a rotation-variant backbone whose performance declines under large rotations, or encode local geometry that is less distinctive. To address this issue, we introduce RIGA to learn descriptors that are Rotation-Invariant by design and Globally-Aware. From the Point Pair Features (PPFs) of sparse local regions, rotation-invariant local geometry is encoded into geometric descriptors. Global awareness of 3D structures and geometric context is subsequently incorporated, both in a rotation-invariant fashion. More specifically, 3D structures of the whole frame are first represented by our global PPF signatures, from which structural descriptors are learned to help geometric descriptors sense the 3D world beyond local regions. Geometric context from the whole scene is then globally aggregated into descriptors. Finally, the description of sparse regions is interpolated to dense point descriptors, from which correspondences are extracted for registration. To validate our approach, we conduct extensive experiments on both object- and scene-level data. With large rotations, RIGA surpasses the state-of-the-art methods by a margin of 8\degree in terms of the Relative Rotation Error on ModelNet40 and improves the Feature Matching Recall by at least 5 percentage points on 3DLoMatch.
Multi-View Object Pose Refinement With Differentiable Renderer
Jul 06, 2022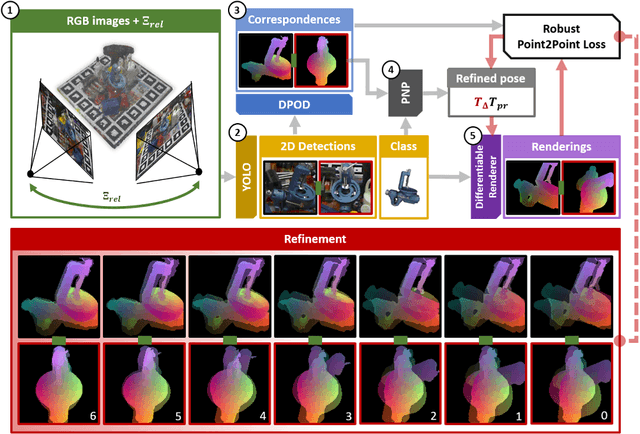


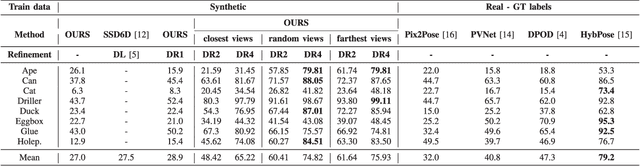
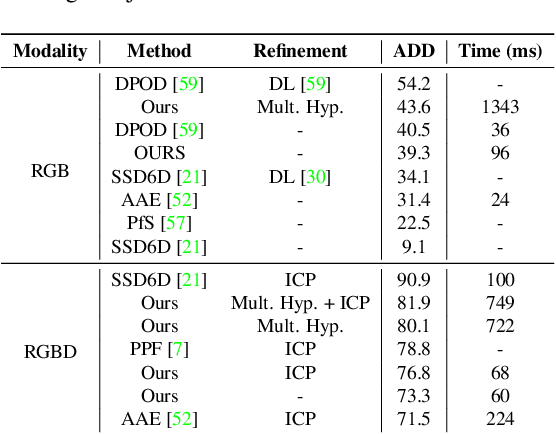
This paper introduces a novel multi-view 6 DoF object pose refinement approach focusing on improving methods trained on synthetic data. It is based on the DPOD detector, which produces dense 2D-3D correspondences between the model vertices and the image pixels in each frame. We have opted for the use of multiple frames with known relative camera transformations, as it allows introduction of geometrical constraints via an interpretable ICP-like loss function. The loss function is implemented with a differentiable renderer and is optimized iteratively. We also demonstrate that a full detection and refinement pipeline, which is trained solely on synthetic data, can be used for auto-labeling real data. We perform quantitative evaluation on LineMOD, Occlusion, Homebrewed and YCB-V datasets and report excellent performance in comparison to the state-of-the-art methods trained on the synthetic and real data. We demonstrate empirically that our approach requires only a few frames and is robust to close camera locations and noise in extrinsic camera calibration, making its practical usage easier and more ubiquitous.
DPODv2: Dense Correspondence-Based 6 DoF Pose Estimation
Jul 06, 2022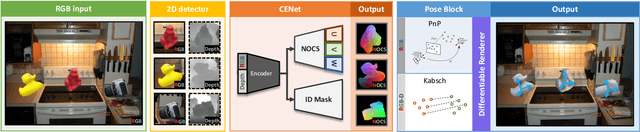
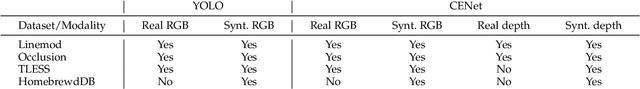
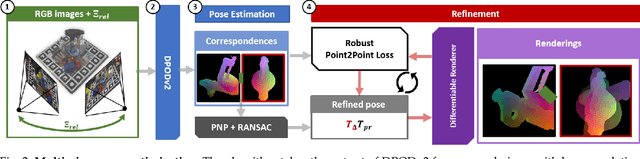
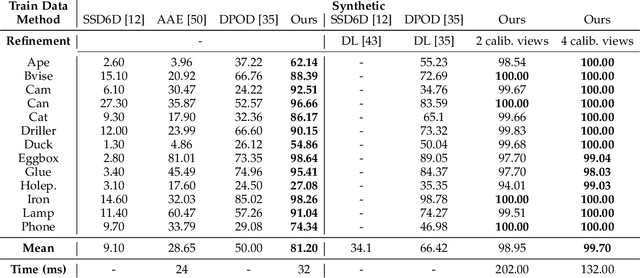
We propose a three-stage 6 DoF object detection method called DPODv2 (Dense Pose Object Detector) that relies on dense correspondences. We combine a 2D object detector with a dense correspondence estimation network and a multi-view pose refinement method to estimate a full 6 DoF pose. Unlike other deep learning methods that are typically restricted to monocular RGB images, we propose a unified deep learning network allowing different imaging modalities to be used (RGB or Depth). Moreover, we propose a novel pose refinement method, that is based on differentiable rendering. The main concept is to compare predicted and rendered correspondences in multiple views to obtain a pose which is consistent with predicted correspondences in all views. Our proposed method is evaluated rigorously on different data modalities and types of training data in a controlled setup. The main conclusions is that RGB excels in correspondence estimation, while depth contributes to the pose accuracy if good 3D-3D correspondences are available. Naturally, their combination achieves the overall best performance. We perform an extensive evaluation and an ablation study to analyze and validate the results on several challenging datasets. DPODv2 achieves excellent results on all of them while still remaining fast and scalable independent of the used data modality and the type of training data
Is my Depth Ground-Truth Good Enough? HAMMER -- Highly Accurate Multi-Modal Dataset for DEnse 3D Scene Regression
May 09, 2022


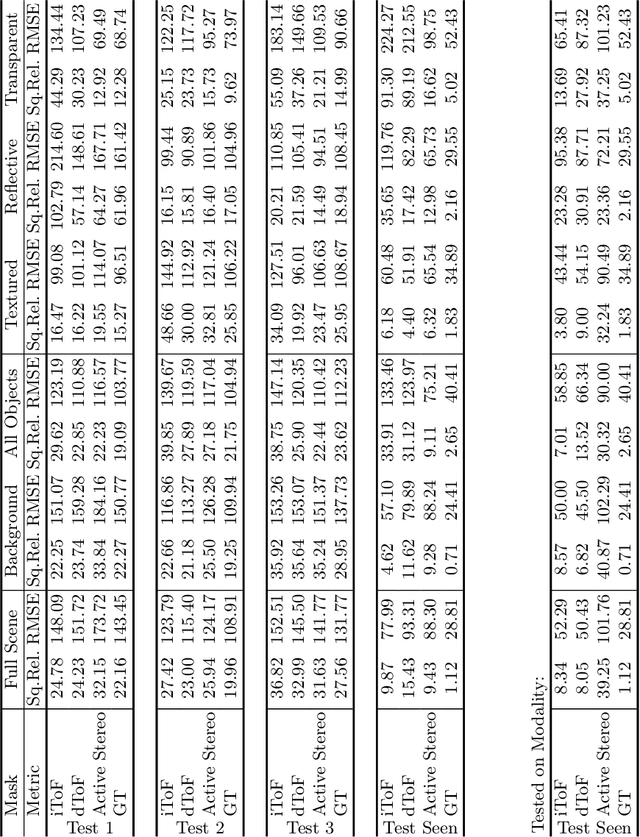
Depth estimation is a core task in 3D computer vision. Recent methods investigate the task of monocular depth trained with various depth sensor modalities. Every sensor has its advantages and drawbacks caused by the nature of estimates. In the literature, mostly mean average error of the depth is investigated and sensor capabilities are typically not discussed. Especially indoor environments, however, pose challenges for some devices. Textureless regions pose challenges for structure from motion, reflective materials are problematic for active sensing, and distances for translucent material are intricate to measure with existing sensors. This paper proposes HAMMER, a dataset comprising depth estimates from multiple commonly used sensors for indoor depth estimation, namely ToF, stereo, structured light together with monocular RGB+P data. We construct highly reliable ground truth depth maps with the help of 3D scanners and aligned renderings. A popular depth estimators is trained on this data and typical depth senosors. The estimates are extensively analyze on different scene structures. We notice generalization issues arising from various sensor technologies in household environments with challenging but everyday scene content. HAMMER, which we make publicly available, provides a reliable base to pave the way to targeted depth improvements and sensor fusion approaches.
OSOP: A Multi-Stage One Shot Object Pose Estimation Framework
Mar 30, 2022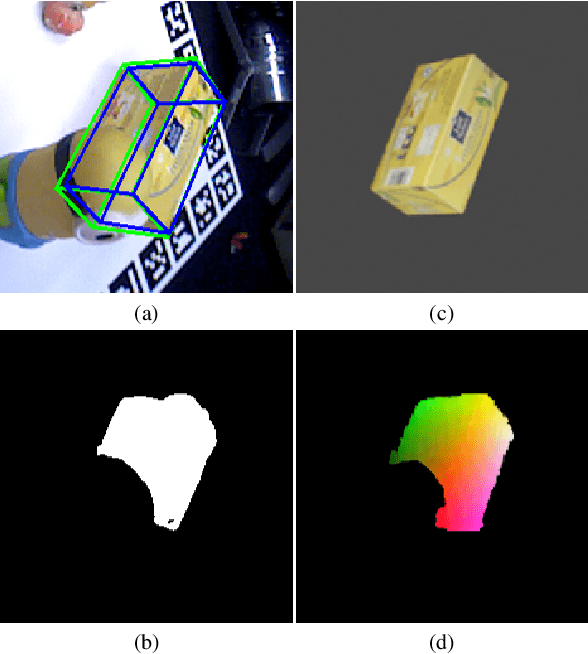
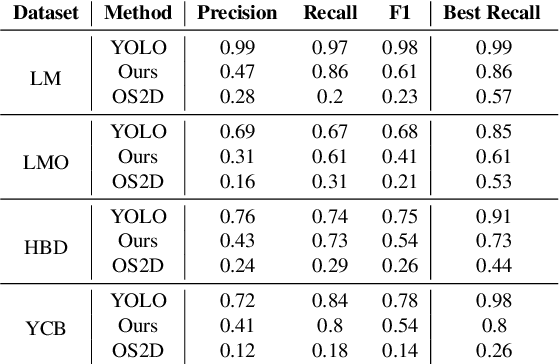
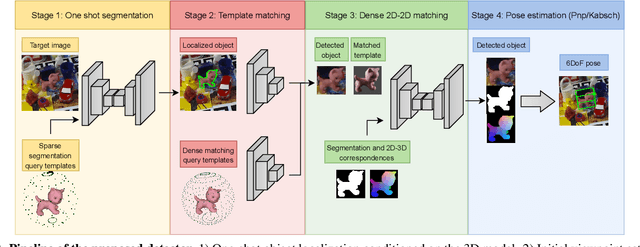
We present a novel one-shot method for object detection and 6 DoF pose estimation, that does not require training on target objects. At test time, it takes as input a target image and a textured 3D query model. The core idea is to represent a 3D model with a number of 2D templates rendered from different viewpoints. This enables CNN-based direct dense feature extraction and matching. The object is first localized in 2D, then its approximate viewpoint is estimated, followed by dense 2D-3D correspondence prediction. The final pose is computed with PnP. We evaluate the method on LineMOD, Occlusion, Homebrewed, YCB-V and TLESS datasets and report very competitive performance in comparison to the state-of-the-art methods trained on synthetic data, even though our method is not trained on the object models used for testing.
NeRF-Pose: A First-Reconstruct-Then-Regress Approach for Weakly-supervised 6D Object Pose Estimation
Mar 09, 2022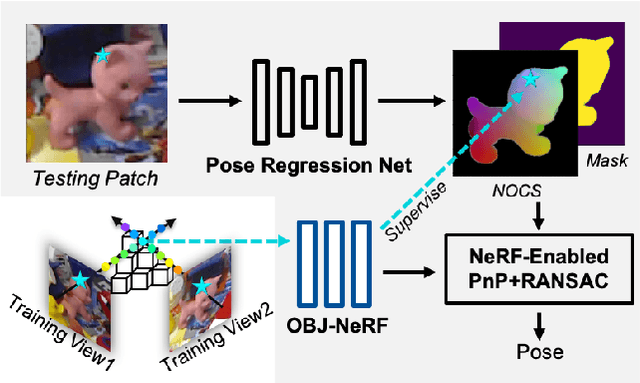
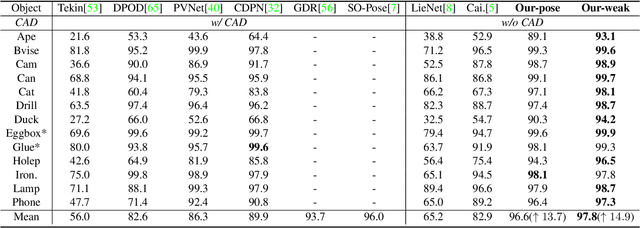
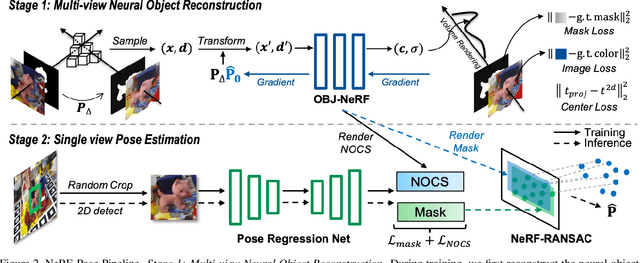
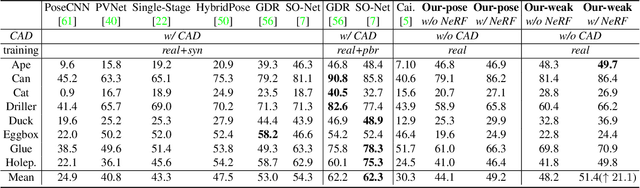
Pose estimation of 3D objects in monocular images is a fundamental and long-standing problem in computer vision. Existing deep learning approaches for 6D pose estimation typically rely on the assumption of availability of 3D object models and 6D pose annotations. However, precise annotation of 6D poses in real data is intricate, time-consuming and not scalable, while synthetic data scales well but lacks realism. To avoid these problems, we present a weakly-supervised reconstruction-based pipeline, named NeRF-Pose, which needs only 2D object segmentation and known relative camera poses during training. Following the first-reconstruct-then-regress idea, we first reconstruct the objects from multiple views in the form of an implicit neural representation. Then, we train a pose regression network to predict pixel-wise 2D-3D correspondences between images and the reconstructed model. At inference, the approach only needs a single image as input. A NeRF-enabled PnP+RANSAC algorithm is used to estimate stable and accurate pose from the predicted correspondences. Experiments on LineMod and LineMod-Occlusion show that the proposed method has state-of-the-art accuracy in comparison to the best 6D pose estimation methods in spite of being trained only with weak labels. Besides, we extend the Homebrewed DB dataset with more real training images to support the weakly supervised task and achieve compelling results on this dataset. The extended dataset and code will be released soon.
CoFiNet: Reliable Coarse-to-fine Correspondences for Robust Point Cloud Registration
Oct 26, 2021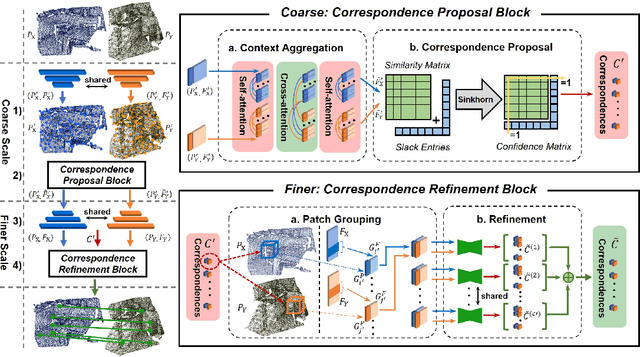
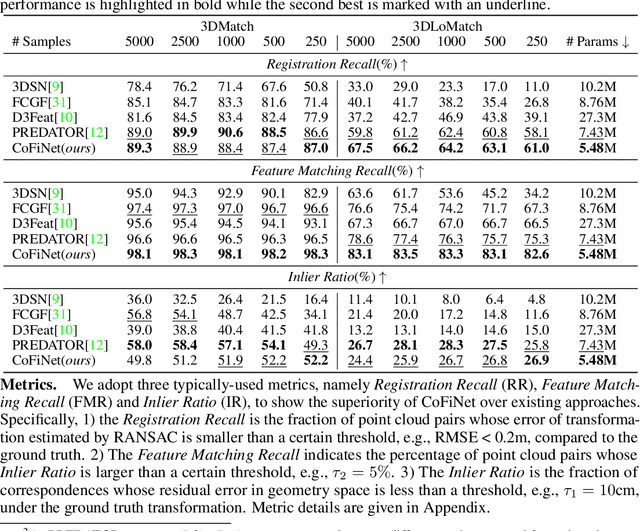
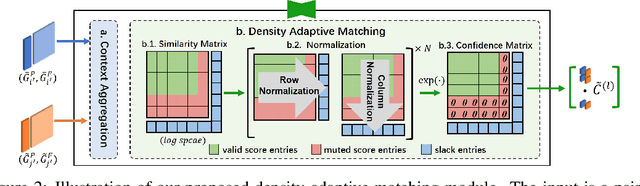
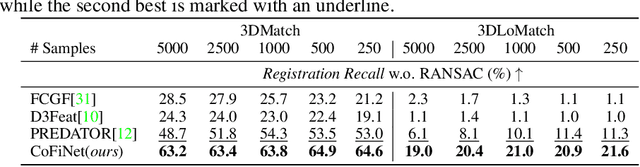
We study the problem of extracting correspondences between a pair of point clouds for registration. For correspondence retrieval, existing works benefit from matching sparse keypoints detected from dense points but usually struggle to guarantee their repeatability. To address this issue, we present CoFiNet - Coarse-to-Fine Network which extracts hierarchical correspondences from coarse to fine without keypoint detection. On a coarse scale and guided by a weighting scheme, our model firstly learns to match down-sampled nodes whose vicinity points share more overlap, which significantly shrinks the search space of a consecutive stage. On a finer scale, node proposals are consecutively expanded to patches that consist of groups of points together with associated descriptors. Point correspondences are then refined from the overlap areas of corresponding patches, by a density-adaptive matching module capable to deal with varying point density. Extensive evaluation of CoFiNet on both indoor and outdoor standard benchmarks shows our superiority over existing methods. Especially on 3DLoMatch where point clouds share less overlap, CoFiNet significantly outperforms state-of-the-art approaches by at least 5% on Registration Recall, with at most two-third of their parameters.
DistillPose: Lightweight Camera Localization Using Auxiliary Learning
Aug 09, 2021
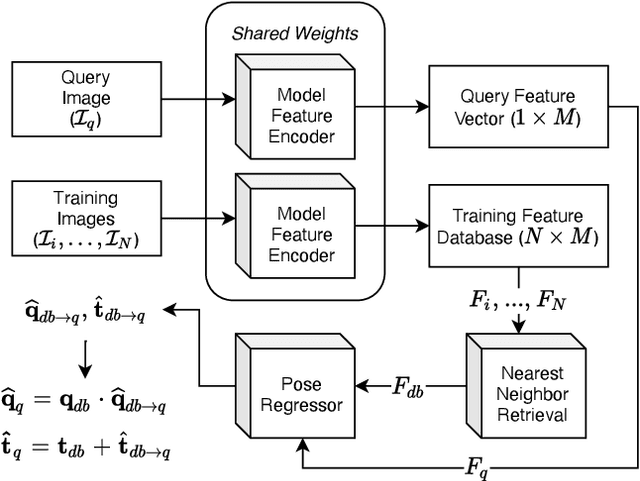
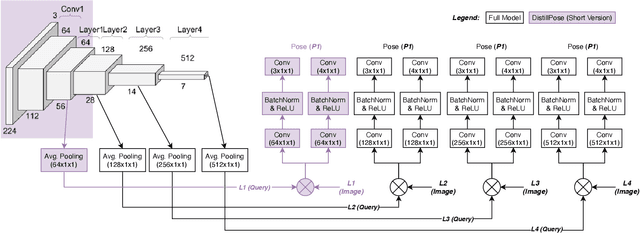
We propose a lightweight retrieval-based pipeline to predict 6DOF camera poses from RGB images. Our pipeline uses a convolutional neural network (CNN) to encode a query image as a feature vector. A nearest neighbor lookup finds the pose-wise nearest database image. A siamese convolutional neural network regresses the relative pose from the nearest neighboring database image to the query image. The relative pose is then applied to the nearest neighboring absolute pose to obtain the query image's final absolute pose prediction. Our model is a distilled version of NN-Net that reduces its parameters by 98.87%, information retrieval feature vector size by 87.5%, and inference time by 89.18% without a significant decrease in localization accuracy.
Deep Bingham Networks: Dealing with Uncertainty and Ambiguity in Pose Estimation
Dec 20, 2020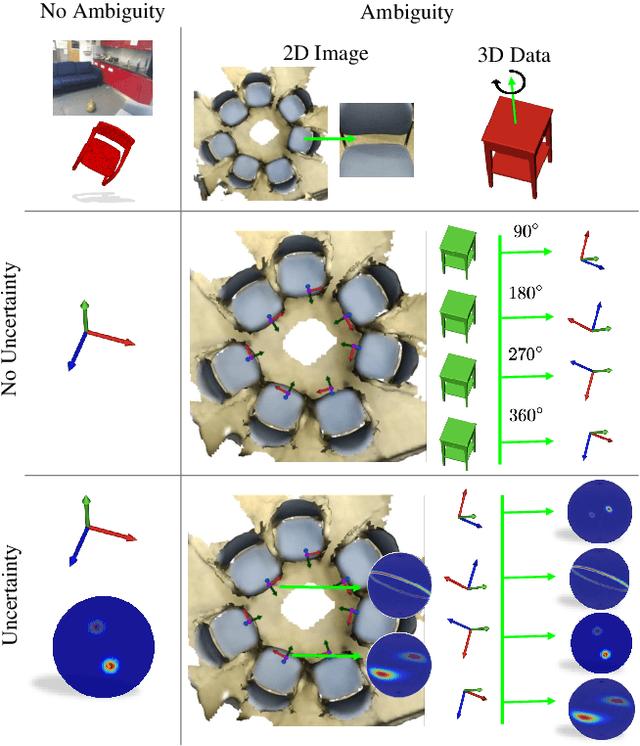

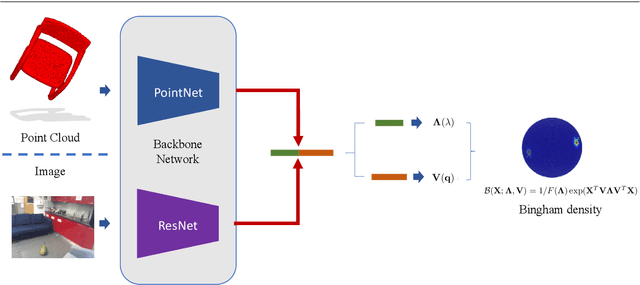
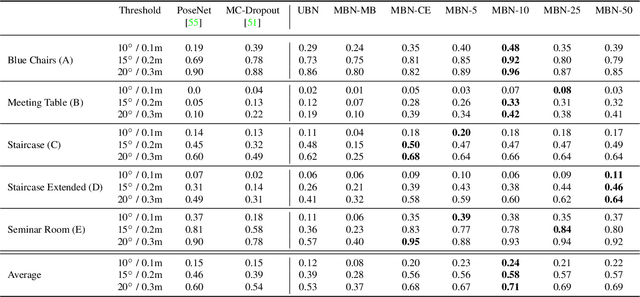
In this work, we introduce Deep Bingham Networks (DBN), a generic framework that can naturally handle pose-related uncertainties and ambiguities arising in almost all real life applications concerning 3D data. While existing works strive to find a single solution to the pose estimation problem, we make peace with the ambiguities causing high uncertainty around which solutions to identify as the best. Instead, we report a family of poses which capture the nature of the solution space. DBN extends the state of the art direct pose regression networks by (i) a multi-hypotheses prediction head which can yield different distribution modes; and (ii) novel loss functions that benefit from Bingham distributions on rotations. This way, DBN can work both in unambiguous cases providing uncertainty information, and in ambiguous scenes where an uncertainty per mode is desired. On a technical front, our network regresses continuous Bingham mixture models and is applicable to both 2D data such as images and to 3D data such as point clouds. We proposed new training strategies so as to avoid mode or posterior collapse during training and to improve numerical stability. Our methods are thoroughly tested on two different applications exploiting two different modalities: (i) 6D camera relocalization from images; and (ii) object pose estimation from 3D point clouds, demonstrating decent advantages over the state of the art. For the former we contributed our own dataset composed of five indoor scenes where it is unavoidable to capture images corresponding to views that are hard to uniquely identify. For the latter we achieve the top results especially for symmetric objects of ModelNet dataset.