 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem States Forecasting of Microservices with Dynamic Spatio-Temporal Data
Aug 15, 2024



In the AIOps (Artificial Intelligence for IT Operations) era, accurately forecasting system states is crucial. In microservices systems, this task encounters the challenge of dynamic and complex spatio-temporal relationships among microservice instances, primarily due to dynamic deployments, diverse call paths, and cascading effects among instances. Current time-series forecasting methods, which focus mainly on intrinsic patterns, are insufficient in environments where spatial relationships are critical. Similarly, spatio-temporal graph approaches often neglect the nature of temporal trend, concentrating mostly on message passing between nodes. Moreover, current research in microservices domain frequently underestimates the importance of network metrics and topological structures in capturing the evolving dynamics of systems. This paper introduces STMformer, a model tailored for forecasting system states in microservices environments, capable of handling multi-node and multivariate time series. Our method leverages dynamic network connection data and topological information to assist in modeling the intricate spatio-temporal relationships within the system. Additionally, we integrate the PatchCrossAttention module to compute the impact of cascading effects globally. We have developed a dataset based on a microservices system and conducted comprehensive experiments with STMformer against leading methods. In both short-term and long-term forecasting tasks, our model consistently achieved a 8.6% reduction in MAE(Mean Absolute Error) and a 2.2% reduction in MSE (Mean Squared Error). The source code is available at https://github.com/xuyifeiiie/STMformer.
Bootstrapping Vision-language Models for Self-supervised Remote Physiological Measurement
Jul 11, 2024



Facial video-based remote physiological measurement is a promising research area for detecting human vital signs (e.g., heart rate, respiration frequency) in a non-contact way. Conventional approaches are mostly supervised learning, requiring extensive collections of facial videos and synchronously recorded photoplethysmography (PPG) signals. To tackle it, self-supervised learning has recently gained attentions; due to the lack of ground truth PPG signals, its performance is however limited. In this paper, we propose a novel self-supervised framework that successfully integrates the popular vision-language models (VLMs) into the remote physiological measurement task. Given a facial video, we first augment its positive and negative video samples with varying rPPG signal frequencies. Next, we introduce a frequency-oriented vision-text pair generation method by carefully creating contrastive spatio-temporal maps from positive and negative samples and designing proper text prompts to describe their relative ratios of signal frequencies. A pre-trained VLM is employed to extract features for these formed vision-text pairs and estimate rPPG signals thereafter. We develop a series of generative and contrastive learning mechanisms to optimize the VLM, including the text-guided visual map reconstruction task, the vision-text contrastive learning task, and the frequency contrastive and ranking task. Overall, our method for the first time adapts VLMs to digest and align the frequency-related knowledge in vision and text modalities. Extensive experiments on four benchmark datasets demonstrate that it significantly outperforms state of the art self-supervised methods.
Self-supervised Gait-based Emotion Representation Learning from Selective Strongly Augmented Skeleton Sequences
May 08, 2024



Emotion recognition is an important part of affective computing. Extracting emotional cues from human gaits yields benefits such as natural interaction, a nonintrusive nature, and remote detection. Recently, the introduction of self-supervised learning techniques offers a practical solution to the issues arising from the scarcity of labeled data in the field of gait-based emotion recognition. However, due to the limited diversity of gaits and the incompleteness of feature representations for skeletons, the existing contrastive learning methods are usually inefficient for the acquisition of gait emotions. In this paper, we propose a contrastive learning framework utilizing selective strong augmentation (SSA) for self-supervised gait-based emotion representation, which aims to derive effective representations from limited labeled gait data. First, we propose an SSA method for the gait emotion recognition task, which includes upper body jitter and random spatiotemporal mask. The goal of SSA is to generate more diverse and targeted positive samples and prompt the model to learn more distinctive and robust feature representations. Then, we design a complementary feature fusion network (CFFN) that facilitates the integration of cross-domain information to acquire topological structural and global adaptive features. Finally, we implement the distributional divergence minimization loss to supervise the representation learning of the generally and strongly augmented queries. Our approach is validated on the Emotion-Gait (E-Gait) and Emilya datasets and outperforms the state-of-the-art methods under different evaluation protocols.
Integrity and Junkiness Failure Handling for Embedding-based Retrieval: A Case Study in Social Network Search
Apr 18, 2023


Embedding based retrieval has seen its usage in a variety of search applications like e-commerce, social networking search etc. While the approach has demonstrated its efficacy in tasks like semantic matching and contextual search, it is plagued by the problem of uncontrollable relevance. In this paper, we conduct an analysis of embedding-based retrieval launched in early 2021 on our social network search engine, and define two main categories of failures introduced by it, integrity and junkiness. The former refers to issues such as hate speech and offensive content that can severely harm user experience, while the latter includes irrelevant results like fuzzy text matching or language mismatches. Efficient methods during model inference are further proposed to resolve the issue, including indexing treatments and targeted user cohort treatments, etc. Though being simple, we show the methods have good offline NDCG and online A/B tests metrics gain in practice. We analyze the reasons for the improvements, pointing out that our methods are only preliminary attempts to this important but challenging problem. We put forward potential future directions to explore.
A Multimodal Data-driven Framework for Anxiety Screening
Mar 16, 2023Early screening for anxiety and appropriate interventions are essential to reduce the incidence of self-harm and suicide in patients. Due to limited medical resources, traditional methods that overly rely on physician expertise and specialized equipment cannot simultaneously meet the needs for high accuracy and model interpretability. Multimodal data can provide more objective evidence for anxiety screening to improve the accuracy of models. The large amount of noise in multimodal data and the unbalanced nature of the data make the model prone to overfitting. However, it is a non-differentiable problem when high-dimensional and multimodal feature combinations are used as model inputs and incorporated into model training. This causes existing anxiety screening methods based on machine learning and deep learning to be inapplicable. Therefore, we propose a multimodal data-driven anxiety screening framework, namely MMD-AS, and conduct experiments on the collected health data of over 200 seafarers by smartphones. The proposed framework's feature extraction, dimension reduction, feature selection, and anxiety inference are jointly trained to improve the model's performance. In the feature selection step, a feature selection method based on the Improved Fireworks Algorithm is used to solve the non-differentiable problem of feature combination to remove redundant features and search for the ideal feature subset. The experimental results show that our framework outperforms the comparison methods.
Video-based Remote Physiological Measurement via Self-supervised Learning
Oct 28, 2022



Video-based remote physiological measurement aims to estimate remote photoplethysmography (rPPG) signals from human face videos and then measure multiple vital signs (e.g. heart rate, respiration frequency) from rPPG signals. Recent approaches achieve it by training deep neural networks, which normally require abundant face videos and synchronously recorded photoplethysmography (PPG) signals for supervision. However, the collection of these annotated corpora is uneasy in practice. In this paper, we introduce a novel frequency-inspired self-supervised framework that learns to estimate rPPG signals from face videos without the need of ground truth PPG signals. Given a video sample, we first augment it into multiple positive/negative samples which contain similar/dissimilar signal frequencies to the original one. Specifically, positive samples are generated using spatial augmentation. Negative samples are generated via a learnable frequency augmentation module, which performs non-linear signal frequency transformation on the input without excessively changing its visual appearance. Next, we introduce a local rPPG expert aggregation module to estimate rPPG signals from augmented samples. It encodes complementary pulsation information from different face regions and aggregate them into one rPPG prediction. Finally, we propose a series of frequency-inspired losses, i.e. frequency contrastive loss, frequency ratio consistency loss, and cross-video frequency agreement loss, for the optimization of estimated rPPG signals from multiple augmented video samples and across temporally neighboring video samples. We conduct rPPG-based heart rate, heart rate variability and respiration frequency estimation on four standard benchmarks. The experimental results demonstrate that our method improves the state of the art by a large margin.
SFF-DA: Sptialtemporal Feature Fusion for Detecting Anxiety Nonintrusively
Aug 12, 2022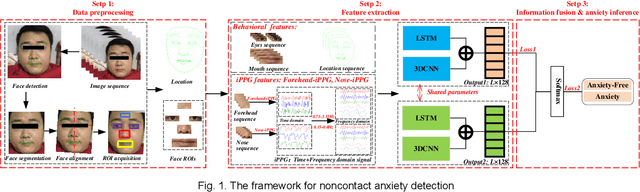
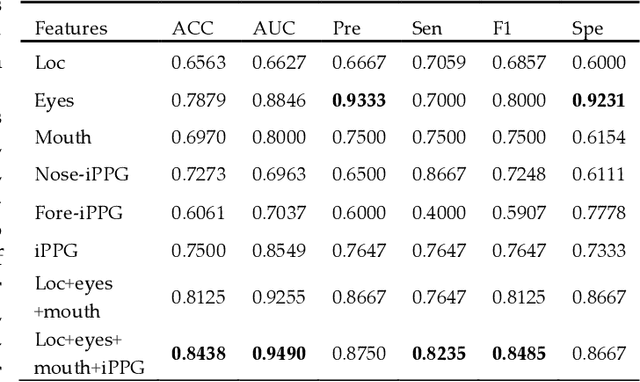
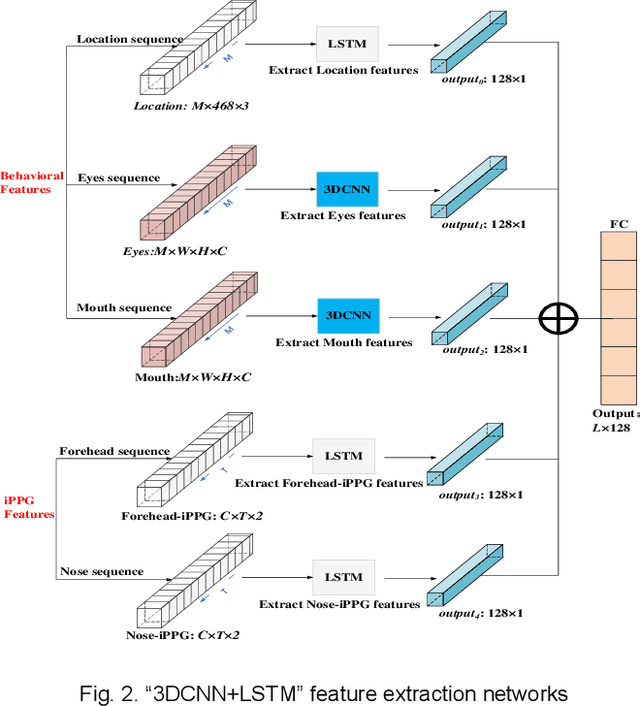
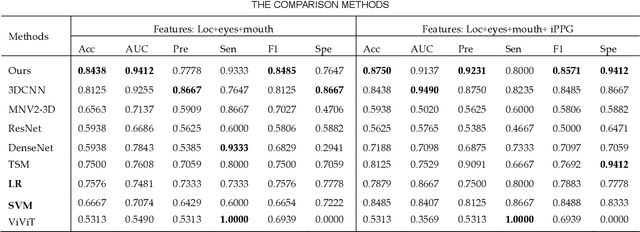
Early detection of anxiety disorders is essential to reduce the suffering of people with mental disorders and to improve treatment outcomes. Anxiety screening based on the mHealth platform is of particular practical value in improving screening efficiency and reducing screening costs. In practice, differences in mobile devices in subjects' physical and mental evaluations and the problems faced with uneven data quality and small sample sizes of data in the real world have made existing methods ineffective. Therefore, we propose a framework based on spatiotemporal feature fusion for detecting anxiety nonintrusively. To reduce the impact of uneven data quality, we constructed a feature extraction network based on "3DCNN+LSTM" and fused spatiotemporal features of facial behavior and noncontact physiology. Moreover, we designed a similarity assessment strategy to solve the problem that the small sample size of data leads to a decline in model accuracy. Our framework was validated with our crew dataset from the real world and two public datasets, UBFC-PHYS and SWELL-KW. The experimental results show that the overall performance of our framework was better than that of the state-of-the-art comparison methods.
Enhancing Space-time Video Super-resolution via Spatial-temporal Feature Interaction
Jul 18, 2022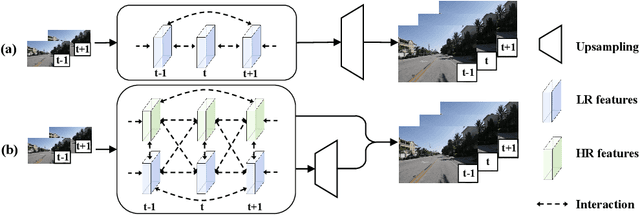
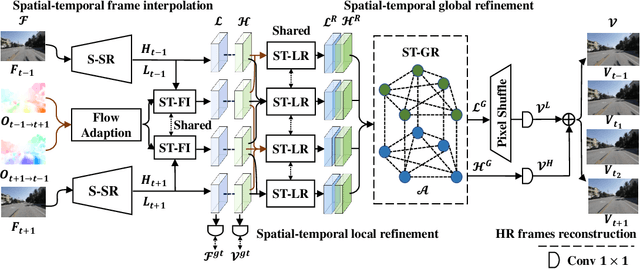
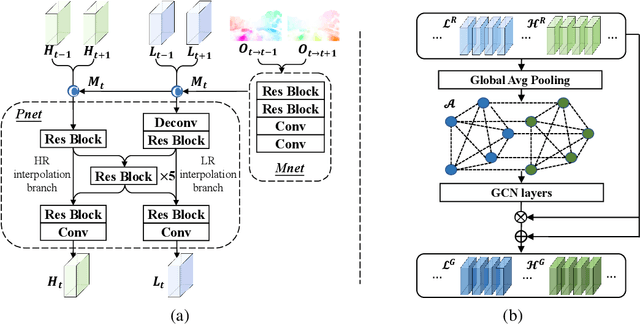
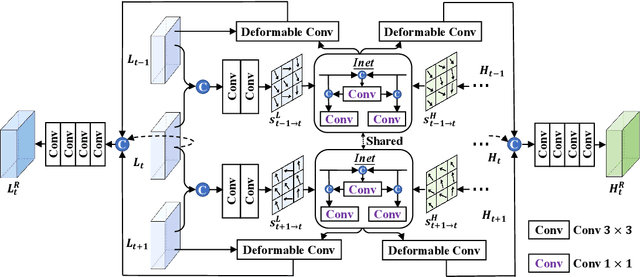
The target of space-time video super-resolution (STVSR) is to increase both the frame rate (also referred to as the temporal resolution) and the spatial resolution of a given video. Recent approaches solve STVSR with end-to-end deep neural networks. A popular solution is to first increase the frame rate of the video; then perform feature refinement among different frame features; and last increase the spatial resolutions of these features. The temporal correlation among features of different frames is carefully exploited in this process. The spatial correlation among features of different (spatial) resolutions, despite being also very important, is however not emphasized. In this paper, we propose a spatial-temporal feature interaction network to enhance STVSR by exploiting both spatial and temporal correlations among features of different frames and spatial resolutions. Specifically, the spatial-temporal frame interpolation module is introduced to interpolate low- and high-resolution intermediate frame features simultaneously and interactively. The spatial-temporal local and global refinement modules are respectively deployed afterwards to exploit the spatial-temporal correlation among different features for their refinement. Finally, a novel motion consistency loss is employed to enhance the motion continuity among reconstructed frames. We conduct experiments on three standard benchmarks, Vid4, Vimeo-90K and Adobe240, and the results demonstrate that our method improves the state of the art methods by a considerable margin. Our codes will be available at https://github.com/yuezijie/STINet-Space-time-Video-Super-resolution.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022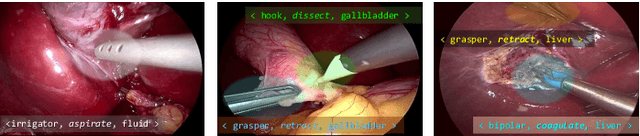

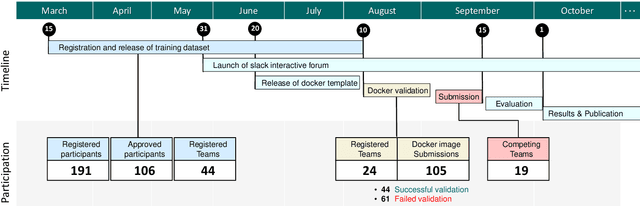
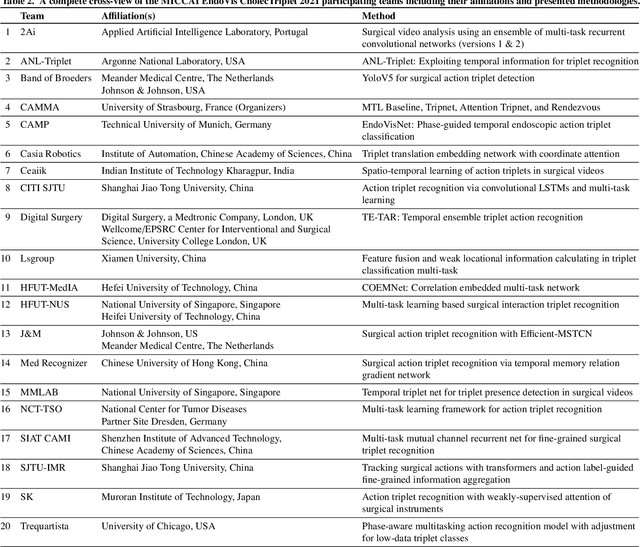
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Single-Shot is Enough: Panoramic Infrastructure Based Calibration of Multiple Cameras and 3D LiDARs
Mar 24, 2021
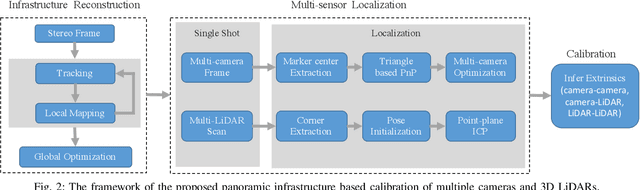

The integration of multiple cameras and 3D Li- DARs has become basic configuration of augmented reality devices, robotics, and autonomous vehicles. The calibration of multi-modal sensors is crucial for a system to properly function, but it remains tedious and impractical for mass production. Moreover, most devices require re-calibration after usage for certain period of time. In this paper, we propose a single-shot solution for calibrating extrinsic transformations among multiple cameras and 3D LiDARs. We establish a panoramic infrastructure, in which a camera or LiDAR can be robustly localized using data from single frame. Experiments are conducted on three devices with different camera-LiDAR configurations, showing that our approach achieved comparable calibration accuracy with the state-of-the-art approaches but with much greater efficiency.