 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Activation and Chaotic Dynamics in Large Language Models: A Quasi-Lyapunov Analysis of Reasoning Mechanisms
Mar 15, 2025The human-like reasoning capabilities exhibited by Large Language Models (LLMs) challenge the traditional neural network theory's understanding of the flexibility of fixed-parameter systems. This paper proposes the "Cognitive Activation" theory, revealing the essence of LLMs' reasoning mechanisms from the perspective of dynamic systems: the model's reasoning ability stems from a chaotic process of dynamic information extraction in the parameter space. By introducing the Quasi-Lyapunov Exponent (QLE), we quantitatively analyze the chaotic characteristics of the model at different layers. Experiments show that the model's information accumulation follows a nonlinear exponential law, and the Multilayer Perceptron (MLP) accounts for a higher proportion in the final output than the attention mechanism. Further experiments indicate that minor initial value perturbations will have a substantial impact on the model's reasoning ability, confirming the theoretical analysis that large language models are chaotic systems. This research provides a chaos theory framework for the interpretability of LLMs' reasoning and reveals potential pathways for balancing creativity and reliability in model design.
Bootstrapping Vision-language Models for Self-supervised Remote Physiological Measurement
Jul 11, 2024



Facial video-based remote physiological measurement is a promising research area for detecting human vital signs (e.g., heart rate, respiration frequency) in a non-contact way. Conventional approaches are mostly supervised learning, requiring extensive collections of facial videos and synchronously recorded photoplethysmography (PPG) signals. To tackle it, self-supervised learning has recently gained attentions; due to the lack of ground truth PPG signals, its performance is however limited. In this paper, we propose a novel self-supervised framework that successfully integrates the popular vision-language models (VLMs) into the remote physiological measurement task. Given a facial video, we first augment its positive and negative video samples with varying rPPG signal frequencies. Next, we introduce a frequency-oriented vision-text pair generation method by carefully creating contrastive spatio-temporal maps from positive and negative samples and designing proper text prompts to describe their relative ratios of signal frequencies. A pre-trained VLM is employed to extract features for these formed vision-text pairs and estimate rPPG signals thereafter. We develop a series of generative and contrastive learning mechanisms to optimize the VLM, including the text-guided visual map reconstruction task, the vision-text contrastive learning task, and the frequency contrastive and ranking task. Overall, our method for the first time adapts VLMs to digest and align the frequency-related knowledge in vision and text modalities. Extensive experiments on four benchmark datasets demonstrate that it significantly outperforms state of the art self-supervised methods.
SFF-DA: Sptialtemporal Feature Fusion for Detecting Anxiety Nonintrusively
Aug 12, 2022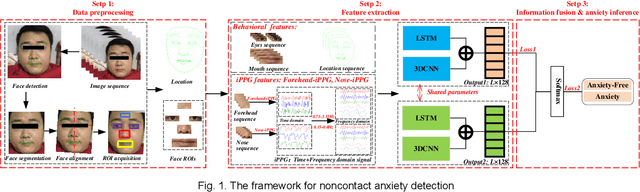
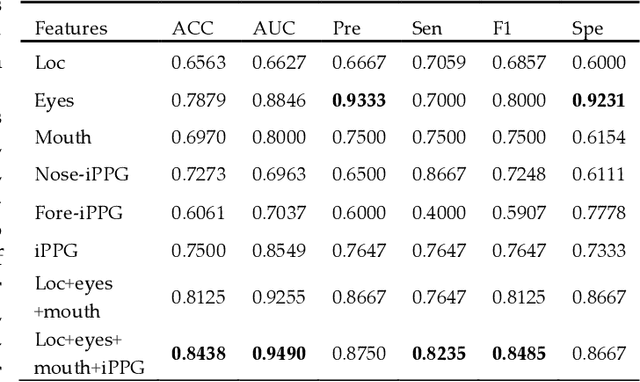
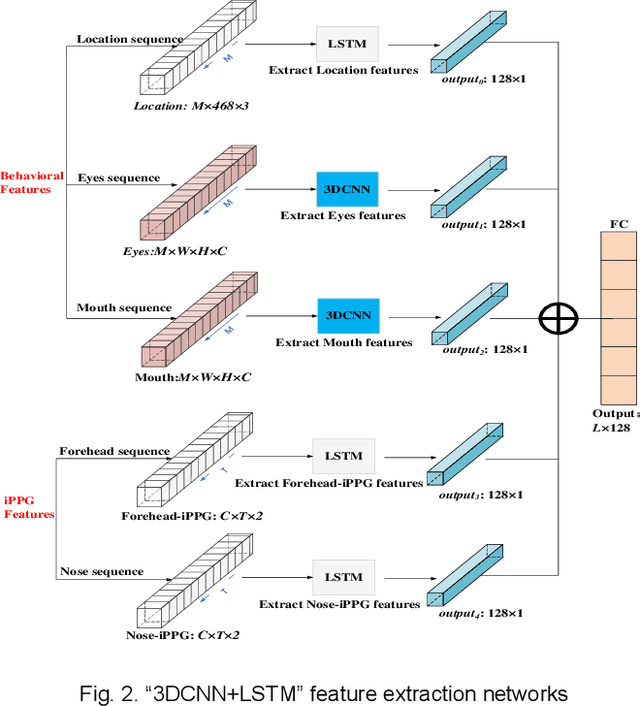
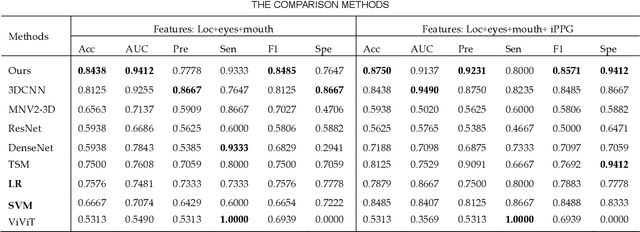
Early detection of anxiety disorders is essential to reduce the suffering of people with mental disorders and to improve treatment outcomes. Anxiety screening based on the mHealth platform is of particular practical value in improving screening efficiency and reducing screening costs. In practice, differences in mobile devices in subjects' physical and mental evaluations and the problems faced with uneven data quality and small sample sizes of data in the real world have made existing methods ineffective. Therefore, we propose a framework based on spatiotemporal feature fusion for detecting anxiety nonintrusively. To reduce the impact of uneven data quality, we constructed a feature extraction network based on "3DCNN+LSTM" and fused spatiotemporal features of facial behavior and noncontact physiology. Moreover, we designed a similarity assessment strategy to solve the problem that the small sample size of data leads to a decline in model accuracy. Our framework was validated with our crew dataset from the real world and two public datasets, UBFC-PHYS and SWELL-KW. The experimental results show that the overall performance of our framework was better than that of the state-of-the-art comparison methods.
Incorporating Prior Knowledge into Reinforcement Learning for Soft Tissue Manipulation with Autonomous Grasping Point Selection
Jul 21, 2022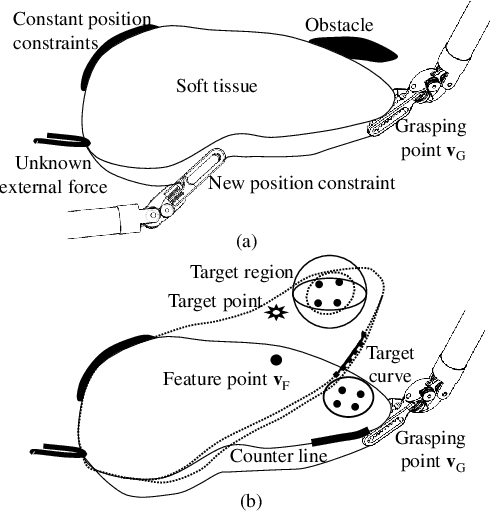
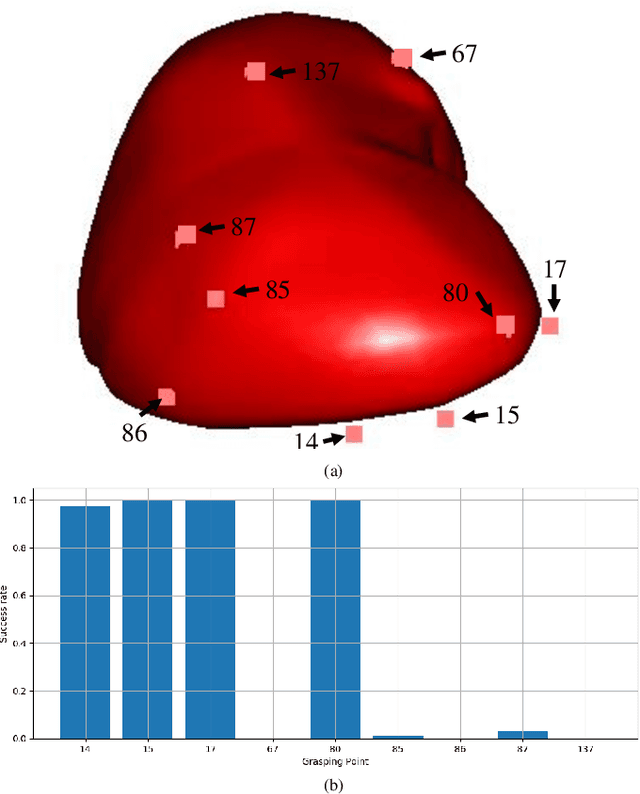
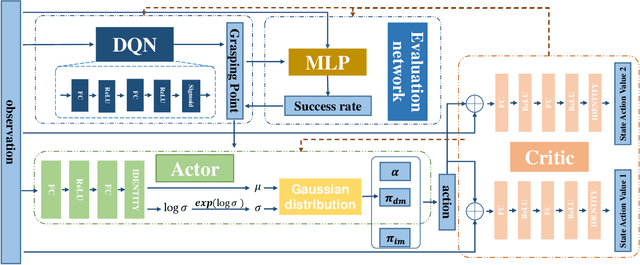

Previous soft tissue manipulation studies assumed that the grasping point was known and the target deformation can be achieved. During the operation, the constraints are supposed to be constant, and there is no obstacles around the soft tissue. To go beyond these assumptions, a deep reinforcement learning framework with prior knowledge is proposed for soft tissue manipulation under unknown constraints, such as the force applied by fascia. The prior knowledge is represented through an intuitive manipulation strategy. As an action of the agent, a regulator factor is used to coordinate the intuitive approach and the deliberate network. A reward function is designed to balance the exploration and exploitation for large deformation. Successful simulation results verify that the proposed framework can manipulate the soft tissue while avoiding obstacles and adding new position constraints. Compared with the soft actor-critic (SAC) algorithm, the proposed framework can accelerate the training procedure and improve the generalization.
Enhancing Space-time Video Super-resolution via Spatial-temporal Feature Interaction
Jul 18, 2022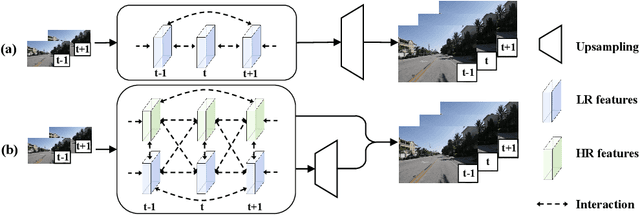
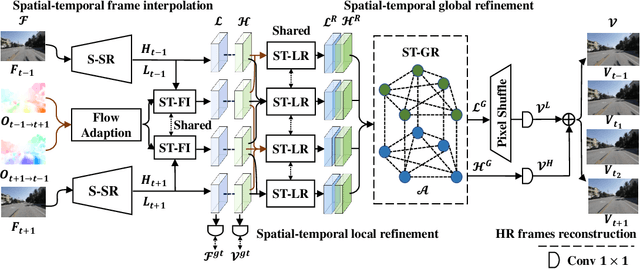
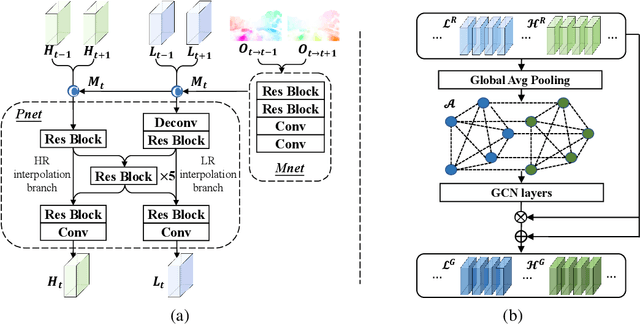
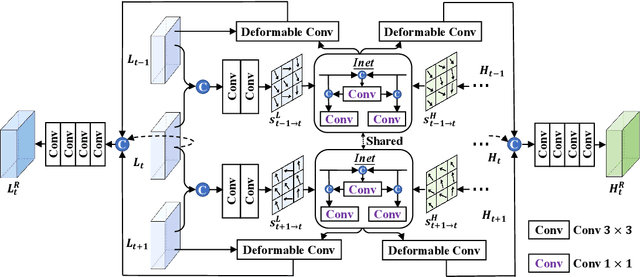
The target of space-time video super-resolution (STVSR) is to increase both the frame rate (also referred to as the temporal resolution) and the spatial resolution of a given video. Recent approaches solve STVSR with end-to-end deep neural networks. A popular solution is to first increase the frame rate of the video; then perform feature refinement among different frame features; and last increase the spatial resolutions of these features. The temporal correlation among features of different frames is carefully exploited in this process. The spatial correlation among features of different (spatial) resolutions, despite being also very important, is however not emphasized. In this paper, we propose a spatial-temporal feature interaction network to enhance STVSR by exploiting both spatial and temporal correlations among features of different frames and spatial resolutions. Specifically, the spatial-temporal frame interpolation module is introduced to interpolate low- and high-resolution intermediate frame features simultaneously and interactively. The spatial-temporal local and global refinement modules are respectively deployed afterwards to exploit the spatial-temporal correlation among different features for their refinement. Finally, a novel motion consistency loss is employed to enhance the motion continuity among reconstructed frames. We conduct experiments on three standard benchmarks, Vid4, Vimeo-90K and Adobe240, and the results demonstrate that our method improves the state of the art methods by a considerable margin. Our codes will be available at https://github.com/yuezijie/STINet-Space-time-Video-Super-resolution.
The Role of Edge Robotics As-a-Service in Monitoring COVID-19 Infection
Dec 09, 2020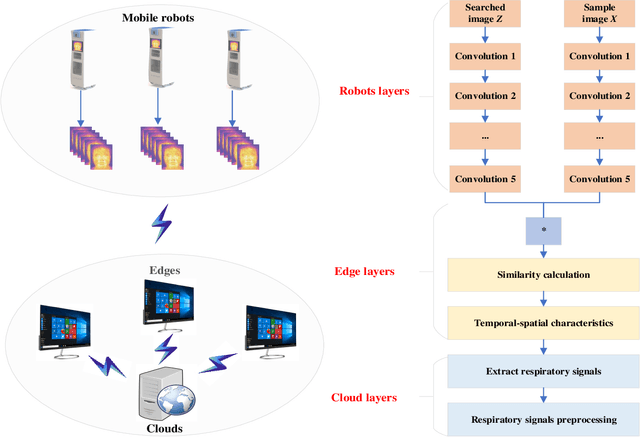
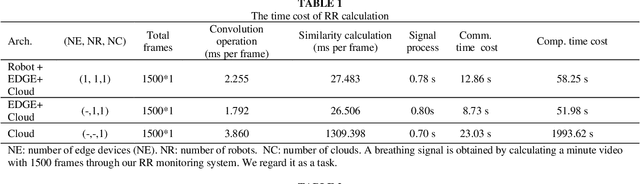
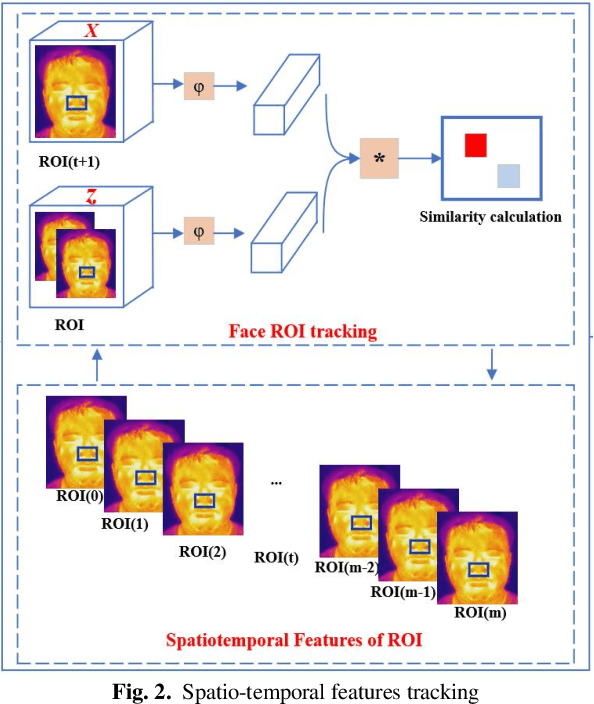
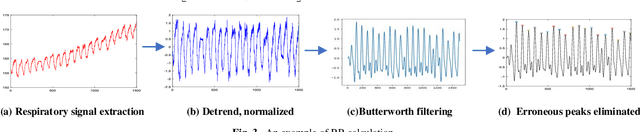
Deep learning technology has been widely used in edge computing. However, pandemics like covid-19 require deep learning capabilities at mobile devices (detect respiratory rate using mobile robotics or conduct CT scan using a mobile scanner), which are severely constrained by the limited storage and computation resources at the device level. To solve this problem, we propose a three-tier architecture, including robot layers, edge layers, and cloud layers. We adopt this architecture to design a non-contact respiratory monitoring system to break down respiratory rate calculation tasks. Experimental results of respiratory rate monitoring show that the proposed approach in this paper significantly outperforms other approaches. It is supported by computation time costs with 2.26 ms per frame, 27.48 ms per frame, 0.78 seconds for convolution operation, similarity calculation, processing one-minute length respiratory signals, respectively. And the computation time costs of our three-tier architecture are less than that of edge+cloud architecture and cloud architecture. Moreover, we use our three-tire architecture for CT image diagnosis task decomposition. The evaluation of a CT image dataset of COVID-19 proves that our three-tire architecture is useful for resolving tasks on deep learning networks by edge equipment. There are broad application scenarios in smart hospitals in the future.