 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Mamba Compatible with Trajectory Optimization in Offline Reinforcement Learning?
May 20, 2024



Transformer-based trajectory optimization methods have demonstrated exceptional performance in offline Reinforcement Learning (offline RL), yet it poses challenges due to substantial parameter size and limited scalability, which is particularly critical in sequential decision-making scenarios where resources are constrained such as in robots and drones with limited computational power. Mamba, a promising new linear-time sequence model, offers performance on par with transformers while delivering substantially fewer parameters on long sequences. As it remains unclear whether Mamba is compatible with trajectory optimization, this work aims to conduct comprehensive experiments to explore the potential of Decision Mamba in offline RL (dubbed DeMa) from the aspect of data structures and network architectures with the following insights: (1) Long sequences impose a significant computational burden without contributing to performance improvements due to the fact that DeMa's focus on sequences diminishes approximately exponentially. Consequently, we introduce a Transformer-like DeMa as opposed to an RNN-like DeMa. (2) For the components of DeMa, we identify that the hidden attention mechanism is key to its success, which can also work well with other residual structures and does not require position embedding. Extensive evaluations from eight Atari games demonstrate that our specially designed DeMa is compatible with trajectory optimization and surpasses previous state-of-the-art methods, outdoing Decision Transformer (DT) by 80\% with 30\% fewer parameters, and exceeds DT in MuJoCo with only a quarter of the parameters.
Could It Be Generated? Towards Practical Analysis of Memorization in Text-To-Image Diffusion Models
May 09, 2024



The past few years have witnessed substantial advancement in text-guided image generation powered by diffusion models. However, it was shown that text-to-image diffusion models are vulnerable to training image memorization, raising concerns on copyright infringement and privacy invasion. In this work, we perform practical analysis of memorization in text-to-image diffusion models. Targeting a set of images to protect, we conduct quantitive analysis on them without need to collect any prompts. Specifically, we first formally define the memorization of image and identify three necessary conditions of memorization, respectively similarity, existence and probability. We then reveal the correlation between the model's prediction error and image replication. Based on the correlation, we propose to utilize inversion techniques to verify the safety of target images against memorization and measure the extent to which they are memorized. Model developers can utilize our analysis method to discover memorized images or reliably claim safety against memorization. Extensive experiments on the Stable Diffusion, a popular open-source text-to-image diffusion model, demonstrate the effectiveness of our analysis method.
PRSA: Prompt Reverse Stealing Attacks against Large Language Models
Feb 29, 2024Prompt, recognized as crucial intellectual property, enables large language models (LLMs) to perform specific tasks without the need of fine-tuning, underscoring their escalating importance. With the rise of prompt-based services, such as prompt marketplaces and LLM applications, providers often display prompts' capabilities through input-output examples to attract users. However, this paradigm raises a pivotal security concern: does the exposure of input-output pairs pose the risk of potential prompt leakage, infringing on the intellectual property rights of the developers? To our knowledge, this problem still has not been comprehensively explored yet. To remedy this gap, in this paper, we perform the first in depth exploration and propose a novel attack framework for reverse-stealing prompts against commercial LLMs, namely PRSA. The main idea of PRSA is that by analyzing the critical features of the input-output pairs, we mimic and gradually infer (steal) the target prompts. In detail, PRSA mainly consists of two key phases: prompt mutation and prompt pruning. In the mutation phase, we propose a prompt attention algorithm based on differential feedback to capture these critical features for effectively inferring the target prompts. In the prompt pruning phase, we identify and mask the words dependent on specific inputs, enabling the prompts to accommodate diverse inputs for generalization. Through extensive evaluation, we verify that PRSA poses a severe threat in real world scenarios. We have reported these findings to prompt service providers and actively collaborate with them to take protective measures for prompt copyright.
SUB-PLAY: Adversarial Policies against Partially Observed Multi-Agent Reinforcement Learning Systems
Feb 06, 2024Recent advances in multi-agent reinforcement learning (MARL) have opened up vast application prospects, including swarm control of drones, collaborative manipulation by robotic arms, and multi-target encirclement. However, potential security threats during the MARL deployment need more attention and thorough investigation. Recent researches reveal that an attacker can rapidly exploit the victim's vulnerabilities and generate adversarial policies, leading to the victim's failure in specific tasks. For example, reducing the winning rate of a superhuman-level Go AI to around 20%. They predominantly focus on two-player competitive environments, assuming attackers possess complete global state observation. In this study, we unveil, for the first time, the capability of attackers to generate adversarial policies even when restricted to partial observations of the victims in multi-agent competitive environments. Specifically, we propose a novel black-box attack (SUB-PLAY), which incorporates the concept of constructing multiple subgames to mitigate the impact of partial observability and suggests the sharing of transitions among subpolicies to improve the exploitative ability of attackers. Extensive evaluations demonstrate the effectiveness of SUB-PLAY under three typical partial observability limitations. Visualization results indicate that adversarial policies induce significantly different activations of the victims' policy networks. Furthermore, we evaluate three potential defenses aimed at exploring ways to mitigate security threats posed by adversarial policies, providing constructive recommendations for deploying MARL in competitive environments.
The Risk of Federated Learning to Skew Fine-Tuning Features and Underperform Out-of-Distribution Robustness
Jan 25, 2024To tackle the scarcity and privacy issues associated with domain-specific datasets, the integration of federated learning in conjunction with fine-tuning has emerged as a practical solution. However, our findings reveal that federated learning has the risk of skewing fine-tuning features and compromising the out-of-distribution robustness of the model. By introducing three robustness indicators and conducting experiments across diverse robust datasets, we elucidate these phenomena by scrutinizing the diversity, transferability, and deviation within the model feature space. To mitigate the negative impact of federated learning on model robustness, we introduce GNP, a \underline{G}eneral \underline{N}oisy \underline{P}rojection-based robust algorithm, ensuring no deterioration of accuracy on the target distribution. Specifically, the key strategy for enhancing model robustness entails the transfer of robustness from the pre-trained model to the fine-tuned model, coupled with adding a small amount of Gaussian noise to augment the representative capacity of the model. Comprehensive experimental results demonstrate that our approach markedly enhances the robustness across diverse scenarios, encompassing various parameter-efficient fine-tuning methods and confronting different levels of data heterogeneity.
MEAOD: Model Extraction Attack against Object Detectors
Dec 22, 2023The widespread use of deep learning technology across various industries has made deep neural network models highly valuable and, as a result, attractive targets for potential attackers. Model extraction attacks, particularly query-based model extraction attacks, allow attackers to replicate a substitute model with comparable functionality to the victim model and present a significant threat to the confidentiality and security of MLaaS platforms. While many studies have explored threats of model extraction attacks against classification models in recent years, object detection models, which are more frequently used in real-world scenarios, have received less attention. In this paper, we investigate the challenges and feasibility of query-based model extraction attacks against object detection models and propose an effective attack method called MEAOD. It selects samples from the attacker-possessed dataset to construct an efficient query dataset using active learning and enhances the categories with insufficient objects. We additionally improve the extraction effectiveness by updating the annotations of the query dataset. According to our gray-box and black-box scenarios experiments, we achieve an extraction performance of over 70% under the given condition of a 10k query budget.
Let All be Whitened: Multi-teacher Distillation for Efficient Visual Retrieval
Dec 15, 2023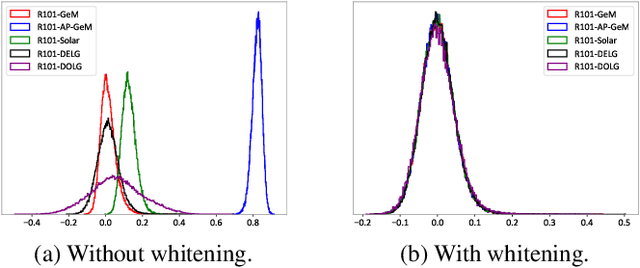
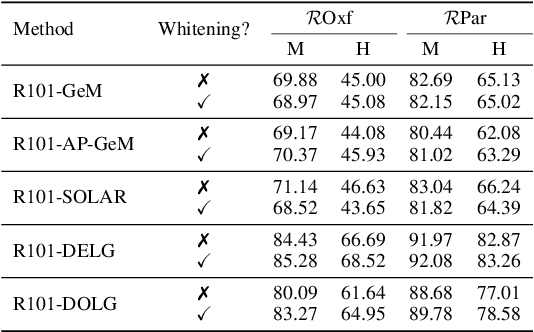
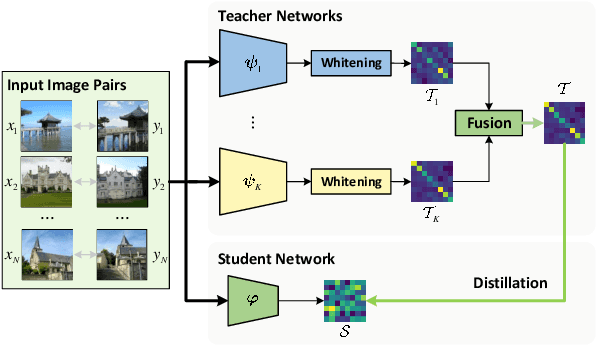
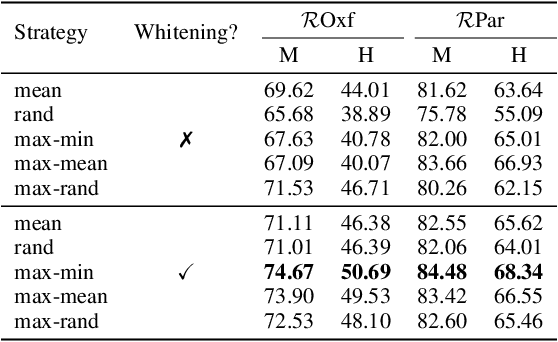
Visual retrieval aims to search for the most relevant visual items, e.g., images and videos, from a candidate gallery with a given query item. Accuracy and efficiency are two competing objectives in retrieval tasks. Instead of crafting a new method pursuing further improvement on accuracy, in this paper we propose a multi-teacher distillation framework Whiten-MTD, which is able to transfer knowledge from off-the-shelf pre-trained retrieval models to a lightweight student model for efficient visual retrieval. Furthermore, we discover that the similarities obtained by different retrieval models are diversified and incommensurable, which makes it challenging to jointly distill knowledge from multiple models. Therefore, we propose to whiten the output of teacher models before fusion, which enables effective multi-teacher distillation for retrieval models. Whiten-MTD is conceptually simple and practically effective. Extensive experiments on two landmark image retrieval datasets and one video retrieval dataset demonstrate the effectiveness of our proposed method, and its good balance of retrieval performance and efficiency. Our source code is released at https://github.com/Maryeon/whiten_mtd.
On the Difficulty of Defending Contrastive Learning against Backdoor Attacks
Dec 14, 2023



Recent studies have shown that contrastive learning, like supervised learning, is highly vulnerable to backdoor attacks wherein malicious functions are injected into target models, only to be activated by specific triggers. However, thus far it remains under-explored how contrastive backdoor attacks fundamentally differ from their supervised counterparts, which impedes the development of effective defenses against the emerging threat. This work represents a solid step toward answering this critical question. Specifically, we define TRL, a unified framework that encompasses both supervised and contrastive backdoor attacks. Through the lens of TRL, we uncover that the two types of attacks operate through distinctive mechanisms: in supervised attacks, the learning of benign and backdoor tasks tends to occur independently, while in contrastive attacks, the two tasks are deeply intertwined both in their representations and throughout their learning processes. This distinction leads to the disparate learning dynamics and feature distributions of supervised and contrastive attacks. More importantly, we reveal that the specificities of contrastive backdoor attacks entail important implications from a defense perspective: existing defenses for supervised attacks are often inadequate and not easily retrofitted to contrastive attacks. We also explore several alternative defenses and discuss their potential challenges. Our findings highlight the need for defenses tailored to the specificities of contrastive backdoor attacks, pointing to promising directions for future research.
Improving the Robustness of Transformer-based Large Language Models with Dynamic Attention
Nov 30, 2023



Transformer-based models, such as BERT and GPT, have been widely adopted in natural language processing (NLP) due to their exceptional performance. However, recent studies show their vulnerability to textual adversarial attacks where the model's output can be misled by intentionally manipulating the text inputs. Despite various methods that have been proposed to enhance the model's robustness and mitigate this vulnerability, many require heavy consumption resources (e.g., adversarial training) or only provide limited protection (e.g., defensive dropout). In this paper, we propose a novel method called dynamic attention, tailored for the transformer architecture, to enhance the inherent robustness of the model itself against various adversarial attacks. Our method requires no downstream task knowledge and does not incur additional costs. The proposed dynamic attention consists of two modules: (I) attention rectification, which masks or weakens the attention value of the chosen tokens, and (ii) dynamic modeling, which dynamically builds the set of candidate tokens. Extensive experiments demonstrate that dynamic attention significantly mitigates the impact of adversarial attacks, improving up to 33\% better performance than previous methods against widely-used adversarial attacks. The model-level design of dynamic attention enables it to be easily combined with other defense methods (e.g., adversarial training) to further enhance the model's robustness. Furthermore, we demonstrate that dynamic attention preserves the state-of-the-art robustness space of the original model compared to other dynamic modeling methods.
AdaCCD: Adaptive Semantic Contrasts Discovery based Cross Lingual Adaptation for Code Clone Detection
Nov 13, 2023



Code Clone Detection, which aims to retrieve functionally similar programs from large code bases, has been attracting increasing attention. Modern software often involves a diverse range of programming languages. However, current code clone detection methods are generally limited to only a few popular programming languages due to insufficient annotated data as well as their own model design constraints. To address these issues, we present AdaCCD, a novel cross-lingual adaptation method that can detect cloned codes in a new language without any annotations in that language. AdaCCD leverages language-agnostic code representations from pre-trained programming language models and propose an Adaptively Refined Contrastive Learning framework to transfer knowledge from resource-rich languages to resource-poor languages. We evaluate the cross-lingual adaptation results of AdaCCD by constructing a multilingual code clone detection benchmark consisting of 5 programming languages. AdaCCD achieves significant improvements over other baselines, and it is even comparable to supervised fine-tuning.