 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Transformers for Neural Machine Translation
Jun 18, 2021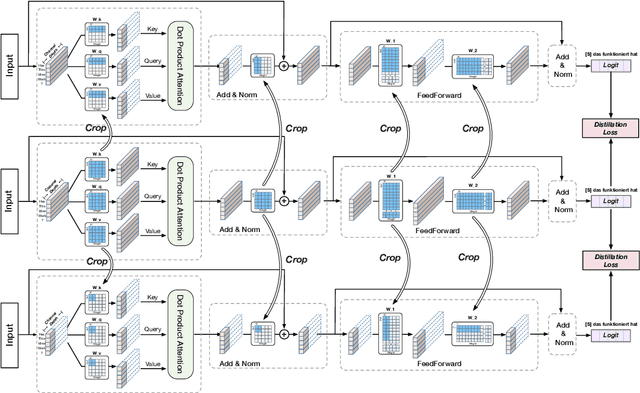
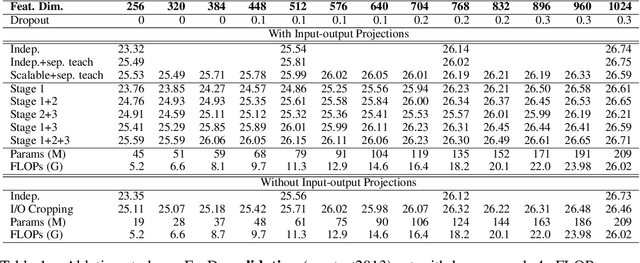
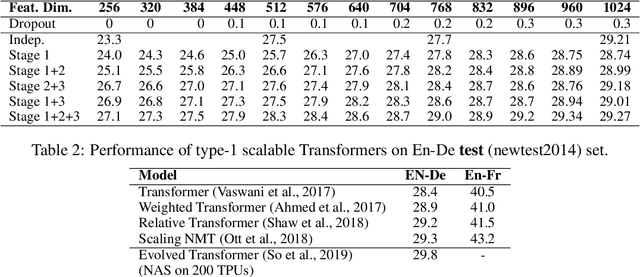
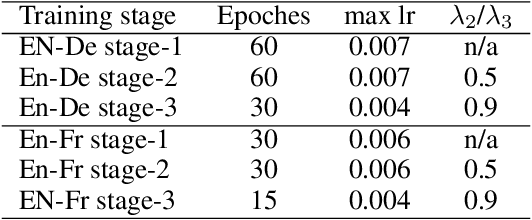
Transformer has been widely adopted in Neural Machine Translation (NMT) because of its large capacity and parallel training of sequence generation. However, the deployment of Transformer is challenging because different scenarios require models of different complexities and scales. Naively training multiple Transformers is redundant in terms of both computation and memory. In this paper, we propose a novel Scalable Transformers, which naturally contains sub-Transformers of different scales and have shared parameters. Each sub-Transformer can be easily obtained by cropping the parameters of the largest Transformer. A three-stage training scheme is proposed to tackle the difficulty of training the Scalable Transformers, which introduces additional supervisions from word-level and sequence-level self-distillation. Extensive experiments were conducted on WMT EN-De and En-Fr to validate our proposed Scalable Transformers.
RomeBERT: Robust Training of Multi-Exit BERT
Jan 24, 2021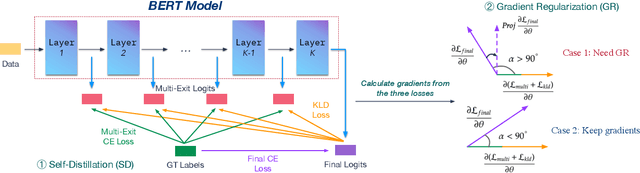
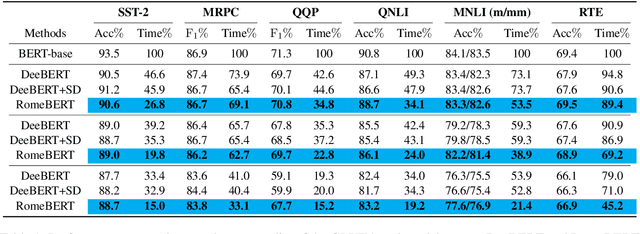
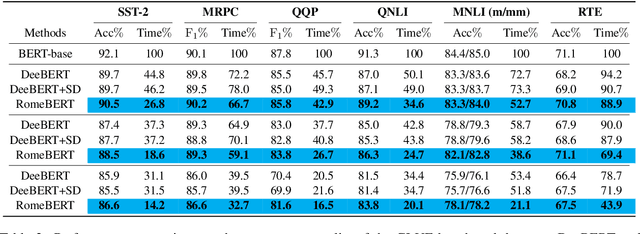
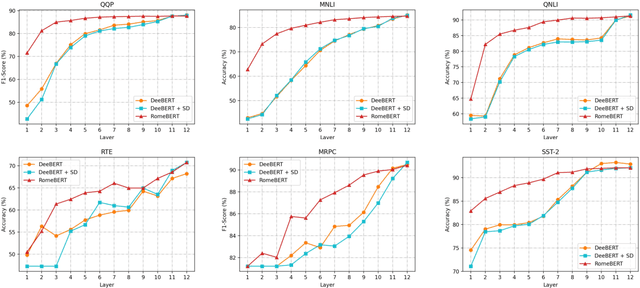
BERT has achieved superior performances on Natural Language Understanding (NLU) tasks. However, BERT possesses a large number of parameters and demands certain resources to deploy. For acceleration, Dynamic Early Exiting for BERT (DeeBERT) has been proposed recently, which incorporates multiple exits and adopts a dynamic early-exit mechanism to ensure efficient inference. While obtaining an efficiency-performance tradeoff, the performances of early exits in multi-exit BERT are significantly worse than late exits. In this paper, we leverage gradient regularized self-distillation for RObust training of Multi-Exit BERT (RomeBERT), which can effectively solve the performance imbalance problem between early and late exits. Moreover, the proposed RomeBERT adopts a one-stage joint training strategy for multi-exits and the BERT backbone while DeeBERT needs two stages that require more training time. Extensive experiments on GLUE datasets are performed to demonstrate the superiority of our approach. Our code is available at https://github.com/romebert/RomeBERT.
Multi-Pass Transformer for Machine Translation
Sep 23, 2020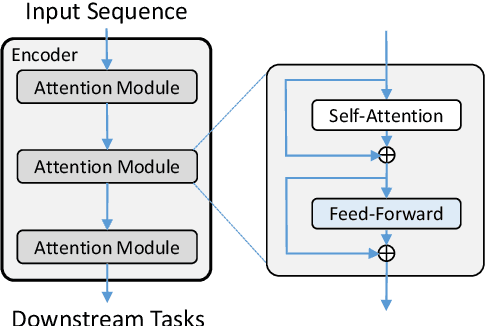
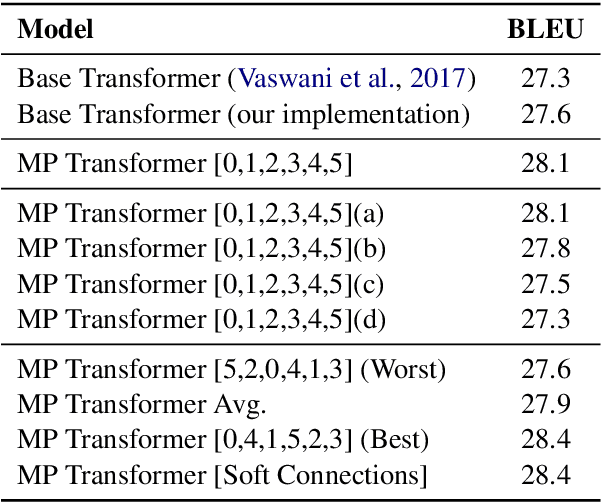
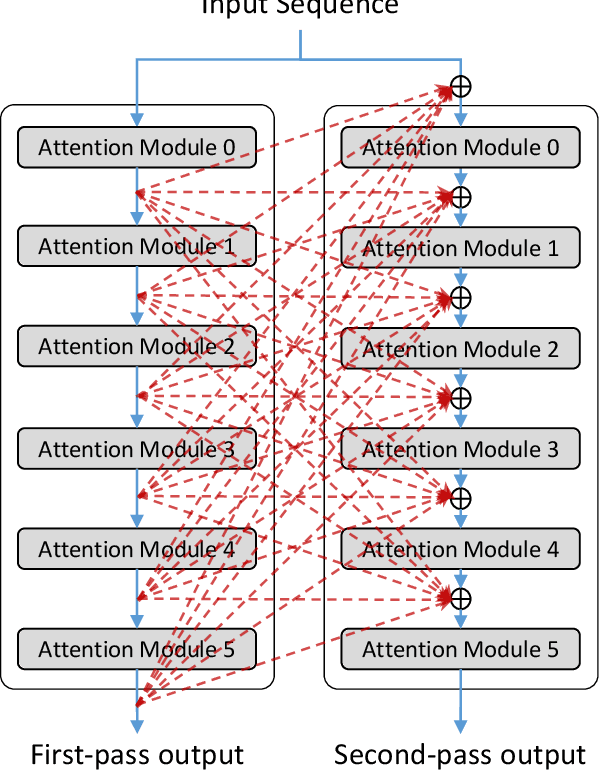
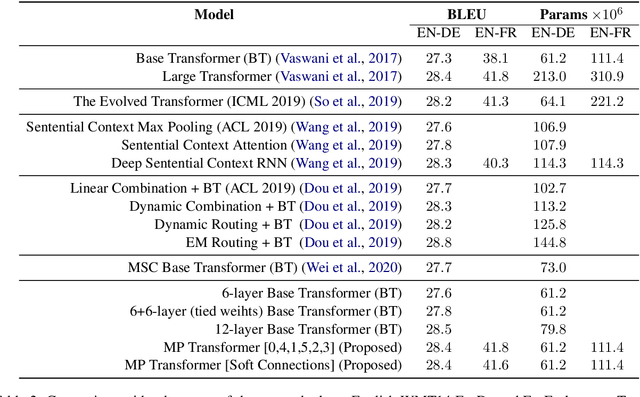
In contrast with previous approaches where information flows only towards deeper layers of a stack, we consider a multi-pass transformer (MPT) architecture in which earlier layers are allowed to process information in light of the output of later layers. To maintain a directed acyclic graph structure, the encoder stack of a transformer is repeated along a new multi-pass dimension, keeping the parameters tied, and information is allowed to proceed unidirectionally both towards deeper layers within an encoder stack and towards any layer of subsequent stacks. We consider both soft (i.e., continuous) and hard (i.e., discrete) connections between parallel encoder stacks, relying on a neural architecture search to find the best connection pattern in the hard case. We perform an extensive ablation study of the proposed MPT architecture and compare it with other state-of-the-art transformer architectures. Surprisingly, Base Transformer equipped with MPT can surpass the performance of Large Transformer on the challenging machine translation En-De and En-Fr datasets. In the hard connection case, the optimal connection pattern found for En-De also leads to improved performance for En-Fr.
Contrastive Visual-Linguistic Pretraining
Jul 26, 2020
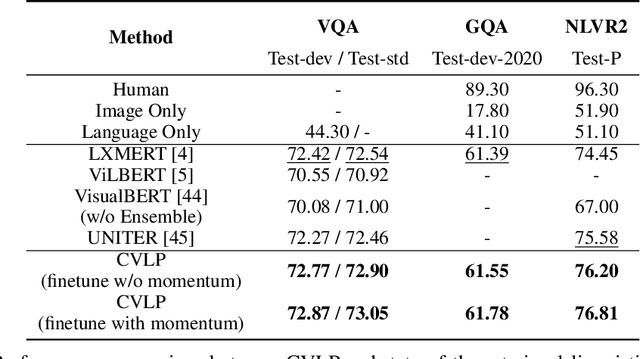
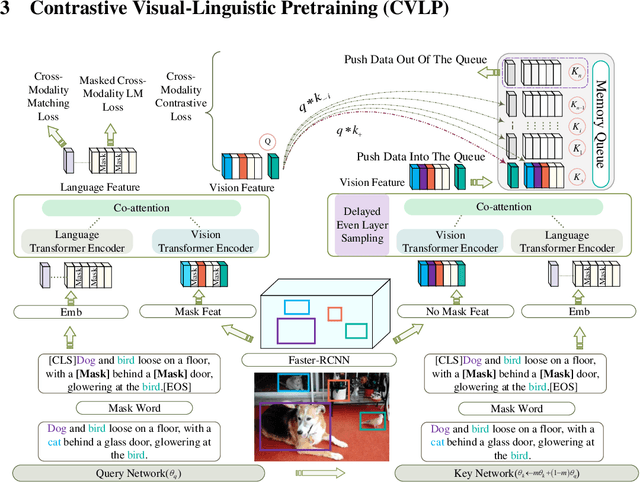
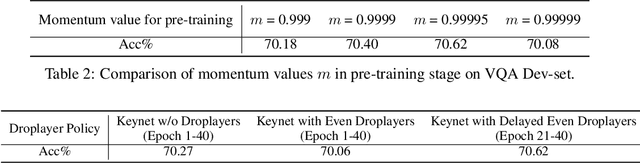
Several multi-modality representation learning approaches such as LXMERT and ViLBERT have been proposed recently. Such approaches can achieve superior performance due to the high-level semantic information captured during large-scale multimodal pretraining. However, as ViLBERT and LXMERT adopt visual region regression and classification loss, they often suffer from domain gap and noisy label problems, based on the visual features having been pretrained on the Visual Genome dataset. To overcome these issues, we propose unbiased Contrastive Visual-Linguistic Pretraining (CVLP), which constructs a visual self-supervised loss built upon contrastive learning. We evaluate CVLP on several down-stream tasks, including VQA, GQA and NLVR2 to validate the superiority of contrastive learning on multi-modality representation learning. Our code is available at: https://github.com/ArcherYunDong/CVLP-.
Spatio-Temporal Scene Graphs for Video Dialog
Jul 08, 2020
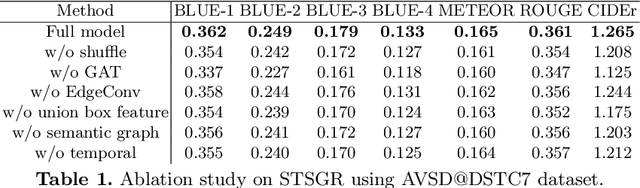
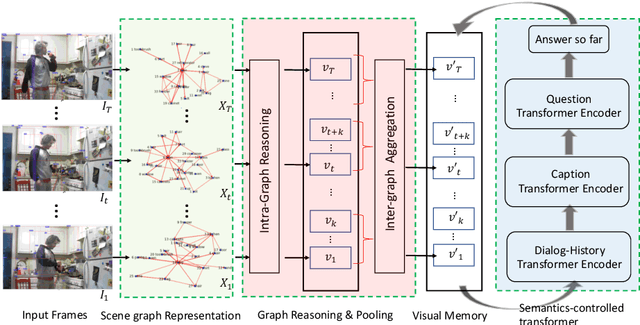
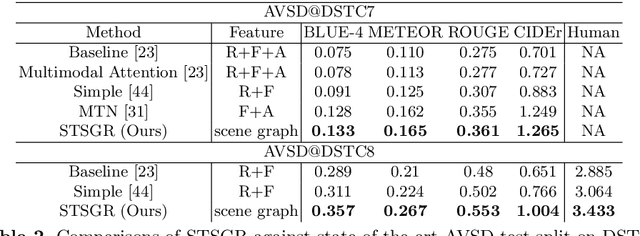
The Audio-Visual Scene-aware Dialog (AVSD) task requires an agent to indulge in a natural conversation with a human about a given video. Specifically, apart from the video frames, the agent receives the audio, brief captions, and a dialog history, and the task is to produce the correct answer to a question about the video. Due to the diversity in the type of inputs, this task poses a very challenging multimodal reasoning problem. Current approaches to AVSD either use global video-level features or those from a few sampled frames, and thus lack the ability to explicitly capture relevant visual regions or their interactions for answer generation. To this end, we propose a novel spatio-temporal scene graph representation (STSGR) modeling fine-grained information flows within videos. Specifically, on an input video sequence, STSGR (i) creates a two-stream visual and semantic scene graph on every frame, (ii) conducts intra-graph reasoning using node and edge convolutions generating visual memories, and (iii) applies inter-graph aggregation to capture their temporal evolutions. These visual memories are then combined with other modalities and the question embeddings using a novel semantics-controlled multi-head shuffled transformer, which then produces the answer recursively. Our entire pipeline is trained end-to-end. We present experiments on the AVSD dataset and demonstrate state-of-the-art results. A human evaluation on the quality of our generated answers shows 12% relative improvement against prior methods.
Fairness-Aware Explainable Recommendation over Knowledge Graphs
Jun 28, 2020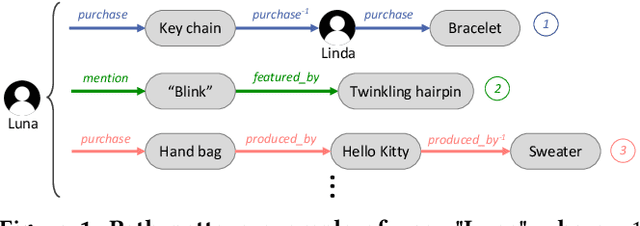
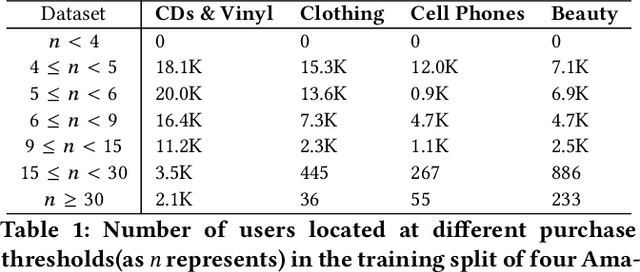
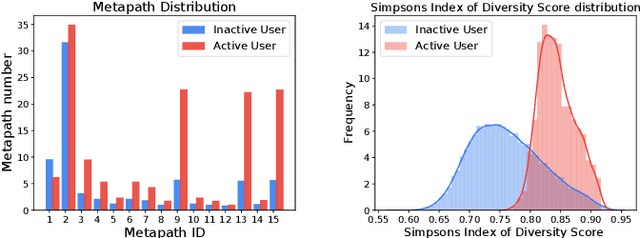

There has been growing attention on fairness considerations recently, especially in the context of intelligent decision making systems. Explainable recommendation systems, in particular, may suffer from both explanation bias and performance disparity. In this paper, we analyze different groups of users according to their level of activity, and find that bias exists in recommendation performance between different groups. We show that inactive users may be more susceptible to receiving unsatisfactory recommendations, due to insufficient training data for the inactive users, and that their recommendations may be biased by the training records of more active users, due to the nature of collaborative filtering, which leads to an unfair treatment by the system. We propose a fairness constrained approach via heuristic re-ranking to mitigate this unfairness problem in the context of explainable recommendation over knowledge graphs. We experiment on several real-world datasets with state-of-the-art knowledge graph-based explainable recommendation algorithms. The promising results show that our algorithm is not only able to provide high-quality explainable recommendations, but also reduces the recommendation unfairness in several respects.
Character Matters: Video Story Understanding with Character-Aware Relations
May 09, 2020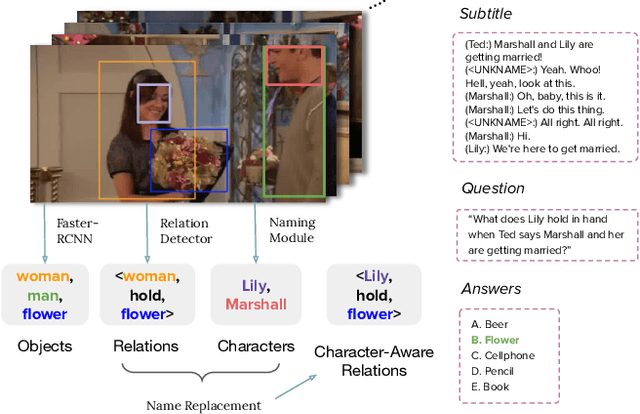
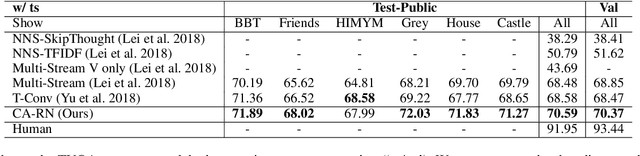
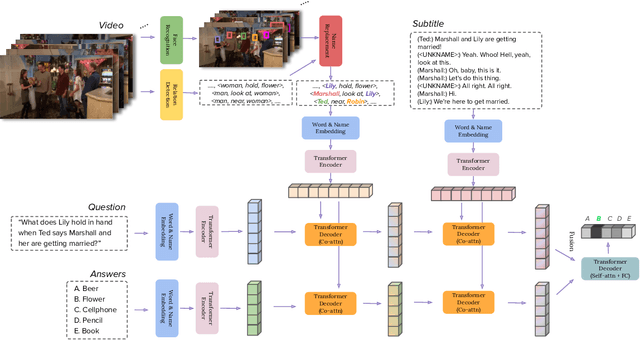
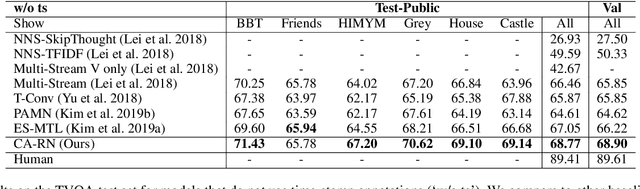
Different from short videos and GIFs, video stories contain clear plots and lists of principal characters. Without identifying the connection between appearing people and character names, a model is not able to obtain a genuine understanding of the plots. Video Story Question Answering (VSQA) offers an effective way to benchmark higher-level comprehension abilities of a model. However, current VSQA methods merely extract generic visual features from a scene. With such an approach, they remain prone to learning just superficial correlations. In order to attain a genuine understanding of who did what to whom, we propose a novel model that continuously refines character-aware relations. This model specifically considers the characters in a video story, as well as the relations connecting different characters and objects. Based on these signals, our framework enables weakly-supervised face naming through multi-instance co-occurrence matching and supports high-level reasoning utilizing Transformer structures. We train and test our model on the six diverse TV shows in the TVQA dataset, which is by far the largest and only publicly available dataset for VSQA. We validate our proposed approach over TVQA dataset through extensive ablation study.
Multi-Layer Content Interaction Through Quaternion Product For Visual Question Answering
Feb 16, 2020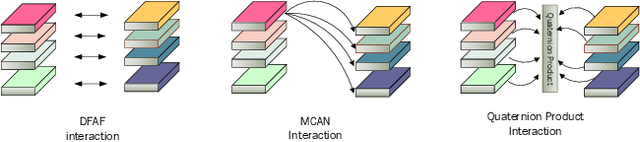
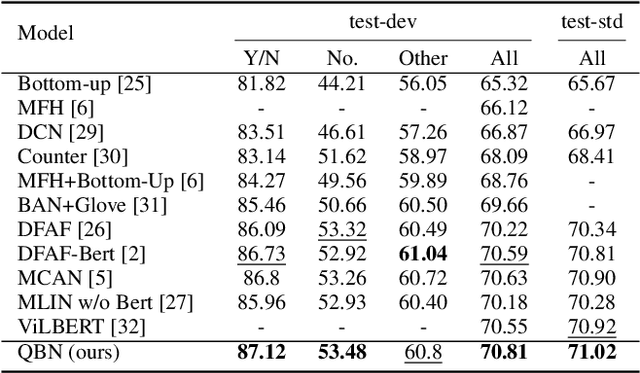
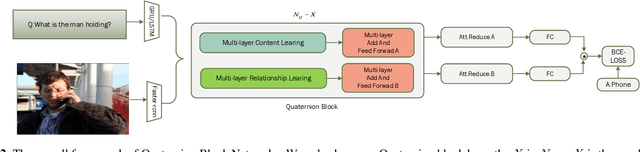
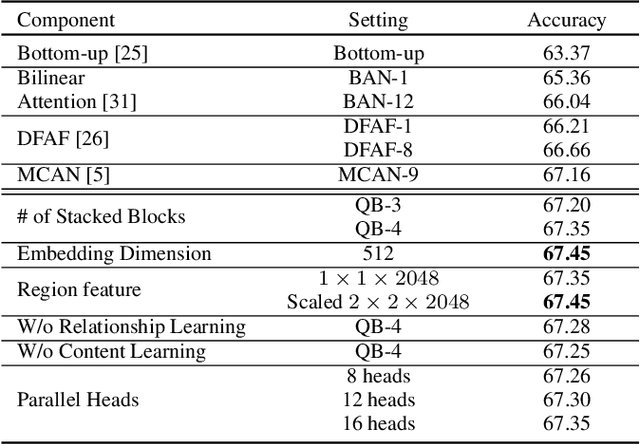
Multi-modality fusion technologies have greatly improved the performance of neural network-based Video Description/Caption, Visual Question Answering (VQA) and Audio Visual Scene-aware Dialog (AVSD) over the recent years. Most previous approaches only explore the last layers of multiple layer feature fusion while omitting the importance of intermediate layers. To solve the issue for the intermediate layers, we propose an efficient Quaternion Block Network (QBN) to learn interaction not only for the last layer but also for all intermediate layers simultaneously. In our proposed QBN, we use the holistic text features to guide the update of visual features. In the meantime, Hamilton quaternion products can efficiently perform information flow from higher layers to lower layers for both visual and text modalities. The evaluation results show our QBN improved the performance on VQA 2.0, even though using surpass large scale BERT or visual BERT pre-trained models. Extensive ablation study has been carried out to testify the influence of each proposed module in this study.
ABSent: Cross-Lingual Sentence Representation Mapping with Bidirectional GANs
Jan 29, 2020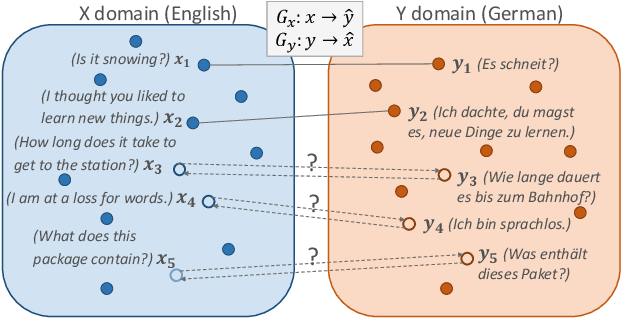
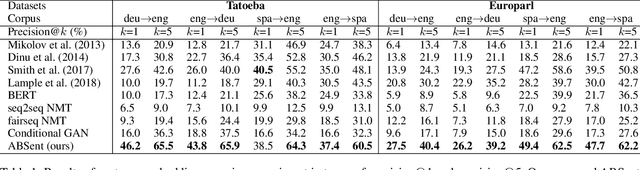
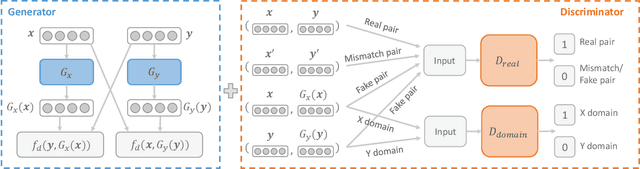
A number of cross-lingual transfer learning approaches based on neural networks have been proposed for the case when large amounts of parallel text are at our disposal. However, in many real-world settings, the size of parallel annotated training data is restricted. Additionally, prior cross-lingual mapping research has mainly focused on the word level. This raises the question of whether such techniques can also be applied to effortlessly obtain cross-lingually aligned sentence representations. To this end, we propose an Adversarial Bi-directional Sentence Embedding Mapping (ABSent) framework, which learns mappings of cross-lingual sentence representations from limited quantities of parallel data.
2nd Place Solution to the GQA Challenge 2019
Aug 16, 2019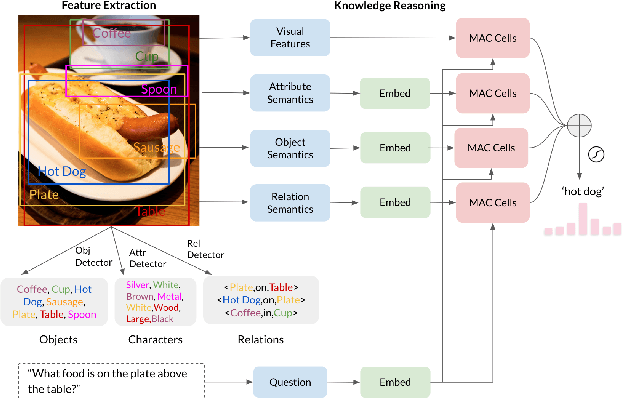
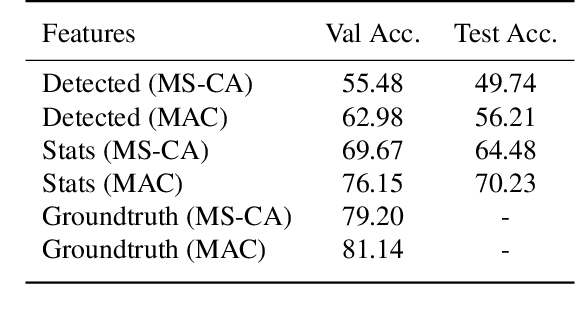
We present a simple method that achieves unexpectedly superior performance for Complex Reasoning involved Visual Question Answering. Our solution collects statistical features from high-frequency words of all the questions asked about an image and use them as accurate knowledge for answering further questions of the same image. We are fully aware that this setting is not ubiquitously applicable, and in a more common setting one should assume the questions are asked separately and they cannot be gathered to obtain a knowledge base. Nonetheless, we use this method as an evidence to demonstrate our observation that the bottleneck effect is more severe on the feature extraction part than it is on the knowledge reasoning part. We show significant gaps when using the same reasoning model with 1) ground-truth features; 2) statistical features; 3) detected features from completely learned detectors, and analyze what these gaps mean to researches on visual reasoning topics. Our model with the statistical features achieves the 2nd place in the GQA Challenge 2019.