 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow2Deep: Indoor Scene Modeling by Single Image Understanding
Feb 22, 2020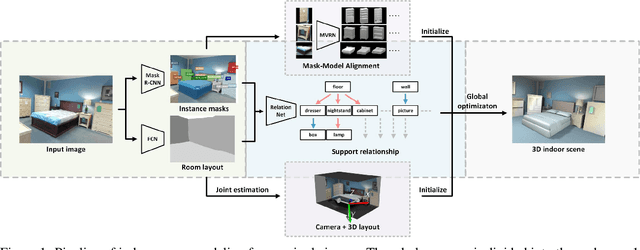



Dense indoor scene modeling from 2D images has been bottlenecked due to the absence of depth information and cluttered occlusions. We present an automatic indoor scene modeling approach using deep features from neural networks. Given a single RGB image, our method simultaneously recovers semantic contents, 3D geometry and object relationship by reasoning indoor environment context. Particularly, we design a shallow-to-deep architecture on the basis of convolutional networks for semantic scene understanding and modeling. It involves multi-level convolutional networks to parse indoor semantics/geometry into non-relational and relational knowledge. Non-relational knowledge extracted from shallow-end networks (e.g. room layout, object geometry) is fed forward into deeper levels to parse relational semantics (e.g. support relationship). A Relation Network is proposed to infer the support relationship between objects. All the structured semantics and geometry above are assembled to guide a global optimization for 3D scene modeling. Qualitative and quantitative analysis demonstrates the feasibility of our method in understanding and modeling semantics-enriched indoor scenes by evaluating the performance of reconstruction accuracy, computation performance and scene complexity.
* Accepted by Pattern Recognition
Morphing and Sampling Network for Dense Point Cloud Completion
Nov 30, 2019
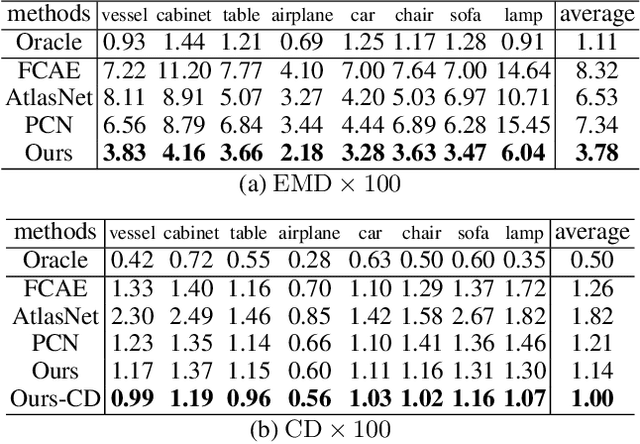
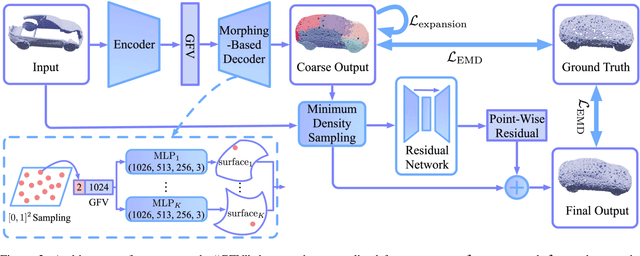
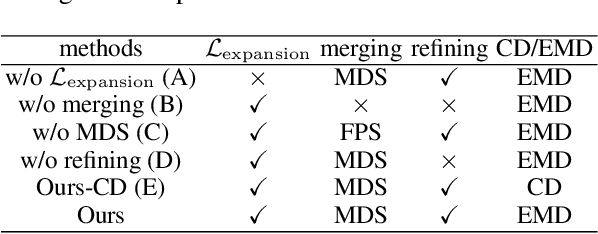
3D point cloud completion, the task of inferring the complete geometric shape from a partial point cloud, has been attracting attention in the community. For acquiring high-fidelity dense point clouds and avoiding uneven distribution, blurred details, or structural loss of existing methods' results, we propose a novel approach to complete the partial point cloud in two stages. Specifically, in the first stage, the approach predicts a complete but coarse-grained point cloud with a collection of parametric surface elements. Then, in the second stage, it merges the coarse-grained prediction with the input point cloud by a novel sampling algorithm. Our method utilizes a joint loss function to guide the distribution of the points. Extensive experiments verify the effectiveness of our method and demonstrate that it outperforms the existing methods in both the Earth Mover's Distance (EMD) and the Chamfer Distance (CD).
OptSample: A Resilient Buffer Management Policy for Robotic Systems based on Optimal Message Sampling
Sep 26, 2019
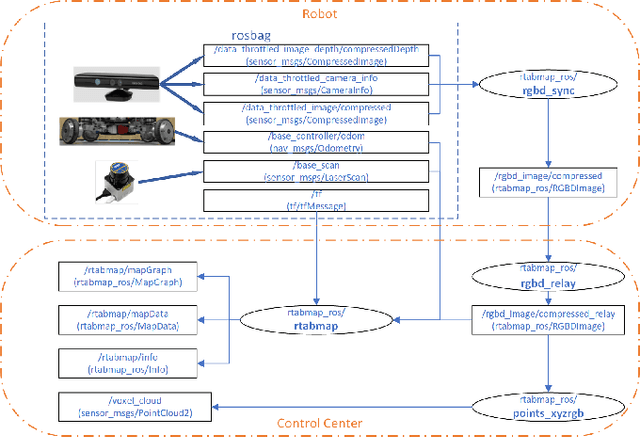
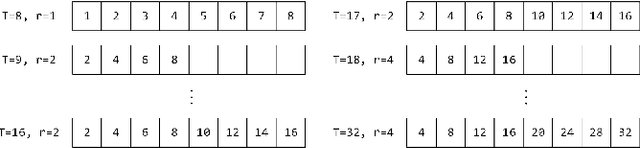
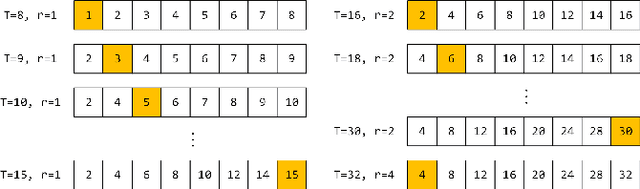
Modern robotic systems have become an alternative to humans to perform risky or exhausting tasks. In such application scenarios, communications between robots and the control center have become one of the major problems. Buffering is a commonly used solution to relieve temporary network disruption. But the assumption that newer messages are more valuable than older ones is not true for many application scenarios such as explorations, rescue operations, and surveillance. In this paper, we proposed a novel resilient buffer management policy named OptSample. It can uniformly sampling messages and dynamically adjust the sample rate based on run-time network situation. We define an evaluation function to estimate the profit of a message sequence. Based on the function, our analysis and simulation shows that the OptSample policy can effectively prevent losing long segment of continuous messages and improve the overall profit of the received messages. We implement the proposed policy in ROS. The implementation is transparent to user and no user code need to be changed. Experimental results on several application scenarios show that the OptSample policy can help robotic systems be more resilient against network disruption.
Example-Guided Style Consistent Image Synthesis from Semantic Labeling
Jun 04, 2019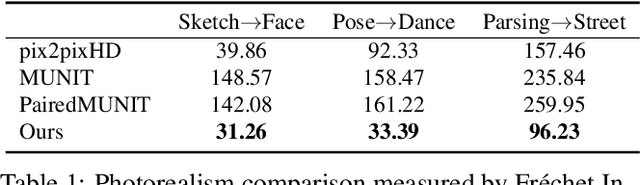
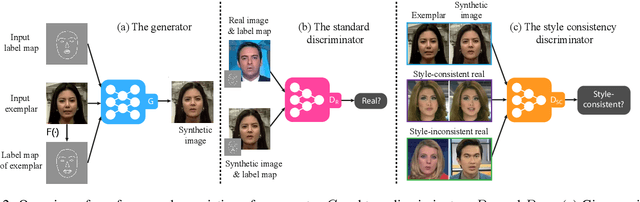
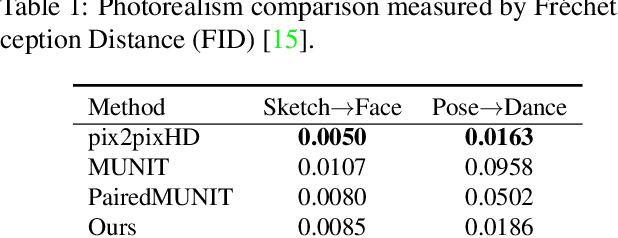
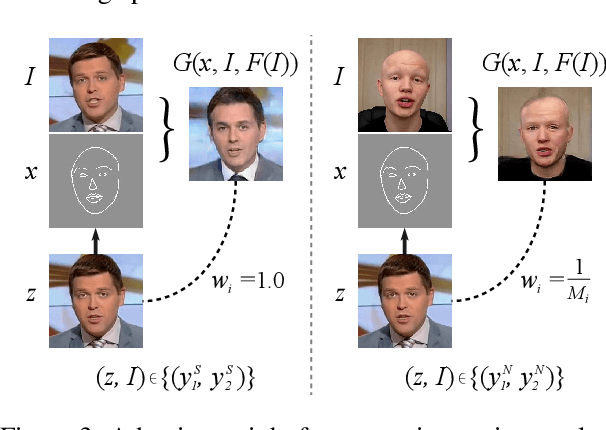
Example-guided image synthesis aims to synthesize an image from a semantic label map and an exemplary image indicating style. We use the term "style" in this problem to refer to implicit characteristics of images, for example: in portraits "style" includes gender, racial identity, age, hairstyle; in full body pictures it includes clothing; in street scenes, it refers to weather and time of day and such like. A semantic label map in these cases indicates facial expression, full body pose, or scene segmentation. We propose a solution to the example-guided image synthesis problem using conditional generative adversarial networks with style consistency. Our key contributions are (i) a novel style consistency discriminator to determine whether a pair of images are consistent in style; (ii) an adaptive semantic consistency loss; and (iii) a training data sampling strategy, for synthesizing style-consistent results to the exemplar.
FaceShapeGene: A Disentangled Shape Representation for Flexible Face Image Editing
May 06, 2019
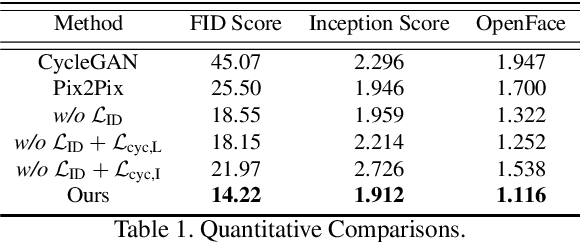
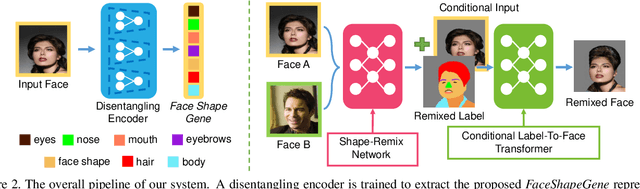
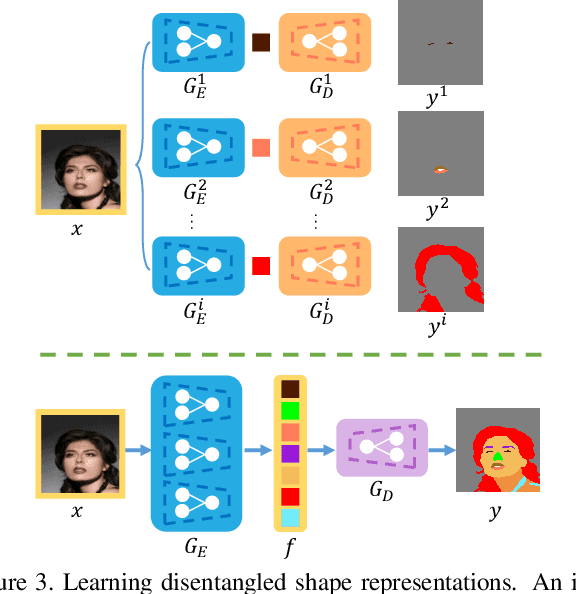
Existing methods for face image manipulation generally focus on editing the expression, changing some predefined attributes, or applying different filters. However, users lack the flexibility of controlling the shapes of different semantic facial parts in the generated face. In this paper, we propose an approach to compute a disentangled shape representation for a face image, namely the FaceShapeGene. The proposed FaceShapeGene encodes the shape information of each semantic facial part separately into a 1D latent vector. On the basis of the FaceShapeGene, a novel part-wise face image editing system is developed, which contains a shape-remix network and a conditional label-to-face transformer. The shape-remix network can freely recombine the part-wise latent vectors from different individuals, producing a remixed face shape in the form of a label map, which contains the facial characteristics of multiple subjects. The conditional label-to-face transformer, which is trained in an unsupervised cyclic manner, performs part-wise face editing while preserving the original identity of the subject. Experimental results on several tasks demonstrate that the proposed FaceShapeGene representation correctly disentangles the shape features of different semantic parts. %In addition, we test our system on several novel part-wise face editing tasks. Comparisons to existing methods demonstrate the superiority of the proposed method on accomplishing novel face editing tasks.
TZC: Efficient Inter-Process Communication for Robotics Middleware with Partial Serialization
Mar 01, 2019
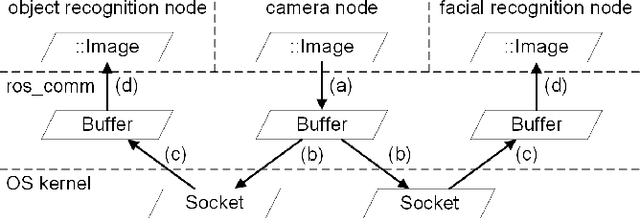
Inter-process communication (IPC) is one of the core functions of modern robotics middleware. We propose an efficient IPC technique called TZC (Towards Zero-Copy). As a core component of TZC, we design a novel algorithm called partial serialization. Our formulation can generate messages that can be divided into two parts. During message transmission, one part is transmitted through a socket and the other part uses shared memory. The part within shared memory is never copied or serialized during its lifetime. We have integrated TZC with ROS and ROS2 and find that TZC can be easily combined with current open-source platforms. By using TZC, the overhead of IPC remains constant when the message size grows. In particular, when the message size is 4MB (less than the size of a full HD image), TZC can reduce the overhead of ROS IPC from tens of milliseconds to hundreds of microseconds and can reduce the overhead of ROS2 IPC from hundreds of milliseconds to less than 1 millisecond. We also demonstrate the benefits of TZC by integrating with TurtleBot2 that are used in autonomous driving scenarios. We show that by using TZC, the braking distance can be shortened by 16% than ROS.
What and Where: A Context-based Recommendation System for Object Insertion
Nov 24, 2018

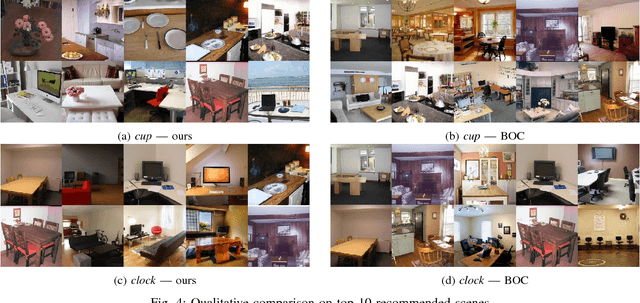

In this work, we propose a novel topic consisting of two dual tasks: 1) given a scene, recommend objects to insert, 2) given an object category, retrieve suitable background scenes. A bounding box for the inserted object is predicted in both tasks, which helps downstream applications such as semi-automated advertising and video composition. The major challenge lies in the fact that the target object is neither present nor localized at test time, whereas available datasets only provide scenes with existing objects. To tackle this problem, we build an unsupervised algorithm based on object-level contexts, which explicitly models the joint probability distribution of object categories and bounding boxes with a Gaussian mixture model. Experiments on our newly annotated test set demonstrate that our system outperforms existing baselines on all subtasks, and do so under a unified framework. Our contribution promises future extensions and applications.
Pose2Seg: Human Instance Segmentation Without Detection
Mar 28, 2018
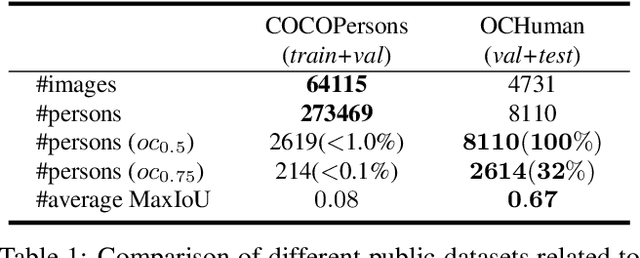


The general method of image instance segmentation is to perform the object detection first, and then segment the object from the detection bounding-box. More recently, deep learning methods like Mask R-CNN perform them jointly. However, little research takes into account the uniqueness of the "1human" category, which can be well defined by the pose skeleton. In this paper, we present a brand new pose-based instance segmentation framework for humans which separates instances based on human pose, not proposal region detection. We demonstrate that our pose-based framework can achieve similar accuracy to the detection-based approach, and can moreover better handle occlusion, which is the most challenging problem in the detection-based framework.
Chinese Text in the Wild
Feb 28, 2018
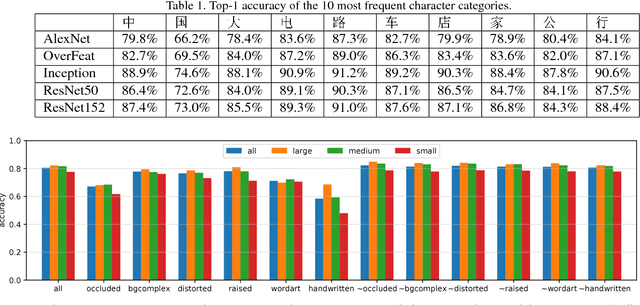


We introduce Chinese Text in the Wild, a very large dataset of Chinese text in street view images. While optical character recognition (OCR) in document images is well studied and many commercial tools are available, detection and recognition of text in natural images is still a challenging problem, especially for more complicated character sets such as Chinese text. Lack of training data has always been a problem, especially for deep learning methods which require massive training data. In this paper we provide details of a newly created dataset of Chinese text with about 1 million Chinese characters annotated by experts in over 30 thousand street view images. This is a challenging dataset with good diversity. It contains planar text, raised text, text in cities, text in rural areas, text under poor illumination, distant text, partially occluded text, etc. For each character in the dataset, the annotation includes its underlying character, its bounding box, and 6 attributes. The attributes indicate whether it has complex background, whether it is raised, whether it is handwritten or printed, etc. The large size and diversity of this dataset make it suitable for training robust neural networks for various tasks, particularly detection and recognition. We give baseline results using several state-of-the-art networks, including AlexNet, OverFeat, Google Inception and ResNet for character recognition, and YOLOv2 for character detection in images. Overall Google Inception has the best performance on recognition with 80.5% top-1 accuracy, while YOLOv2 achieves an mAP of 71.0% on detection. Dataset, source code and trained models will all be publicly available on the website.
$S^4$Net: Single Stage Salient-Instance Segmentation
Nov 21, 2017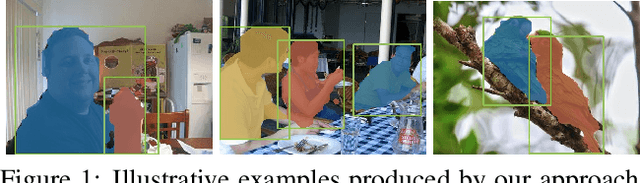
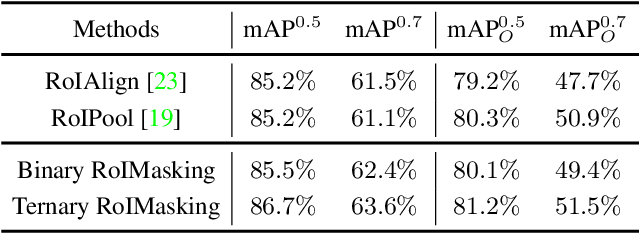
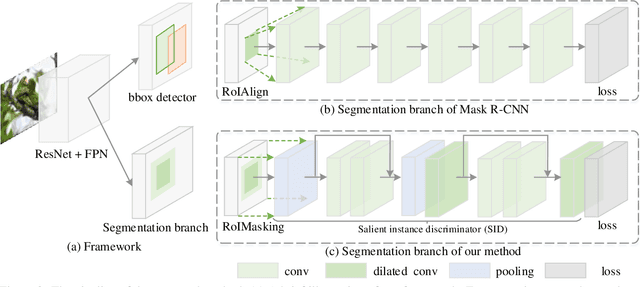

In this paper, we consider an interesting vision problem---salient instance segmentation. Other than producing approximate bounding boxes, our network also outputs high-quality instance-level segments. Taking into account the category-independent property of each target, we design a single stage salient instance segmentation framework, with a novel segmentation branch. Our new branch regards not only local context inside each detection window but also its surrounding context, enabling us to distinguish the instances in the same scope even with obstruction. Our network is end-to-end trainable and runs at a fast speed (40 fps when processing an image with resolution $320 \times 320$). We evaluate our approach on a public available benchmark and show that it outperforms other alternative solutions. In addition, we also provide a thorough analysis of the design choices to help readers better understand the functions of each part of our network. To facilitate the development of this area, our code will be available at \url{https://github.com/RuochenFan/S4Net}.