 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Proactive Coding Assistants in Real-World Software Development
May 07, 2026Large language model (LLM)-based coding assistants have made substantial progress, yet most systems remain reactive, requiring developers to explicitly formulate their needs. Proactive coding assistants aim to infer latent developer intent from integrated development environment (IDE) interactions and repository context, thereby reducing interaction overhead and supporting more seamless assistance. However, research in this direction is limited by the scarcity of large-scale real-world developer behavior data. Existing studies therefore often rely on LLM-simulated IDE traces, whose fidelity to real development behavior remains unclear. In this paper, we investigate this simulation-to-reality gap through a large-scale empirical study. We collect real IDE interaction traces from 1{,}246 experienced industry developers over three consecutive days using a custom Visual Studio Code extension, and construct paired LLM-simulated traces for controlled comparison. Our analysis shows that simulated traces differ substantially from real traces in behavioral diversity, temporal structure, and exploratory patterns. Based on the collected data, we introduce \textbf{ProCodeBench}, a real-world benchmark for proactive intent prediction. Experiments with representative LLMs, retrieval-augmented methods, and agentic baselines show that current approaches remain far from reliable under real IDE traces, suggesting that simulation-based evaluation can overestimate real-world performance. Finally, our training study shows that simulated data cannot replace real data, but can complement it when used before real-world fine-tuning. These findings highlight the importance of real developer behavior data for evaluating and training proactive coding assistants.
Theoretically Achieving Continuous Representation of Oriented Bounding Boxes
Feb 29, 2024Considerable efforts have been devoted to Oriented Object Detection (OOD). However, one lasting issue regarding the discontinuity in Oriented Bounding Box (OBB) representation remains unresolved, which is an inherent bottleneck for extant OOD methods. This paper endeavors to completely solve this issue in a theoretically guaranteed manner and puts an end to the ad-hoc efforts in this direction. Prior studies typically can only address one of the two cases of discontinuity: rotation and aspect ratio, and often inadvertently introduce decoding discontinuity, e.g. Decoding Incompleteness (DI) and Decoding Ambiguity (DA) as discussed in literature. Specifically, we propose a novel representation method called Continuous OBB (COBB), which can be readily integrated into existing detectors e.g. Faster-RCNN as a plugin. It can theoretically ensure continuity in bounding box regression which to our best knowledge, has not been achieved in literature for rectangle-based object representation. For fairness and transparency of experiments, we have developed a modularized benchmark based on the open-source deep learning framework Jittor's detection toolbox JDet for OOD evaluation. On the popular DOTA dataset, by integrating Faster-RCNN as the same baseline model, our new method outperforms the peer method Gliding Vertex by 1.13% mAP50 (relative improvement 1.54%), and 2.46% mAP75 (relative improvement 5.91%), without any tricks.
Semantic-Aware Transformation-Invariant RoI Align
Dec 15, 2023



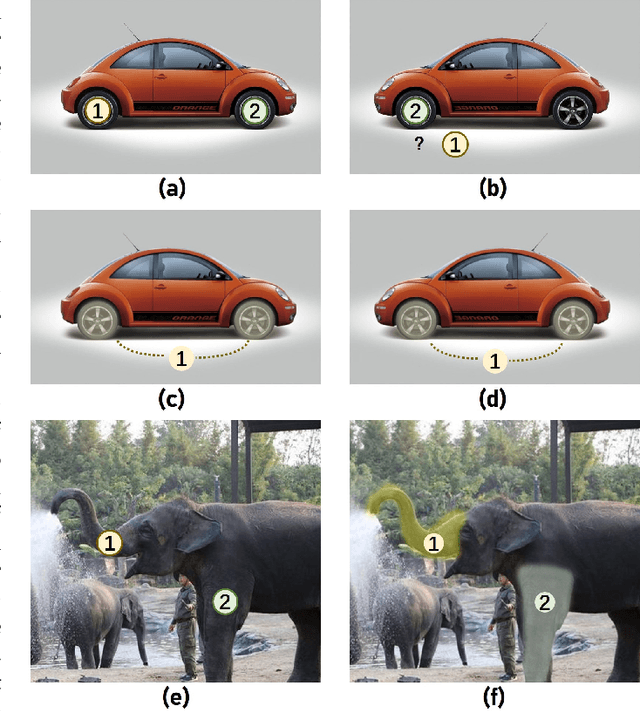
Great progress has been made in learning-based object detection methods in the last decade. Two-stage detectors often have higher detection accuracy than one-stage detectors, due to the use of region of interest (RoI) feature extractors which extract transformation-invariant RoI features for different RoI proposals, making refinement of bounding boxes and prediction of object categories more robust and accurate. However, previous RoI feature extractors can only extract invariant features under limited transformations. In this paper, we propose a novel RoI feature extractor, termed Semantic RoI Align (SRA), which is capable of extracting invariant RoI features under a variety of transformations for two-stage detectors. Specifically, we propose a semantic attention module to adaptively determine different sampling areas by leveraging the global and local semantic relationship within the RoI. We also propose a Dynamic Feature Sampler which dynamically samples features based on the RoI aspect ratio to enhance the efficiency of SRA, and a new position embedding, \ie Area Embedding, to provide more accurate position information for SRA through an improved sampling area representation. Experiments show that our model significantly outperforms baseline models with slight computational overhead. In addition, it shows excellent generalization ability and can be used to improve performance with various state-of-the-art backbones and detection methods.
Sampling Equivariant Self-attention Networks for Object Detection in Aerial Images
Nov 05, 2021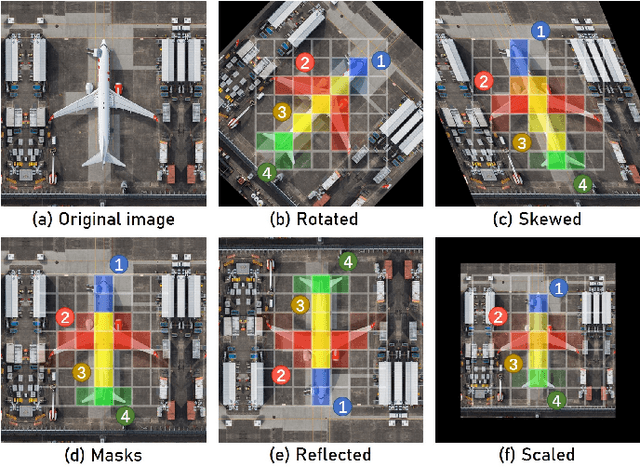
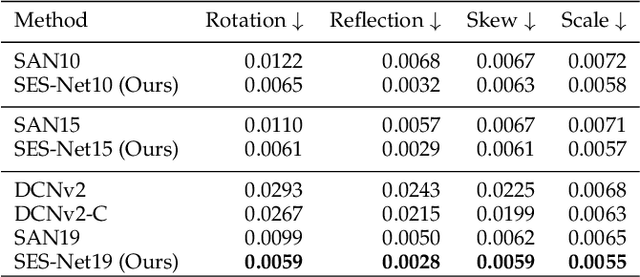
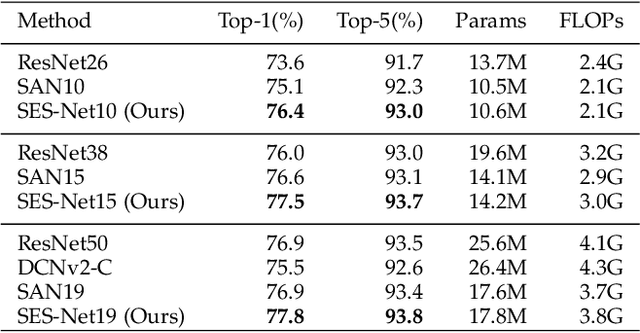
Objects in aerial images have greater variations in scale and orientation than in typical images, so detection is more difficult. Convolutional neural networks use a variety of frequency- and orientation-specific kernels to identify objects subject to different transformations; these require many parameters. Sampling equivariant networks can adjust sampling from input feature maps according to the transformation of the object, allowing a kernel to extract features of an object under different transformations. Doing so requires fewer parameters, and makes the network more suitable for representing deformable objects, like those in aerial images. However, methods like deformable convolutional networks can only provide sampling equivariance under certain circumstances, because of the locations used for sampling. We propose sampling equivariant self-attention networks which consider self-attention restricted to a local image patch as convolution sampling with masks instead of locations, and design a transformation embedding module to further improve the equivariant sampling ability. We also use a novel randomized normalization module to tackle overfitting due to limited aerial image data. We show that our model (i) provides significantly better sampling equivariance than existing methods, without additional supervision, (ii) provides improved classification on ImageNet, and (iii) achieves state-of-the-art results on the DOTA dataset, without increased computation.
Example-Guided Style Consistent Image Synthesis from Semantic Labeling
Jun 04, 2019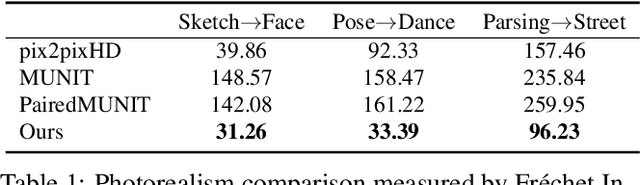
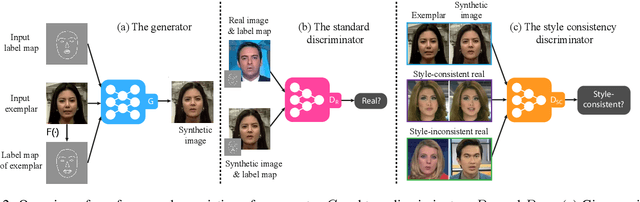
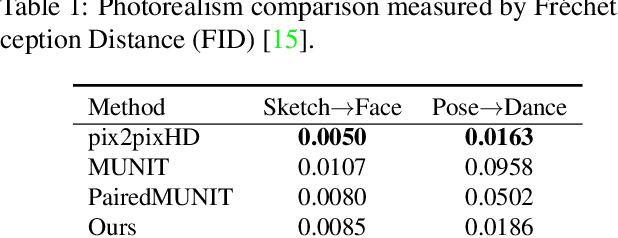
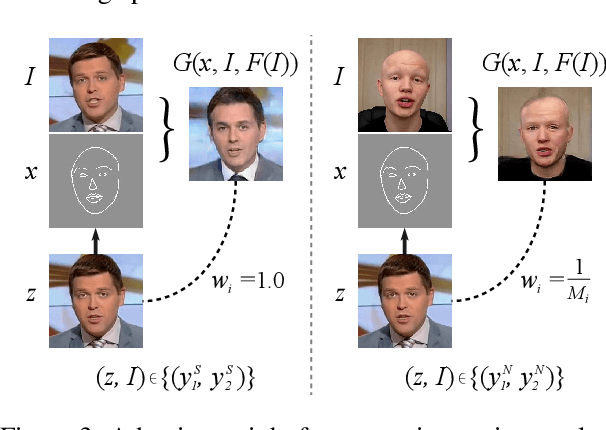
Example-guided image synthesis aims to synthesize an image from a semantic label map and an exemplary image indicating style. We use the term "style" in this problem to refer to implicit characteristics of images, for example: in portraits "style" includes gender, racial identity, age, hairstyle; in full body pictures it includes clothing; in street scenes, it refers to weather and time of day and such like. A semantic label map in these cases indicates facial expression, full body pose, or scene segmentation. We propose a solution to the example-guided image synthesis problem using conditional generative adversarial networks with style consistency. Our key contributions are (i) a novel style consistency discriminator to determine whether a pair of images are consistent in style; (ii) an adaptive semantic consistency loss; and (iii) a training data sampling strategy, for synthesizing style-consistent results to the exemplar.