 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models
Mar 19, 2026Diffusion transformers have demonstrated remarkable capabilities in generating videos. However, their practical deployment is severely constrained by high memory usage and computational cost. Post-Training Quantization provides a practical way to reduce memory usage and boost computation speed. Existing quantization methods typically apply a static bit-width allocation, overlooking the quantization difficulty of activations across diffusion timesteps, leading to a suboptimal trade-off between efficiency and quality. In this paper, we propose a inference time NVFP4/INT8 Mixed-Precision Quantization framework. We find a strong linear correlation between a block's input-output difference and the quantization sensitivity of its internal linear layers. Based on this insight, we design a lightweight predictor that dynamically allocates NVFP4 to temporally stable layers to maximize memory compression, while selectively preserving INT8 for volatile layers to ensure robustness. This adaptive precision strategy enables aggressive quantization without compromising generation quality. Beside this, we observe that the residual between the input and output of a Transformer block exhibits high temporal consistency across timesteps. Leveraging this temporal redundancy, we introduce Temporal Delta Cache (TDC) to skip computations for these invariant blocks, further reducing the computational cost. Extensive experiments demonstrate that our method achieves 1.92$\times$ end-to-end acceleration and 3.32$\times$ memory reduction, setting a new baseline for efficient inference in Video DiTs.
DiTFastAttnV2: Head-wise Attention Compression for Multi-Modality Diffusion Transformers
Mar 28, 2025
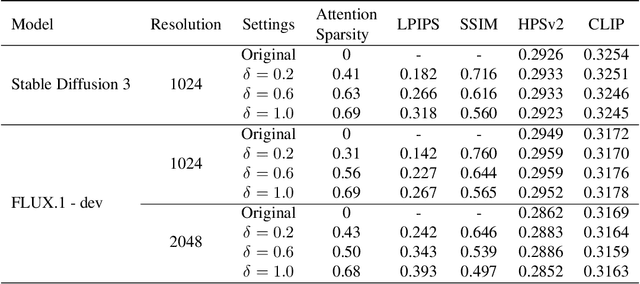
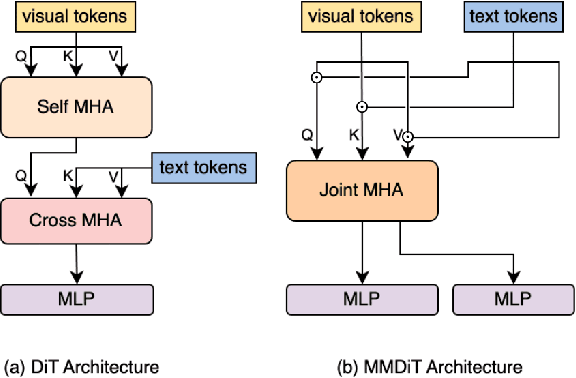
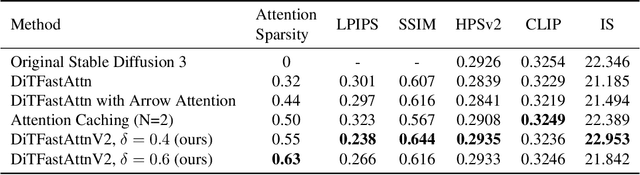
Text-to-image generation models, especially Multimodal Diffusion Transformers (MMDiT), have shown remarkable progress in generating high-quality images. However, these models often face significant computational bottlenecks, particularly in attention mechanisms, which hinder their scalability and efficiency. In this paper, we introduce DiTFastAttnV2, a post-training compression method designed to accelerate attention in MMDiT. Through an in-depth analysis of MMDiT's attention patterns, we identify key differences from prior DiT-based methods and propose head-wise arrow attention and caching mechanisms to dynamically adjust attention heads, effectively bridging this gap. We also design an Efficient Fused Kernel for further acceleration. By leveraging local metric methods and optimization techniques, our approach significantly reduces the search time for optimal compression schemes to just minutes while maintaining generation quality. Furthermore, with the customized kernel, DiTFastAttnV2 achieves a 68% reduction in attention FLOPs and 1.5x end-to-end speedup on 2K image generation without compromising visual fidelity.