 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing 3D Gaussian Splatting for Sparse Viewpoint Scene Reconstruction
Sep 05, 2024



3D Gaussian Splatting (3DGS) has emerged as a promising approach for 3D scene representation, offering a reduction in computational overhead compared to Neural Radiance Fields (NeRF). However, 3DGS is susceptible to high-frequency artifacts and demonstrates suboptimal performance under sparse viewpoint conditions, thereby limiting its applicability in robotics and computer vision. To address these limitations, we introduce SVS-GS, a novel framework for Sparse Viewpoint Scene reconstruction that integrates a 3D Gaussian smoothing filter to suppress artifacts. Furthermore, our approach incorporates a Depth Gradient Profile Prior (DGPP) loss with a dynamic depth mask to sharpen edges and 2D diffusion with Score Distillation Sampling (SDS) loss to enhance geometric consistency in novel view synthesis. Experimental evaluations on the MipNeRF-360 and SeaThru-NeRF datasets demonstrate that SVS-GS markedly improves 3D reconstruction from sparse viewpoints, offering a robust and efficient solution for scene understanding in robotics and computer vision applications.
Generalizing Deepfake Video Detection with Plug-and-Play: Video-Level Blending and Spatiotemporal Adapter Tuning
Aug 30, 2024



Three key challenges hinder the development of current deepfake video detection: (1) Temporal features can be complex and diverse: how can we identify general temporal artifacts to enhance model generalization? (2) Spatiotemporal models often lean heavily on one type of artifact and ignore the other: how can we ensure balanced learning from both? (3) Videos are naturally resource-intensive: how can we tackle efficiency without compromising accuracy? This paper attempts to tackle the three challenges jointly. First, inspired by the notable generality of using image-level blending data for image forgery detection, we investigate whether and how video-level blending can be effective in video. We then perform a thorough analysis and identify a previously underexplored temporal forgery artifact: Facial Feature Drift (FFD), which commonly exists across different forgeries. To reproduce FFD, we then propose a novel Video-level Blending data (VB), where VB is implemented by blending the original image and its warped version frame-by-frame, serving as a hard negative sample to mine more general artifacts. Second, we carefully design a lightweight Spatiotemporal Adapter (StA) to equip a pretrained image model (both ViTs and CNNs) with the ability to capture both spatial and temporal features jointly and efficiently. StA is designed with two-stream 3D-Conv with varying kernel sizes, allowing it to process spatial and temporal features separately. Extensive experiments validate the effectiveness of the proposed methods; and show our approach can generalize well to previously unseen forgery videos, even the just-released (in 2024) SoTAs. We release our code and pretrained weights at \url{https://github.com/YZY-stack/StA4Deepfake}.
ScalingGaussian: Enhancing 3D Content Creation with Generative Gaussian Splatting
Jul 26, 2024



The creation of high-quality 3D assets is paramount for applications in digital heritage preservation, entertainment, and robotics. Traditionally, this process necessitates skilled professionals and specialized software for the modeling, texturing, and rendering of 3D objects. However, the rising demand for 3D assets in gaming and virtual reality (VR) has led to the creation of accessible image-to-3D technologies, allowing non-professionals to produce 3D content and decreasing dependence on expert input. Existing methods for 3D content generation struggle to simultaneously achieve detailed textures and strong geometric consistency. We introduce a novel 3D content creation framework, ScalingGaussian, which combines 3D and 2D diffusion models to achieve detailed textures and geometric consistency in generated 3D assets. Initially, a 3D diffusion model generates point clouds, which are then densified through a process of selecting local regions, introducing Gaussian noise, followed by using local density-weighted selection. To refine the 3D gaussians, we utilize a 2D diffusion model with Score Distillation Sampling (SDS) loss, guiding the 3D Gaussians to clone and split. Finally, the 3D Gaussians are converted into meshes, and the surface textures are optimized using Mean Square Error(MSE) and Gradient Profile Prior(GPP) losses. Our method addresses the common issue of sparse point clouds in 3D diffusion, resulting in improved geometric structure and detailed textures. Experiments on image-to-3D tasks demonstrate that our approach efficiently generates high-quality 3D assets.
DF40: Toward Next-Generation Deepfake Detection
Jun 19, 2024



We propose a new comprehensive benchmark to revolutionize the current deepfake detection field to the next generation. Predominantly, existing works identify top-notch detection algorithms and models by adhering to the common practice: training detectors on one specific dataset (e.g., FF++) and testing them on other prevalent deepfake datasets. This protocol is often regarded as a "golden compass" for navigating SoTA detectors. But can these stand-out "winners" be truly applied to tackle the myriad of realistic and diverse deepfakes lurking in the real world? If not, what underlying factors contribute to this gap? In this work, we found the dataset (both train and test) can be the "primary culprit" due to: (1) forgery diversity: Deepfake techniques are commonly referred to as both face forgery (face-swapping and face-reenactment) and entire image synthesis (AIGC). Most existing datasets only contain partial types, with limited forgery methods implemented; (2) forgery realism: The dominant training dataset, FF++, contains old forgery techniques from the past five years. "Honing skills" on these forgeries makes it difficult to guarantee effective detection of nowadays' SoTA deepfakes; (3) evaluation protocol: Most detection works perform evaluations on one type, e.g., train and test on face-swapping only, which hinders the development of universal deepfake detectors. To address this dilemma, we construct a highly diverse and large-scale deepfake dataset called DF40, which comprises 40 distinct deepfake techniques. We then conduct comprehensive evaluations using 4 standard evaluation protocols and 7 representative detectors, resulting in over 2,000 evaluations. Through these evaluations, we analyze from various perspectives, leading to 12 new insightful findings contributing to the field. We also open up 5 valuable yet previously underexplored research questions to inspire future works.
Rank-based No-reference Quality Assessment for Face Swapping
Jun 04, 2024



Face swapping has become a prominent research area in computer vision and image processing due to rapid technological advancements. The metric of measuring the quality in most face swapping methods relies on several distances between the manipulated images and the source image, or the target image, i.e., there are suitable known reference face images. Therefore, there is still a gap in accurately assessing the quality of face interchange in reference-free scenarios. In this study, we present a novel no-reference image quality assessment (NR-IQA) method specifically designed for face swapping, addressing this issue by constructing a comprehensive large-scale dataset, implementing a method for ranking image quality based on multiple facial attributes, and incorporating a Siamese network based on interpretable qualitative comparisons. Our model demonstrates the state-of-the-art performance in the quality assessment of swapped faces, providing coarse- and fine-grained. Enhanced by this metric, an improved face-swapping model achieved a more advanced level with respect to expressions and poses. Extensive experiments confirm the superiority of our method over existing general no-reference image quality assessment metrics and the latest metric of facial image quality assessment, making it well suited for evaluating face swapping images in real-world scenarios.
Contrastive Pseudo Learning for Open-World DeepFake Attribution
Sep 20, 2023The challenge in sourcing attribution for forgery faces has gained widespread attention due to the rapid development of generative techniques. While many recent works have taken essential steps on GAN-generated faces, more threatening attacks related to identity swapping or expression transferring are still overlooked. And the forgery traces hidden in unknown attacks from the open-world unlabeled faces still remain under-explored. To push the related frontier research, we introduce a new benchmark called Open-World DeepFake Attribution (OW-DFA), which aims to evaluate attribution performance against various types of fake faces under open-world scenarios. Meanwhile, we propose a novel framework named Contrastive Pseudo Learning (CPL) for the OW-DFA task through 1) introducing a Global-Local Voting module to guide the feature alignment of forged faces with different manipulated regions, 2) designing a Confidence-based Soft Pseudo-label strategy to mitigate the pseudo-noise caused by similar methods in unlabeled set. In addition, we extend the CPL framework with a multi-stage paradigm that leverages pre-train technique and iterative learning to further enhance traceability performance. Extensive experiments verify the superiority of our proposed method on the OW-DFA and also demonstrate the interpretability of deepfake attribution task and its impact on improving the security of deepfake detection area.
Continual Face Forgery Detection via Historical Distribution Preserving
Aug 11, 2023



Face forgery techniques have advanced rapidly and pose serious security threats. Existing face forgery detection methods try to learn generalizable features, but they still fall short of practical application. Additionally, finetuning these methods on historical training data is resource-intensive in terms of time and storage. In this paper, we focus on a novel and challenging problem: Continual Face Forgery Detection (CFFD), which aims to efficiently learn from new forgery attacks without forgetting previous ones. Specifically, we propose a Historical Distribution Preserving (HDP) framework that reserves and preserves the distributions of historical faces. To achieve this, we use universal adversarial perturbation (UAP) to simulate historical forgery distribution, and knowledge distillation to maintain the distribution variation of real faces across different models. We also construct a new benchmark for CFFD with three evaluation protocols. Our extensive experiments on the benchmarks show that our method outperforms the state-of-the-art competitors.
Towards General Visual-Linguistic Face Forgery Detection
Jul 31, 2023



Deepfakes are realistic face manipulations that can pose serious threats to security, privacy, and trust. Existing methods mostly treat this task as binary classification, which uses digital labels or mask signals to train the detection model. We argue that such supervisions lack semantic information and interpretability. To address this issues, in this paper, we propose a novel paradigm named Visual-Linguistic Face Forgery Detection(VLFFD), which uses fine-grained sentence-level prompts as the annotation. Since text annotations are not available in current deepfakes datasets, VLFFD first generates the mixed forgery image with corresponding fine-grained prompts via Prompt Forgery Image Generator (PFIG). Then, the fine-grained mixed data and coarse-grained original data and is jointly trained with the Coarse-and-Fine Co-training framework (C2F), enabling the model to gain more generalization and interpretability. The experiments show the proposed method improves the existing detection models on several challenging benchmarks.
Artificial Intelligence Security Competition (AISC)
Dec 07, 2022



The security of artificial intelligence (AI) is an important research area towards safe, reliable, and trustworthy AI systems. To accelerate the research on AI security, the Artificial Intelligence Security Competition (AISC) was organized by the Zhongguancun Laboratory, China Industrial Control Systems Cyber Emergency Response Team, Institute for Artificial Intelligence, Tsinghua University, and RealAI as part of the Zhongguancun International Frontier Technology Innovation Competition (https://www.zgc-aisc.com/en). The competition consists of three tracks, including Deepfake Security Competition, Autonomous Driving Security Competition, and Face Recognition Security Competition. This report will introduce the competition rules of these three tracks and the solutions of top-ranking teams in each track.
Exploiting Fine-grained Face Forgery Clues via Progressive Enhancement Learning
Dec 28, 2021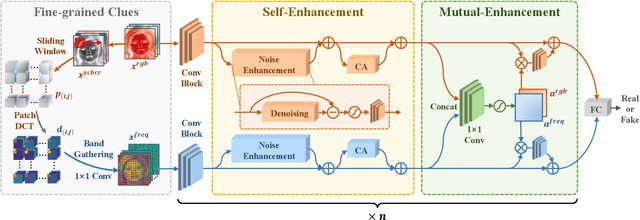
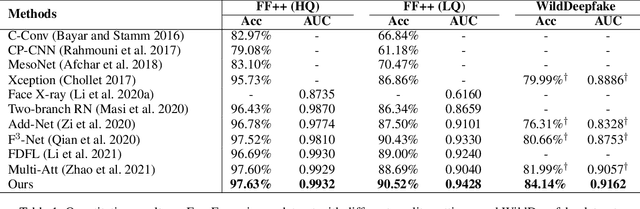
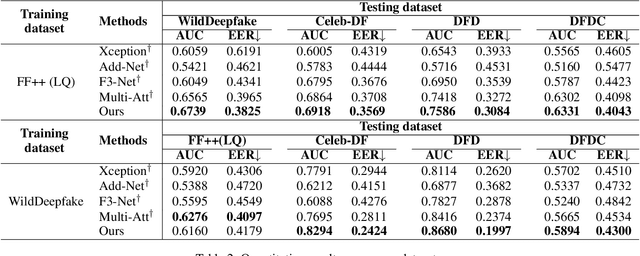

With the rapid development of facial forgery techniques, forgery detection has attracted more and more attention due to security concerns. Existing approaches attempt to use frequency information to mine subtle artifacts under high-quality forged faces. However, the exploitation of frequency information is coarse-grained, and more importantly, their vanilla learning process struggles to extract fine-grained forgery traces. To address this issue, we propose a progressive enhancement learning framework to exploit both the RGB and fine-grained frequency clues. Specifically, we perform a fine-grained decomposition of RGB images to completely decouple the real and fake traces in the frequency space. Subsequently, we propose a progressive enhancement learning framework based on a two-branch network, combined with self-enhancement and mutual-enhancement modules. The self-enhancement module captures the traces in different input spaces based on spatial noise enhancement and channel attention. The Mutual-enhancement module concurrently enhances RGB and frequency features by communicating in the shared spatial dimension. The progressive enhancement process facilitates the learning of discriminative features with fine-grained face forgery clues. Extensive experiments on several datasets show that our method outperforms the state-of-the-art face forgery detection methods.