 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Reasoning Elicits Controllable 3D Scene Generation
Sep 18, 2025



Existing 3D scene generation methods often struggle to model the complex logical dependencies and physical constraints between objects, limiting their ability to adapt to dynamic and realistic environments. We propose CausalStruct, a novel framework that embeds causal reasoning into 3D scene generation. Utilizing large language models (LLMs), We construct causal graphs where nodes represent objects and attributes, while edges encode causal dependencies and physical constraints. CausalStruct iteratively refines the scene layout by enforcing causal order to determine the placement order of objects and applies causal intervention to adjust the spatial configuration according to physics-driven constraints, ensuring consistency with textual descriptions and real-world dynamics. The refined scene causal graph informs subsequent optimization steps, employing a Proportional-Integral-Derivative(PID) controller to iteratively tune object scales and positions. Our method uses text or images to guide object placement and layout in 3D scenes, with 3D Gaussian Splatting and Score Distillation Sampling improving shape accuracy and rendering stability. Extensive experiments show that CausalStruct generates 3D scenes with enhanced logical coherence, realistic spatial interactions, and robust adaptability.
Bayesian Optimization for Controlled Image Editing via LLMs
Feb 26, 2025



In the rapidly evolving field of image generation, achieving precise control over generated content and maintaining semantic consistency remain significant limitations, particularly concerning grounding techniques and the necessity for model fine-tuning. To address these challenges, we propose BayesGenie, an off-the-shelf approach that integrates Large Language Models (LLMs) with Bayesian Optimization to facilitate precise and user-friendly image editing. Our method enables users to modify images through natural language descriptions without manual area marking, while preserving the original image's semantic integrity. Unlike existing techniques that require extensive pre-training or fine-tuning, our approach demonstrates remarkable adaptability across various LLMs through its model-agnostic design. BayesGenie employs an adapted Bayesian optimization strategy to automatically refine the inference process parameters, achieving high-precision image editing with minimal user intervention. Through extensive experiments across diverse scenarios, we demonstrate that our framework significantly outperforms existing methods in both editing accuracy and semantic preservation, as validated using different LLMs including Claude3 and GPT-4.
The Role of Deductive and Inductive Reasoning in Large Language Models
Oct 03, 2024



Large Language Models (LLMs) have achieved substantial progress in artificial intelligence, particularly in reasoning tasks. However, their reliance on static prompt structures, coupled with limited dynamic reasoning capabilities, often constrains their adaptability to complex and evolving problem spaces. In this paper, we propose the Deductive and InDuctive(DID) method, which enhances LLM reasoning by dynamically integrating both deductive and inductive reasoning within the prompt construction process. Drawing inspiration from cognitive science, the DID approach mirrors human adaptive reasoning mechanisms, offering a flexible framework that allows the model to adjust its reasoning pathways based on task context and performance. We empirically validate the efficacy of DID on established datasets such as AIW and MR-GSM8K, as well as on our custom dataset, Holiday Puzzle, which presents tasks about different holiday date calculating challenges. By leveraging DID's hybrid prompt strategy, we demonstrate significant improvements in both solution accuracy and reasoning quality, achieved without imposing substantial computational overhead. Our findings suggest that DID provides a more robust and cognitively aligned framework for reasoning in LLMs, contributing to the development of advanced LLM-driven problem-solving strategies informed by cognitive science models.
ScalingGaussian: Enhancing 3D Content Creation with Generative Gaussian Splatting
Jul 26, 2024



The creation of high-quality 3D assets is paramount for applications in digital heritage preservation, entertainment, and robotics. Traditionally, this process necessitates skilled professionals and specialized software for the modeling, texturing, and rendering of 3D objects. However, the rising demand for 3D assets in gaming and virtual reality (VR) has led to the creation of accessible image-to-3D technologies, allowing non-professionals to produce 3D content and decreasing dependence on expert input. Existing methods for 3D content generation struggle to simultaneously achieve detailed textures and strong geometric consistency. We introduce a novel 3D content creation framework, ScalingGaussian, which combines 3D and 2D diffusion models to achieve detailed textures and geometric consistency in generated 3D assets. Initially, a 3D diffusion model generates point clouds, which are then densified through a process of selecting local regions, introducing Gaussian noise, followed by using local density-weighted selection. To refine the 3D gaussians, we utilize a 2D diffusion model with Score Distillation Sampling (SDS) loss, guiding the 3D Gaussians to clone and split. Finally, the 3D Gaussians are converted into meshes, and the surface textures are optimized using Mean Square Error(MSE) and Gradient Profile Prior(GPP) losses. Our method addresses the common issue of sparse point clouds in 3D diffusion, resulting in improved geometric structure and detailed textures. Experiments on image-to-3D tasks demonstrate that our approach efficiently generates high-quality 3D assets.
Full-Body Motion Reconstruction with Sparse Sensing from Graph Perspective
Jan 22, 2024Estimating 3D full-body pose from sparse sensor data is a pivotal technique employed for the reconstruction of realistic human motions in Augmented Reality and Virtual Reality. However, translating sparse sensor signals into comprehensive human motion remains a challenge since the sparsely distributed sensors in common VR systems fail to capture the motion of full human body. In this paper, we use well-designed Body Pose Graph (BPG) to represent the human body and translate the challenge into a prediction problem of graph missing nodes. Then, we propose a novel full-body motion reconstruction framework based on BPG. To establish BPG, nodes are initially endowed with features extracted from sparse sensor signals. Features from identifiable joint nodes across diverse sensors are amalgamated and processed from both temporal and spatial perspectives. Temporal dynamics are captured using the Temporal Pyramid Structure, while spatial relations in joint movements inform the spatial attributes. The resultant features serve as the foundational elements of the BPG nodes. To further refine the BPG, node features are updated through a graph neural network that incorporates edge reflecting varying joint relations. Our method's effectiveness is evidenced by the attained state-of-the-art performance, particularly in lower body motion, outperforming other baseline methods. Additionally, an ablation study validates the efficacy of each module in our proposed framework.
BVIP Guiding System with Adaptability to Individual Differences
Apr 15, 2023Guiding robots can not only detect close-range obstacles like other guiding tools, but also extend its range to perceive the environment when making decisions. However, most existing works over-simplified the interaction between human agents and robots, ignoring the differences between individuals, resulting in poor experiences for different users. To solve the problem, we propose a data-driven guiding system to cope with the effect brighten by individual differences. In our guiding system, we design a Human Motion Predictor (HMP) and a Robot Dynamics Model (RDM) based on deep neural network, the time convolutional network (TCN) is verified to have the best performance, to predict differences in interaction between different human agents and robots. To train our models, we collected datasets that records the interactions from different human agents. Moreover, given the predictive information of the specific user, we propose a waypoints selector that allows the robot to naturally adapt to the user's state changes, which are mainly reflected in the walking speed. We compare the performance of our models with previous works and achieve significant performance improvements. On this basis, our guiding system demonstrated good adaptability to different human agents. Our guiding system is deployed on a real quadruped robot to verify the practicability.
Graph based Environment Representation for Vision-and-Language Navigation in Continuous Environments
Jan 11, 2023



Vision-and-Language Navigation in Continuous Environments (VLN-CE) is a navigation task that requires an agent to follow a language instruction in a realistic environment. The understanding of environments is a crucial part of the VLN-CE task, but existing methods are relatively simple and direct in understanding the environment, without delving into the relationship between language instructions and visual environments. Therefore, we propose a new environment representation in order to solve the above problems. First, we propose an Environment Representation Graph (ERG) through object detection to express the environment in semantic level. This operation enhances the relationship between language and environment. Then, the relational representations of object-object, object-agent in ERG are learned through GCN, so as to obtain a continuous expression about ERG. Sequentially, we combine the ERG expression with object label embeddings to obtain the environment representation. Finally, a new cross-modal attention navigation framework is proposed, incorporating our environment representation and a special loss function dedicated to training ERG. Experimental result shows that our method achieves satisfactory performance in terms of success rate on VLN-CE tasks. Further analysis explains that our method attains better cross-modal matching and strong generalization ability.
Few-shot Domain Adaptation for IMU Denoising
Jan 05, 2022
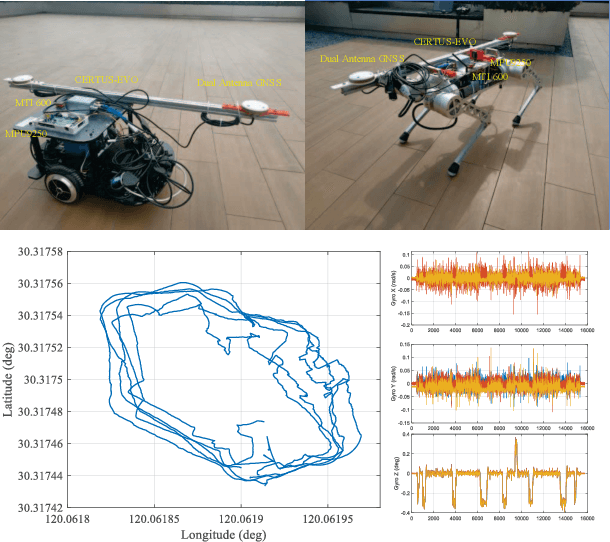
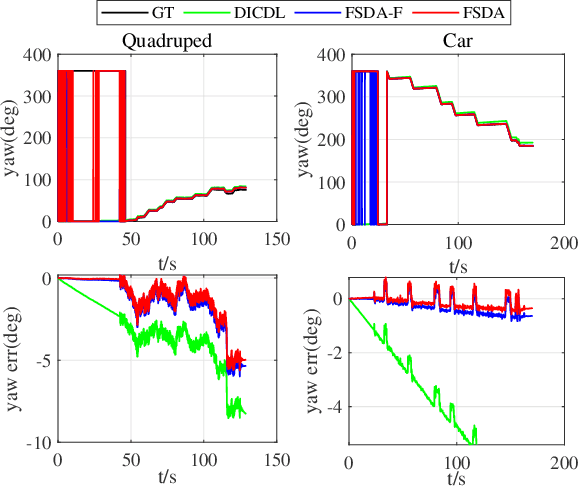
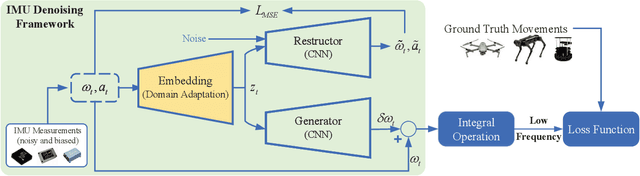
Different application scenarios will cause IMU to exhibit different error characteristics which will cause trouble to robot application. However, most data processing methods need to be designed for specific scenario. To solve this problem, we propose a few-shot domain adaptation method. In this work, a domain adaptation framework is considered for denoising the IMU, a reconstitution loss is designed to improve domain adaptability. In addition, in order to further improve the adaptability in the case of limited data, a few-shot training strategy is adopted. In the experiment, we quantify our method on two datasets (EuRoC and TUM-VI) and two real robots (car and quadruped robot) with three different precision IMUs. According to the experimental results, the adaptability of our framework is verified by t-SNE. In orientation results, our proposed method shows the great denoising performance.
Visual Perception Generalization for Vision-and-Language Navigation via Meta-Learning
Jan 19, 2021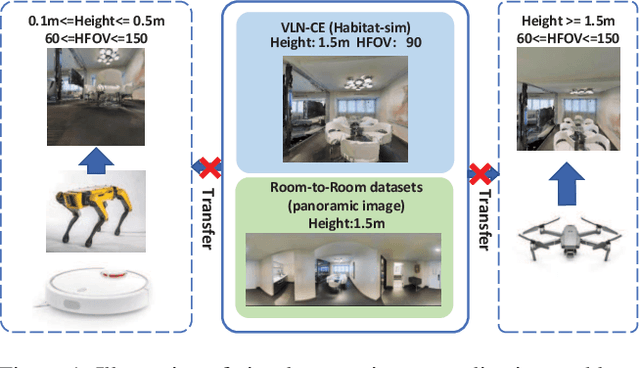
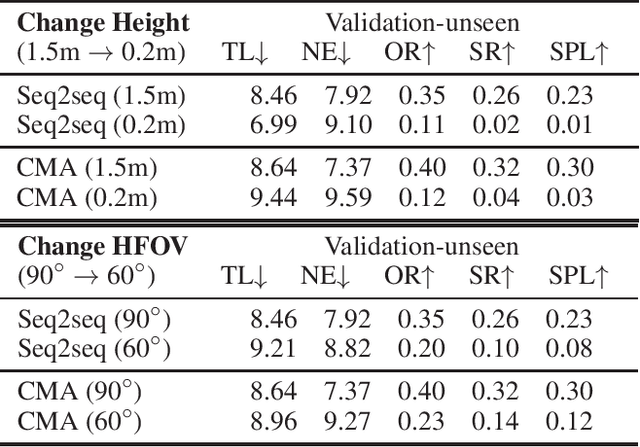
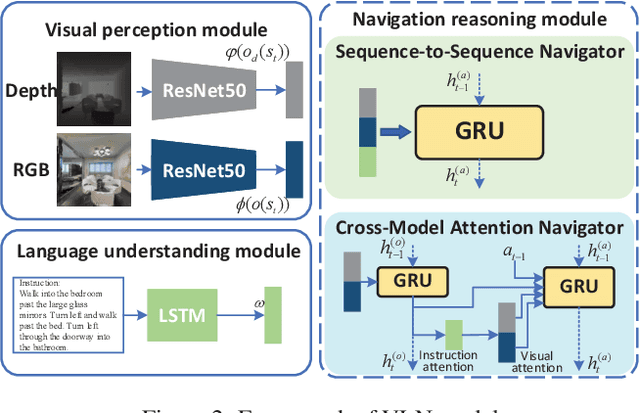
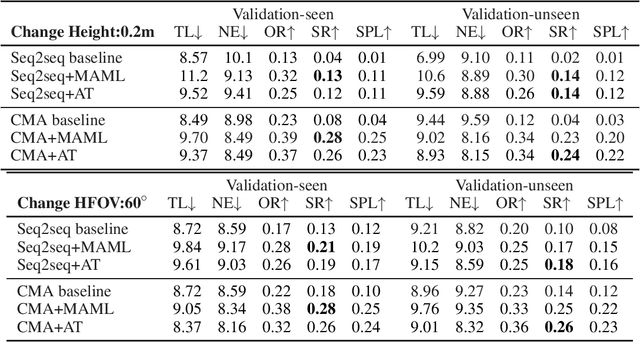
Vision-and-language navigation (VLN) is a challenging task that requires an agent to navigate in real-world environments by understanding natural language instructions and visual information received in real-time. Prior works have implemented VLN tasks on continuous environments or physical robots, all of which use a fixed camera configuration due to the limitations of datasets, such as 1.5 meters height, 90 degrees horizontal field of view (HFOV), etc. However, real-life robots with different purposes have multiple camera configurations, and the huge gap in visual information makes it difficult to directly transfer the learned navigation model between various robots. In this paper, we propose a visual perception generalization strategy based on meta-learning, which enables the agent to fast adapt to a new camera configuration with a few shots. In the training phase, we first locate the generalization problem to the visual perception module, and then compare two meta-learning algorithms for better generalization in seen and unseen environments. One of them uses the Model-Agnostic Meta-Learning (MAML) algorithm that requires a few shot adaptation, and the other refers to a metric-based meta-learning method with a feature-wise affine transformation layer. The experiment results show that our strategy successfully adapts the learned navigation model to a new camera configuration, and the two algorithms show their advantages in seen and unseen environments respectively.