 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVAction: evaluating and training multi-modal large language models for action recognition
Mar 24, 2025Understanding human behavior requires measuring behavioral actions. Due to its complexity, behavior is best mapped onto a rich, semantic structure such as language. The recent development of multi-modal large language models (MLLMs) is a promising candidate for a wide range of action understanding tasks. In this work, we focus on evaluating and then improving MLLMs to perform action recognition. We reformulate EPIC-KITCHENS-100, one of the largest and most challenging egocentric action datasets, to the form of video multiple question answering (EPIC-KITCHENS-100-MQA). We show that when we sample difficult incorrect answers as distractors, leading MLLMs struggle to recognize the correct actions. We propose a series of methods that greatly improve the MLLMs' ability to perform action recognition, achieving state-of-the-art on both the EPIC-KITCHENS-100 validation set, as well as outperforming GPT-4o by 21 points in accuracy on EPIC-KITCHENS-100-MQA. Lastly, we show improvements on other action-related video benchmarks such as EgoSchema, PerceptionTest, LongVideoBench, VideoMME and MVBench, suggesting that MLLMs are a promising path forward for complex action tasks. Code and models are available at: https://github.com/AdaptiveMotorControlLab/LLaVAction.
AmadeusGPT: a natural language interface for interactive animal behavioral analysis
Jul 10, 2023The process of quantifying and analyzing animal behavior involves translating the naturally occurring descriptive language of their actions into machine-readable code. Yet, codifying behavior analysis is often challenging without deep understanding of animal behavior and technical machine learning knowledge. To limit this gap, we introduce AmadeusGPT: a natural language interface that turns natural language descriptions of behaviors into machine-executable code. Large-language models (LLMs) such as GPT3.5 and GPT4 allow for interactive language-based queries that are potentially well suited for making interactive behavior analysis. However, the comprehension capability of these LLMs is limited by the context window size, which prevents it from remembering distant conversations. To overcome the context window limitation, we implement a novel dual-memory mechanism to allow communication between short-term and long-term memory using symbols as context pointers for retrieval and saving. Concretely, users directly use language-based definitions of behavior and our augmented GPT develops code based on the core AmadeusGPT API, which contains machine learning, computer vision, spatio-temporal reasoning, and visualization modules. Users then can interactively refine results, and seamlessly add new behavioral modules as needed. We benchmark AmadeusGPT and show we can produce state-of-the-art performance on the MABE 2022 behavior challenge tasks. Note, an end-user would not need to write any code to achieve this. Thus, collectively AmadeusGPT presents a novel way to merge deep biological knowledge, large-language models, and core computer vision modules into a more naturally intelligent system. Code and demos can be found at: https://github.com/AdaptiveMotorControlLab/AmadeusGPT.
Enhance the Visual Representation via Discrete Adversarial Training
Sep 16, 2022



Adversarial Training (AT), which is commonly accepted as one of the most effective approaches defending against adversarial examples, can largely harm the standard performance, thus has limited usefulness on industrial-scale production and applications. Surprisingly, this phenomenon is totally opposite in Natural Language Processing (NLP) task, where AT can even benefit for generalization. We notice the merit of AT in NLP tasks could derive from the discrete and symbolic input space. For borrowing the advantage from NLP-style AT, we propose Discrete Adversarial Training (DAT). DAT leverages VQGAN to reform the image data to discrete text-like inputs, i.e. visual words. Then it minimizes the maximal risk on such discrete images with symbolic adversarial perturbations. We further give an explanation from the perspective of distribution to demonstrate the effectiveness of DAT. As a plug-and-play technique for enhancing the visual representation, DAT achieves significant improvement on multiple tasks including image classification, object detection and self-supervised learning. Especially, the model pre-trained with Masked Auto-Encoding (MAE) and fine-tuned by our DAT without extra data can get 31.40 mCE on ImageNet-C and 32.77% top-1 accuracy on Stylized-ImageNet, building the new state-of-the-art. The code will be available at https://github.com/alibaba/easyrobust.
Panoptic animal pose estimators are zero-shot performers
Mar 14, 2022
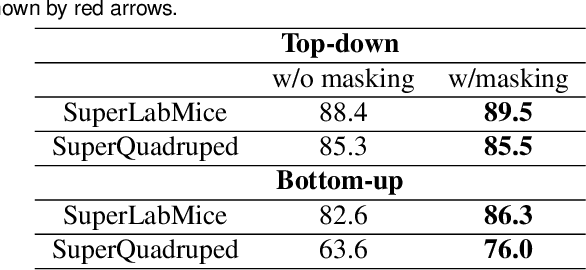
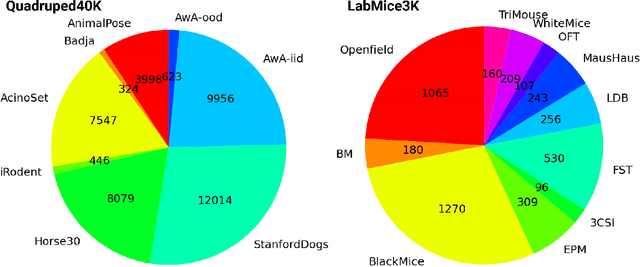
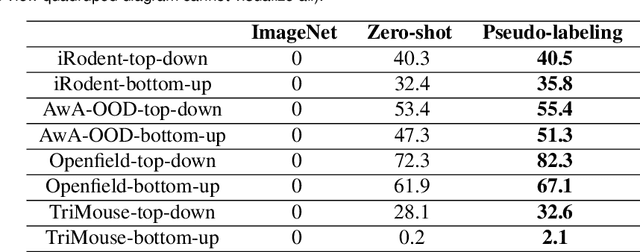
Animal pose estimation is critical in applications ranging from life science research, agriculture, to veterinary medicine. Compared to human pose estimation, the performance of animal pose estimation is limited by the size of available datasets and the generalization of a model across datasets. Typically different keypoints are labeled regardless of whether the species are the same or not, leaving animal pose datasets to have disjoint or partially overlapping keypoints. As a consequence, a model cannot be used as a plug-and-play solution across datasets. This reality motivates us to develop panoptic animal pose estimation models that are able to predict keypoints defined in all datasets. In this work we propose a simple yet effective way to merge differentially labeled datasets to obtain the largest quadruped and lab mouse pose dataset. Using a gradient masking technique, so called SuperAnimal-models are able to predict keypoints that are distributed across datasets and exhibit strong zero-shot performance. The models can be further improved by (pseudo) labeled fine-tuning. These models outperform ImageNet-initialized models.
Towards Robust Vision Transformer
May 26, 2021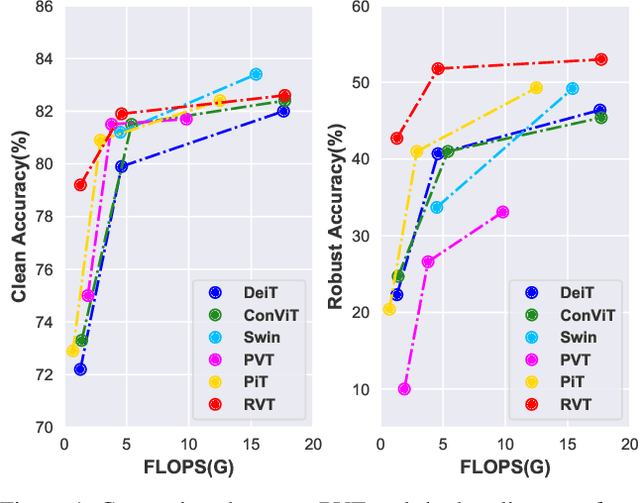
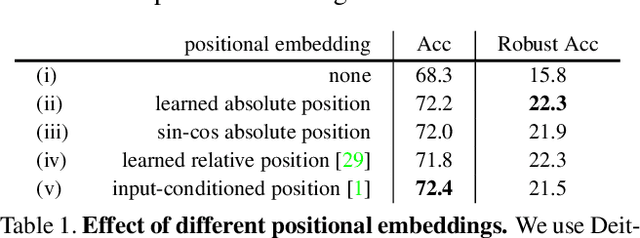
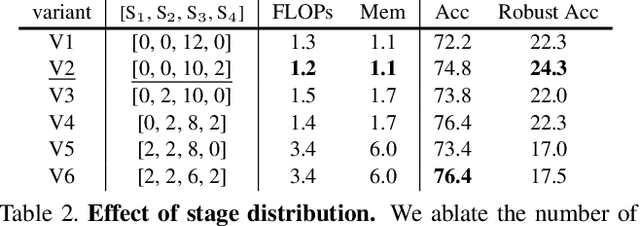
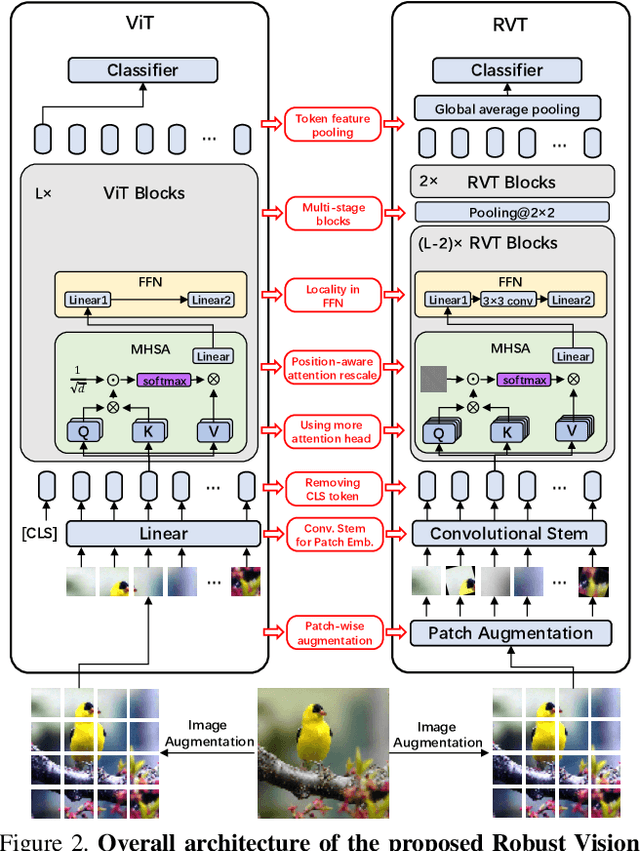
Recent advances on Vision Transformer (ViT) and its improved variants have shown that self-attention-based networks surpass traditional Convolutional Neural Networks (CNNs) in most vision tasks. However, existing ViTs focus on the standard accuracy and computation cost, lacking the investigation of the intrinsic influence on model robustness and generalization. In this work, we conduct systematic evaluation on components of ViTs in terms of their impact on robustness to adversarial examples, common corruptions and distribution shifts. We find some components can be harmful to robustness. By using and combining robust components as building blocks of ViTs, we propose Robust Vision Transformer (RVT), which is a new vision transformer and has superior performance with strong robustness. We further propose two new plug-and-play techniques called position-aware attention scaling and patch-wise augmentation to augment our RVT, which we abbreviate as RVT*. The experimental results on ImageNet and six robustness benchmarks show the advanced robustness and generalization ability of RVT compared with previous ViTs and state-of-the-art CNNs. Furthermore, RVT-S* also achieves Top-1 rank on multiple robustness leaderboards including ImageNet-C and ImageNet-Sketch. The code will be available at \url{https://git.io/Jswdk}.
QAIR: Practical Query-efficient Black-Box Attacks for Image Retrieval
Mar 23, 2021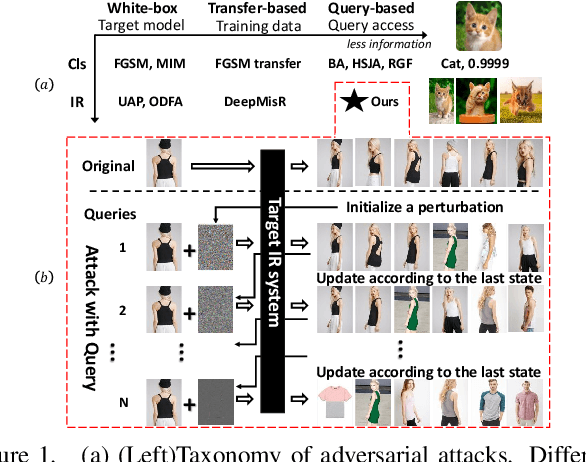
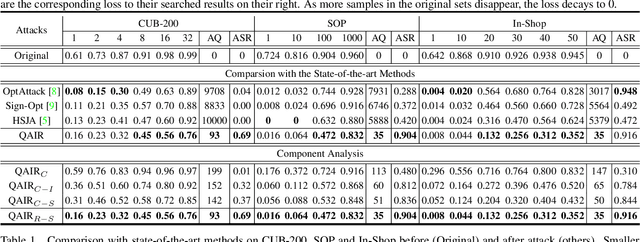
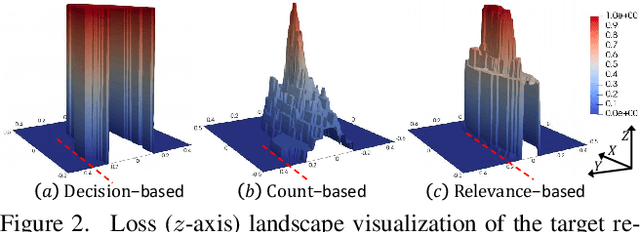
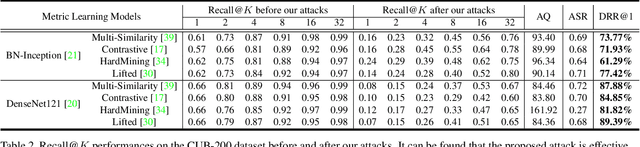
We study the query-based attack against image retrieval to evaluate its robustness against adversarial examples under the black-box setting, where the adversary only has query access to the top-k ranked unlabeled images from the database. Compared with query attacks in image classification, which produce adversaries according to the returned labels or confidence score, the challenge becomes even more prominent due to the difficulty in quantifying the attack effectiveness on the partial retrieved list. In this paper, we make the first attempt in Query-based Attack against Image Retrieval (QAIR), to completely subvert the top-k retrieval results. Specifically, a new relevance-based loss is designed to quantify the attack effects by measuring the set similarity on the top-k retrieval results before and after attacks and guide the gradient optimization. To further boost the attack efficiency, a recursive model stealing method is proposed to acquire transferable priors on the target model and generate the prior-guided gradients. Comprehensive experiments show that the proposed attack achieves a high attack success rate with few queries against the image retrieval systems under the black-box setting. The attack evaluations on the real-world visual search engine show that it successfully deceives a commercial system such as Bing Visual Search with 98% attack success rate by only 33 queries on average.
Adversarial Laser Beam: Effective Physical-World Attack to DNNs in a Blink
Mar 11, 2021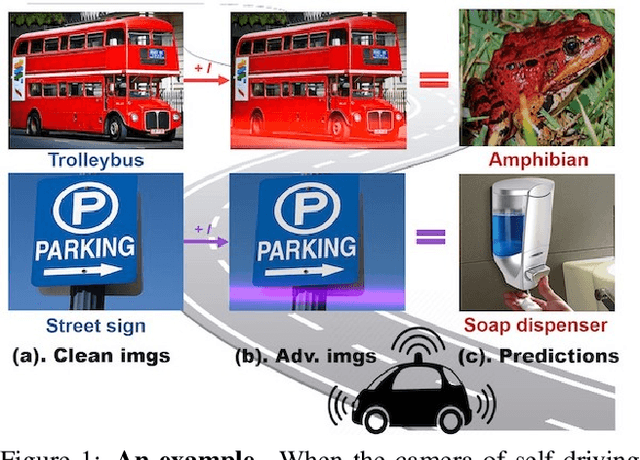

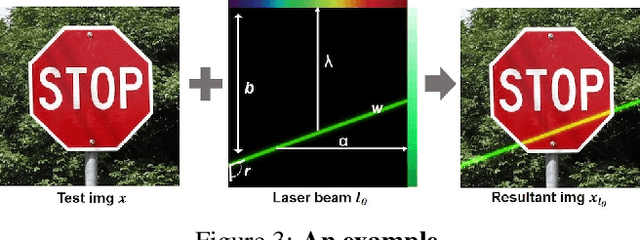
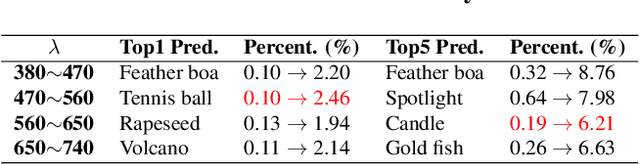
Though it is well known that the performance of deep neural networks (DNNs) degrades under certain light conditions, there exists no study on the threats of light beams emitted from some physical source as adversarial attacker on DNNs in a real-world scenario. In this work, we show by simply using a laser beam that DNNs are easily fooled. To this end, we propose a novel attack method called Adversarial Laser Beam ($AdvLB$), which enables manipulation of laser beam's physical parameters to perform adversarial attack. Experiments demonstrate the effectiveness of our proposed approach in both digital- and physical-settings. We further empirically analyze the evaluation results and reveal that the proposed laser beam attack may lead to some interesting prediction errors of the state-of-the-art DNNs. We envisage that the proposed $AdvLB$ method enriches the current family of adversarial attacks and builds the foundation for future robustness studies for light.
PCNN: Pattern-based Fine-Grained Regular Pruning towards Optimizing CNN Accelerators
Feb 11, 2020
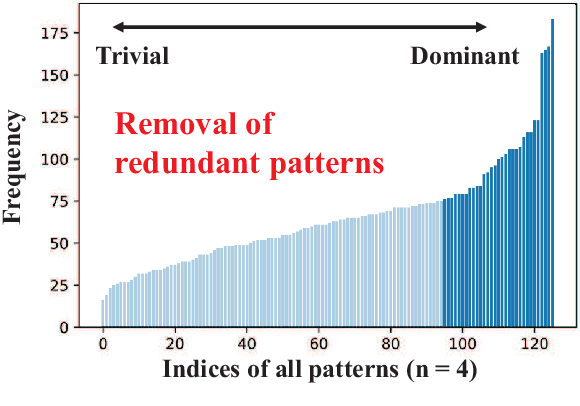
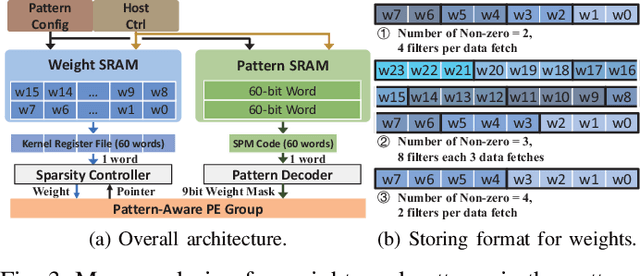
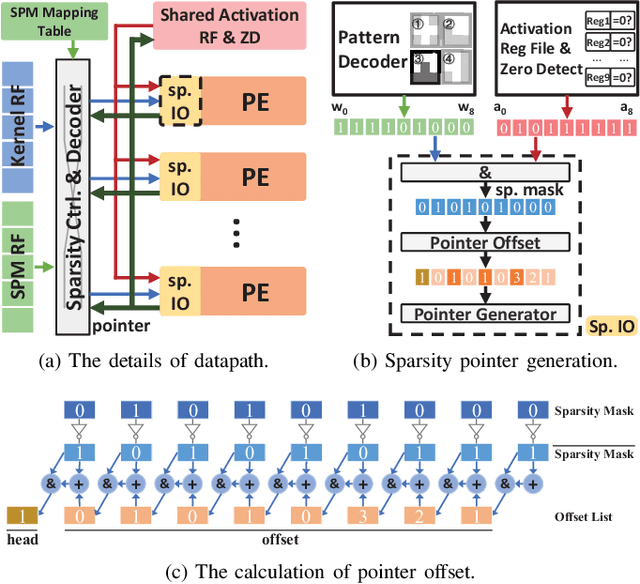
Weight pruning is a powerful technique to realize model compression. We propose PCNN, a fine-grained regular 1D pruning method. A novel index format called Sparsity Pattern Mask (SPM) is presented to encode the sparsity in PCNN. Leveraging SPM with limited pruning patterns and non-zero sequences with equal length, PCNN can be efficiently employed in hardware. Evaluated on VGG-16 and ResNet-18, our PCNN achieves the compression rate up to 8.4X with only 0.2% accuracy loss. We also implement a pattern-aware architecture in 55nm process, achieving up to 9.0X speedup and 28.39 TOPS/W efficiency with only 3.1% on-chip memory overhead of indices.
Light-weight Calibrator: a Separable Component for Unsupervised Domain Adaptation
Nov 28, 2019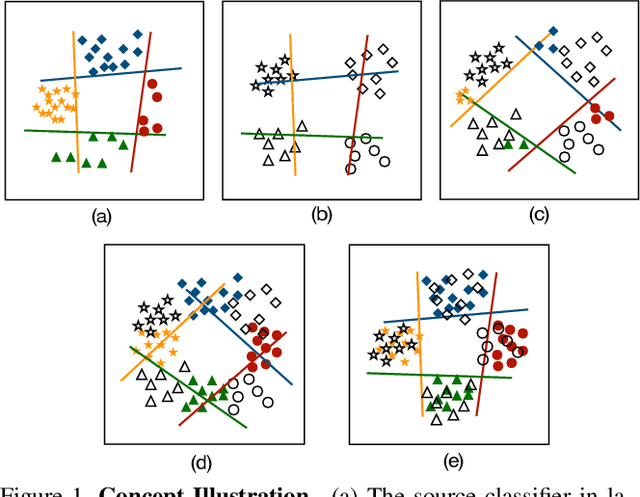
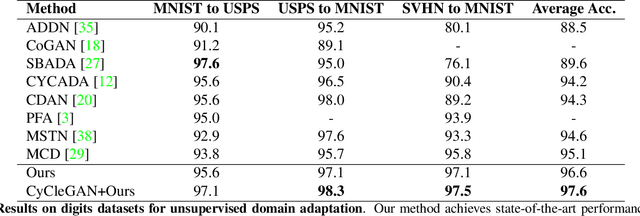
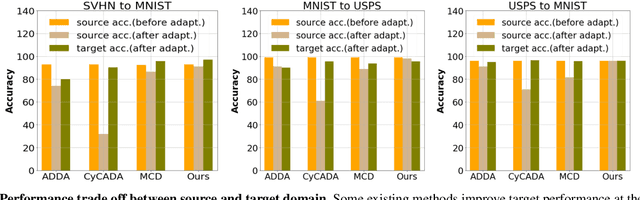

Existing domain adaptation methods aim at learning features that can be generalized among domains. These methods commonly require to update source classifier to adapt to the target domain and do not properly handle the trade off between the source domain and the target domain. In this work, instead of training a classifier to adapt to the target domain, we use a separable component called data calibrator to help the fixed source classifier recover discrimination power in the target domain, while preserving the source domain's performance. When the difference between two domains is small, the source classifier's representation is sufficient to perform well in the target domain and outperforms GAN-based methods in digits. Otherwise, the proposed method can leverage synthetic images generated by GANs to boost performance and achieve state-of-the-art performance in digits datasets and driving scene semantic segmentation. Our method empirically reveals that certain intriguing hints, which can be mitigated by adversarial attack to domain discriminators, are one of the sources for performance degradation under the domain shift. Code release is at https://github.com/yeshaokai/Calibrator-Domain-Adaptation.
Non-structured DNN Weight Pruning Considered Harmful
Jul 03, 2019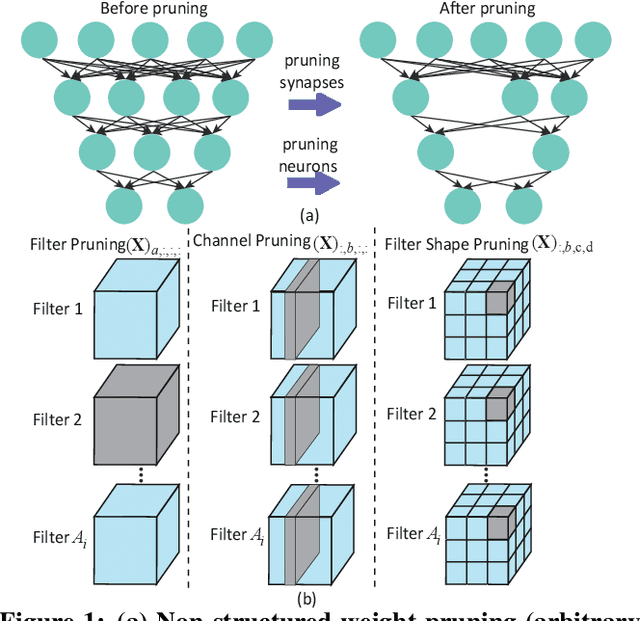
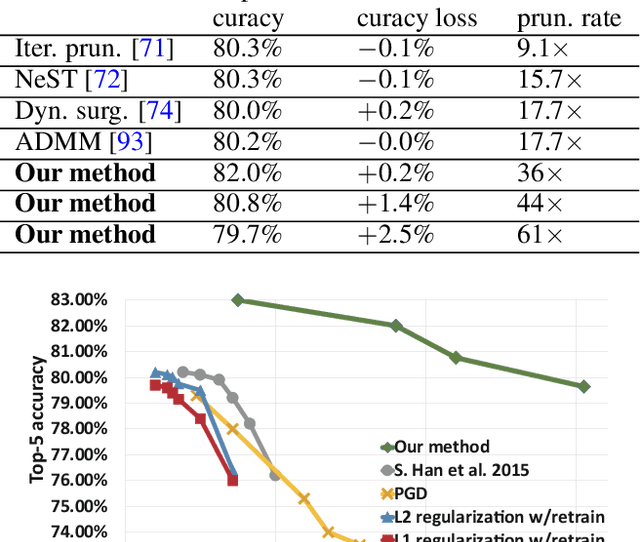
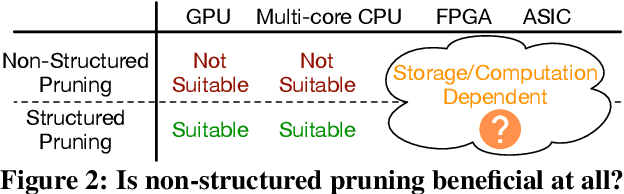
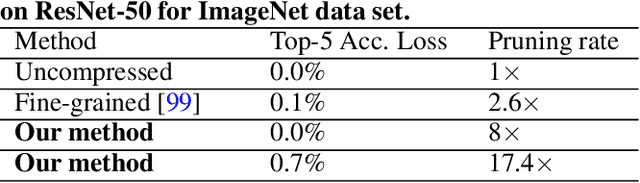
Large deep neural network (DNN) models pose the key challenge to energy efficiency due to the significantly higher energy consumption of off-chip DRAM accesses than arithmetic or SRAM operations. It motivates the intensive research on model compression with two main approaches. Weight pruning leverages the redundancy in the number of weights and can be performed in a non-structured, which has higher flexibility and pruning rate but incurs index accesses due to irregular weights, or structured manner, which preserves the full matrix structure with lower pruning rate. Weight quantization leverages the redundancy in the number of bits in weights. Compared to pruning, quantization is much more hardware-friendly, and has become a "must-do" step for FPGA and ASIC implementations. This paper provides a definitive answer to the question for the first time. First, we build ADMM-NN-S by extending and enhancing ADMM-NN, a recently proposed joint weight pruning and quantization framework. Second, we develop a methodology for fair and fundamental comparison of non-structured and structured pruning in terms of both storage and computation efficiency. Our results show that ADMM-NN-S consistently outperforms the prior art: (i) it achieves 348x, 36x, and 8x overall weight pruning on LeNet-5, AlexNet, and ResNet-50, respectively, with (almost) zero accuracy loss; (ii) we demonstrate the first fully binarized (for all layers) DNNs can be lossless in accuracy in many cases. These results provide a strong baseline and credibility of our study. Based on the proposed comparison framework, with the same accuracy and quantization, the results show that non-structrued pruning is not competitive in terms of both storage and computation efficiency. Thus, we conclude that non-structured pruning is considered harmful. We urge the community not to continue the DNN inference acceleration for non-structured sparsity.