 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptToken: Entropy-based Adaptive Token Selection for MLLM Long Video Understanding
Mar 30, 2026Long video understanding remains challenging for Multi-modal Large Language Models (MLLMs) due to high memory costs and context-length limits. Prior approaches mitigate this by scoring and selecting frames/tokens within short clips, but they lack a principled mechanism to (i) compare relevance across distant video clips and (ii) stop processing once sufficient evidence has been gathered. We propose AdaptToken, a training-free framework that turns an MLLM's self-uncertainty into a global control signal for long-video token selection. AdaptToken splits a video into groups, extracts cross-modal attention to rank tokens within each group, and uses the model's response entropy to estimate each group's prompt relevance. This entropy signal enables a global token budget allocation across groups and further supports early stopping (AdaptToken-Lite), skipping the remaining groups when the model becomes sufficiently certain. Across four long-video benchmarks (VideoMME, LongVideoBench, LVBench, and MLVU) and multiple base MLLMs (7B-72B), AdaptToken consistently improves accuracy (e.g., +6.7 on average over Qwen2.5-VL 7B) and continues to benefit from extremely long inputs (up to 10K frames), while AdaptToken-Lite reduces inference time by about half with comparable performance. Project page: https://haozheqi.github.io/adapt-token
Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models
Mar 18, 2026Multimodal Large Language Models (MLLMs) have made impressive progress in connecting vision and language, but they still struggle with spatial understanding and viewpoint-aware reasoning. Recent efforts aim to augment the input representations with geometric cues rather than explicitly teaching models to reason in 3D space. We introduce Loc3R-VLM, a framework that equips 2D Vision-Language Models with advanced 3D understanding capabilities from monocular video input. Inspired by human spatial cognition, Loc3R-VLM relies on two joint objectives: global layout reconstruction to build a holistic representation of the scene structure, and explicit situation modeling to anchor egocentric perspective. These objectives provide direct spatial supervision that grounds both perception and language in a 3D context. To ensure geometric consistency and metric-scale alignment, we leverage lightweight camera pose priors extracted from a pre-trained 3D foundation model. Loc3R-VLM achieves state-of-the-art performance in language-based localization and outperforms existing 2D- and video-based approaches on situated and general 3D question-answering benchmarks, demonstrating that our spatial supervision framework enables strong 3D understanding. Project page: https://kevinqu7.github.io/loc3r-vlm
LLaVAction: evaluating and training multi-modal large language models for action recognition
Mar 24, 2025Understanding human behavior requires measuring behavioral actions. Due to its complexity, behavior is best mapped onto a rich, semantic structure such as language. The recent development of multi-modal large language models (MLLMs) is a promising candidate for a wide range of action understanding tasks. In this work, we focus on evaluating and then improving MLLMs to perform action recognition. We reformulate EPIC-KITCHENS-100, one of the largest and most challenging egocentric action datasets, to the form of video multiple question answering (EPIC-KITCHENS-100-MQA). We show that when we sample difficult incorrect answers as distractors, leading MLLMs struggle to recognize the correct actions. We propose a series of methods that greatly improve the MLLMs' ability to perform action recognition, achieving state-of-the-art on both the EPIC-KITCHENS-100 validation set, as well as outperforming GPT-4o by 21 points in accuracy on EPIC-KITCHENS-100-MQA. Lastly, we show improvements on other action-related video benchmarks such as EgoSchema, PerceptionTest, LongVideoBench, VideoMME and MVBench, suggesting that MLLMs are a promising path forward for complex action tasks. Code and models are available at: https://github.com/AdaptiveMotorControlLab/LLaVAction.
HOISDF: Constraining 3D Hand-Object Pose Estimation with Global Signed Distance Fields
Feb 26, 2024



Human hands are highly articulated and versatile at handling objects. Jointly estimating the 3D poses of a hand and the object it manipulates from a monocular camera is challenging due to frequent occlusions. Thus, existing methods often rely on intermediate 3D shape representations to increase performance. These representations are typically explicit, such as 3D point clouds or meshes, and thus provide information in the direct surroundings of the intermediate hand pose estimate. To address this, we introduce HOISDF, a Signed Distance Field (SDF) guided hand-object pose estimation network, which jointly exploits hand and object SDFs to provide a global, implicit representation over the complete reconstruction volume. Specifically, the role of the SDFs is threefold: equip the visual encoder with implicit shape information, help to encode hand-object interactions, and guide the hand and object pose regression via SDF-based sampling and by augmenting the feature representations. We show that HOISDF achieves state-of-the-art results on hand-object pose estimation benchmarks (DexYCB and HO3Dv2). Code is available at https://github.com/amathislab/HOISDF
P2B: Point-to-Box Network for 3D Object Tracking in Point Clouds
May 28, 2020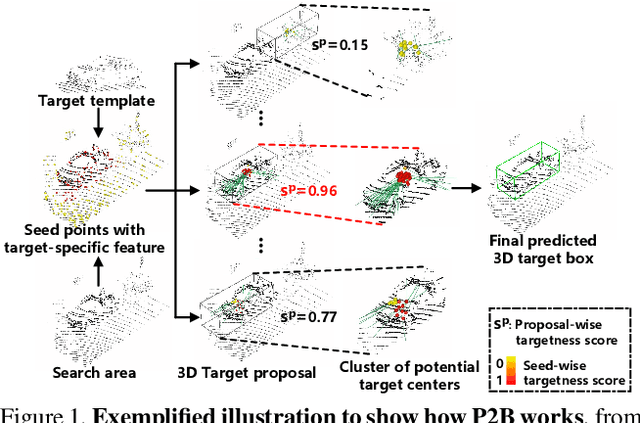

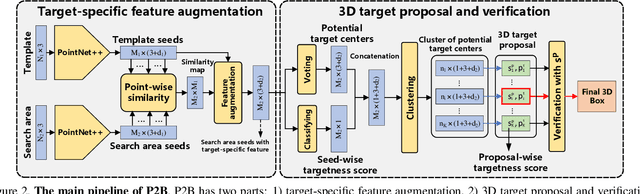
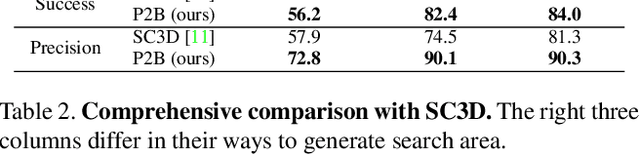
Towards 3D object tracking in point clouds, a novel point-to-box network termed P2B is proposed in an end-to-end learning manner. Our main idea is to first localize potential target centers in 3D search area embedded with target information. Then point-driven 3D target proposal and verification are executed jointly. In this way, the time-consuming 3D exhaustive search can be avoided. Specifically, we first sample seeds from the point clouds in template and search area respectively. Then, we execute permutation-invariant feature augmentation to embed target clues from template into search area seeds and represent them with target-specific features. Consequently, the augmented search area seeds regress the potential target centers via Hough voting. The centers are further strengthened with seed-wise targetness scores. Finally, each center clusters its neighbors to leverage the ensemble power for joint 3D target proposal and verification. We apply PointNet++ as our backbone and experiments on KITTI tracking dataset demonstrate P2B's superiority (~10%'s improvement over state-of-the-art). Note that P2B can run with 40FPS on a single NVIDIA 1080Ti GPU. Our code and model are available at https://github.com/HaozheQi/P2B.