 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Newtons: Predicting In Vivo Joint Contact Forces from Monocular Video
Jun 04, 2026Joint contact forces govern implant longevity, cartilage health, and rehabilitation outcomes, shaping who develops osteoarthritis, who recovers well from joint replacement, and who benefits from biomechanical interventions. Yet they remain measurable only invasively, in a few dozen patients with instrumented implants. I present a physics-free pipeline to predict instantaneous 3D hip and knee contact forces from an uncalibrated monocular video: no markers, force plates, electromyography, subject-specific imaging, or musculoskeletal model. Parametric body meshes are recovered per frame, encoded as kinematic features, and decoded into forces by a transformer whose pose stream is adaptively modulated at every layer by body shape, joint, side, activity text, and self-supervised video tokens (V-JEPA 2), unifying hip and knee in a single model. Under leave-one-subject-out cross-validation across 26 patients and 25 activity categories from the in vivo OrthoLoad database, the pipeline matches the accuracy of subject-specific musculoskeletal simulations ($0.32 \pm 0.08$ BW RMSE for hip; $0.23 \pm 0.03$ BW for knee) and resolves peak force changes smaller than those reported for gait retraining and osteoarthritis progression. Applied zero-shot to an independent instrumented cohort, it rivals or outperforms prior published methods. Even without curated activity labels, video features alone preserve accuracy and enable end-to-end inference on raw footage. Driven by the predictor, a generative motion prior produces biomechanically plausible variants with reduced peak loading, rediscovering strategies from the predictive simulation literature. This pipeline establishes uncalibrated monocular video as a viable modality for estimating joint loading, opening a path toward retrospective analysis of archived clinical recordings, primary-care screening, and at-home rehabilitation tracking.
AmadeusGPT: a natural language interface for interactive animal behavioral analysis
Jul 10, 2023The process of quantifying and analyzing animal behavior involves translating the naturally occurring descriptive language of their actions into machine-readable code. Yet, codifying behavior analysis is often challenging without deep understanding of animal behavior and technical machine learning knowledge. To limit this gap, we introduce AmadeusGPT: a natural language interface that turns natural language descriptions of behaviors into machine-executable code. Large-language models (LLMs) such as GPT3.5 and GPT4 allow for interactive language-based queries that are potentially well suited for making interactive behavior analysis. However, the comprehension capability of these LLMs is limited by the context window size, which prevents it from remembering distant conversations. To overcome the context window limitation, we implement a novel dual-memory mechanism to allow communication between short-term and long-term memory using symbols as context pointers for retrieval and saving. Concretely, users directly use language-based definitions of behavior and our augmented GPT develops code based on the core AmadeusGPT API, which contains machine learning, computer vision, spatio-temporal reasoning, and visualization modules. Users then can interactively refine results, and seamlessly add new behavioral modules as needed. We benchmark AmadeusGPT and show we can produce state-of-the-art performance on the MABE 2022 behavior challenge tasks. Note, an end-user would not need to write any code to achieve this. Thus, collectively AmadeusGPT presents a novel way to merge deep biological knowledge, large-language models, and core computer vision modules into a more naturally intelligent system. Code and demos can be found at: https://github.com/AdaptiveMotorControlLab/AmadeusGPT.
A Primer on Motion Capture with Deep Learning: Principles, Pitfalls and Perspectives
Sep 02, 2020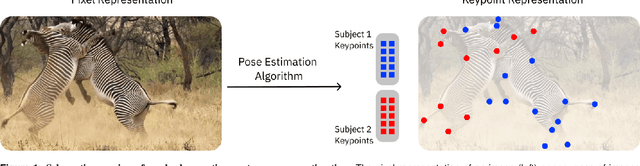
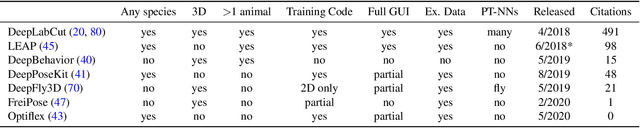
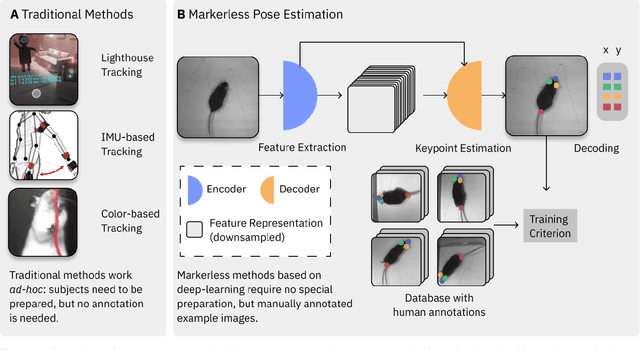

Extracting behavioral measurements non-invasively from video is stymied by the fact that it is a hard computational problem. Recent advances in deep learning have tremendously advanced predicting posture from videos directly, which quickly impacted neuroscience and biology more broadly. In this primer we review the budding field of motion capture with deep learning. In particular, we will discuss the principles of those novel algorithms, highlight their potential as well as pitfalls for experimentalists, and provide a glimpse into the future.