 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating LLM-Based Evaluator
Sep 23, 2023Recent advancements in large language models (LLMs) on language modeling and emergent capabilities make them a promising reference-free evaluator of natural language generation quality, and a competent alternative to human evaluation. However, hindered by the closed-source or high computational demand to host and tune, there is a lack of practice to further calibrate an off-the-shelf LLM-based evaluator towards better human alignment. In this work, we propose AutoCalibrate, a multi-stage, gradient-free approach to automatically calibrate and align an LLM-based evaluator toward human preference. Instead of explicitly modeling human preferences, we first implicitly encompass them within a set of human labels. Then, an initial set of scoring criteria is drafted by the language model itself, leveraging in-context learning on different few-shot examples. To further calibrate this set of criteria, we select the best performers and re-draft them with self-refinement. Our experiments on multiple text quality evaluation datasets illustrate a significant improvement in correlation with expert evaluation through calibration. Our comprehensive qualitative analysis conveys insightful intuitions and observations on the essence of effective scoring criteria.
Kosmos-2.5: A Multimodal Literate Model
Sep 20, 2023



We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
Adapting Large Language Models via Reading Comprehension
Sep 18, 2023



We explore how continued pre-training on domain-specific corpora influences large language models, revealing that training on the raw corpora endows the model with domain knowledge, but drastically hurts its prompting ability for question answering. Taken inspiration from human learning via reading comprehension--practice after reading improves the ability to answer questions based on the learned knowledge--we propose a simple method for transforming raw corpora into reading comprehension texts. Each raw text is enriched with a series of tasks related to its content. Our method, highly scalable and applicable to any pre-training corpora, consistently enhances performance across various tasks in three different domains: biomedicine, finance, and law. Notably, our 7B language model achieves competitive performance with domain-specific models of much larger scales, such as BloombergGPT-50B. Furthermore, we demonstrate that domain-specific reading comprehension texts can improve the model's performance even on general benchmarks, showing the potential to develop a general model across even more domains. Our model, code, and data will be available at https://github.com/microsoft/LMOps.
LogGPT: Exploring ChatGPT for Log-Based Anomaly Detection
Sep 03, 2023



The increasing volume of log data produced by software-intensive systems makes it impractical to analyze them manually. Many deep learning-based methods have been proposed for log-based anomaly detection. These methods face several challenges such as high-dimensional and noisy log data, class imbalance, generalization, and model interpretability. Recently, ChatGPT has shown promising results in various domains. However, there is still a lack of study on the application of ChatGPT for log-based anomaly detection. In this work, we proposed LogGPT, a log-based anomaly detection framework based on ChatGPT. By leveraging the ChatGPT's language interpretation capabilities, LogGPT aims to explore the transferability of knowledge from large-scale corpora to log-based anomaly detection. We conduct experiments to evaluate the performance of LogGPT and compare it with three deep learning-based methods on BGL and Spirit datasets. LogGPT shows promising results and has good interpretability. This study provides preliminary insights into prompt-based models, such as ChatGPT, for the log-based anomaly detection task.
Retentive Network: A Successor to Transformer for Large Language Models
Aug 09, 2023In this work, we propose Retentive Network (RetNet) as a foundation architecture for large language models, simultaneously achieving training parallelism, low-cost inference, and good performance. We theoretically derive the connection between recurrence and attention. Then we propose the retention mechanism for sequence modeling, which supports three computation paradigms, i.e., parallel, recurrent, and chunkwise recurrent. Specifically, the parallel representation allows for training parallelism. The recurrent representation enables low-cost $O(1)$ inference, which improves decoding throughput, latency, and GPU memory without sacrificing performance. The chunkwise recurrent representation facilitates efficient long-sequence modeling with linear complexity, where each chunk is encoded parallelly while recurrently summarizing the chunks. Experimental results on language modeling show that RetNet achieves favorable scaling results, parallel training, low-cost deployment, and efficient inference. The intriguing properties make RetNet a strong successor to Transformer for large language models. Code will be available at https://aka.ms/retnet.
Scaling Sentence Embeddings with Large Language Models
Jul 31, 2023



Large language models (LLMs) have recently garnered significant interest. With in-context learning, LLMs achieve impressive results in various natural language tasks. However, the application of LLMs to sentence embeddings remains an area of ongoing research. In this work, we propose an in-context learning-based method aimed at improving sentence embeddings performance. Our approach involves adapting the previous prompt-based representation method for autoregressive models, constructing a demonstration set that enables LLMs to perform in-context learning, and scaling up the LLMs to different model sizes. Through extensive experiments, in-context learning enables LLMs to generate high-quality sentence embeddings without any fine-tuning. It helps LLMs achieve performance comparable to current contrastive learning methods. By scaling model size, we find scaling to more than tens of billion parameters harms the performance on semantic textual similarity (STS) tasks. However, the largest model outperforms other counterparts and achieves the new state-of-the-art result on transfer tasks. We also fine-tune LLMs with current contrastive learning approach, and the 2.7B OPT model, incorporating our prompt-based method, surpasses the performance of 4.8B ST5, achieving the new state-of-the-art results on STS tasks. Our code is available at https://github.com/kongds/scaling_sentemb.
LongNet: Scaling Transformers to 1,000,000,000 Tokens
Jul 19, 2023Scaling sequence length has become a critical demand in the era of large language models. However, existing methods struggle with either computational complexity or model expressivity, rendering the maximum sequence length restricted. To address this issue, we introduce LongNet, a Transformer variant that can scale sequence length to more than 1 billion tokens, without sacrificing the performance on shorter sequences. Specifically, we propose dilated attention, which expands the attentive field exponentially as the distance grows. LongNet has significant advantages: 1) it has a linear computation complexity and a logarithm dependency between any two tokens in a sequence; 2) it can be served as a distributed trainer for extremely long sequences; 3) its dilated attention is a drop-in replacement for standard attention, which can be seamlessly integrated with the existing Transformer-based optimization. Experiments results demonstrate that LongNet yields strong performance on both long-sequence modeling and general language tasks. Our work opens up new possibilities for modeling very long sequences, e.g., treating a whole corpus or even the entire Internet as a sequence.
Kosmos-2: Grounding Multimodal Large Language Models to the World
Jul 13, 2023
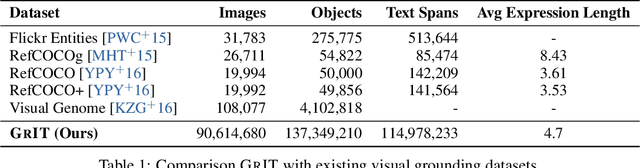

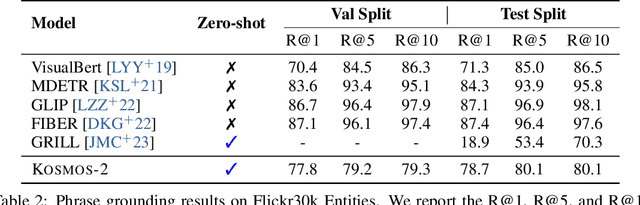
We introduce Kosmos-2, a Multimodal Large Language Model (MLLM), enabling new capabilities of perceiving object descriptions (e.g., bounding boxes) and grounding text to the visual world. Specifically, we represent refer expressions as links in Markdown, i.e., ``[text span](bounding boxes)'', where object descriptions are sequences of location tokens. Together with multimodal corpora, we construct large-scale data of grounded image-text pairs (called GrIT) to train the model. In addition to the existing capabilities of MLLMs (e.g., perceiving general modalities, following instructions, and performing in-context learning), Kosmos-2 integrates the grounding capability into downstream applications. We evaluate Kosmos-2 on a wide range of tasks, including (i) multimodal grounding, such as referring expression comprehension, and phrase grounding, (ii) multimodal referring, such as referring expression generation, (iii) perception-language tasks, and (iv) language understanding and generation. This work lays out the foundation for the development of Embodiment AI and sheds light on the big convergence of language, multimodal perception, action, and world modeling, which is a key step toward artificial general intelligence. Code and pretrained models are available at https://aka.ms/kosmos-2.
Learning Music Sequence Representation from Text Supervision
May 31, 2023Music representation learning is notoriously difficult for its complex human-related concepts contained in the sequence of numerical signals. To excavate better MUsic SEquence Representation from labeled audio, we propose a novel text-supervision pre-training method, namely MUSER. MUSER adopts an audio-spectrum-text tri-modal contrastive learning framework, where the text input could be any form of meta-data with the help of text templates while the spectrum is derived from an audio sequence. Our experiments reveal that MUSER could be more flexibly adapted to downstream tasks compared with the current data-hungry pre-training method, and it only requires 0.056% of pre-training data to achieve the state-of-the-art performance.
Dual-Alignment Pre-training for Cross-lingual Sentence Embedding
May 16, 2023



Recent studies have shown that dual encoder models trained with the sentence-level translation ranking task are effective methods for cross-lingual sentence embedding. However, our research indicates that token-level alignment is also crucial in multilingual scenarios, which has not been fully explored previously. Based on our findings, we propose a dual-alignment pre-training (DAP) framework for cross-lingual sentence embedding that incorporates both sentence-level and token-level alignment. To achieve this, we introduce a novel representation translation learning (RTL) task, where the model learns to use one-side contextualized token representation to reconstruct its translation counterpart. This reconstruction objective encourages the model to embed translation information into the token representation. Compared to other token-level alignment methods such as translation language modeling, RTL is more suitable for dual encoder architectures and is computationally efficient. Extensive experiments on three sentence-level cross-lingual benchmarks demonstrate that our approach can significantly improve sentence embedding. Our code is available at https://github.com/ChillingDream/DAP.