 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumber Representations in LLMs: A Computational Parallel to Human Perception
Feb 22, 2025Humans are believed to perceive numbers on a logarithmic mental number line, where smaller values are represented with greater resolution than larger ones. This cognitive bias, supported by neuroscience and behavioral studies, suggests that numerical magnitudes are processed in a sublinear fashion rather than on a uniform linear scale. Inspired by this hypothesis, we investigate whether large language models (LLMs) exhibit a similar logarithmic-like structure in their internal numerical representations. By analyzing how numerical values are encoded across different layers of LLMs, we apply dimensionality reduction techniques such as PCA and PLS followed by geometric regression to uncover latent structures in the learned embeddings. Our findings reveal that the model's numerical representations exhibit sublinear spacing, with distances between values aligning with a logarithmic scale. This suggests that LLMs, much like humans, may encode numbers in a compressed, non-uniform manner.
The Geometry of Numerical Reasoning: Language Models Compare Numeric Properties in Linear Subspaces
Oct 17, 2024This paper investigates whether large language models (LLMs) utilize numerical attributes encoded in a low-dimensional subspace of the embedding space when answering logical comparison questions (e.g., Was Cristiano born before Messi?). We first identified these subspaces using partial least squares regression, which effectively encodes the numerical attributes associated with the entities in comparison prompts. Further, we demonstrate causality by intervening in these subspaces to manipulate hidden states, thereby altering the LLM's comparison outcomes. Experimental results show that our findings hold for different numerical attributes, indicating that LLMs utilize the linearly encoded information for numerical reasoning.
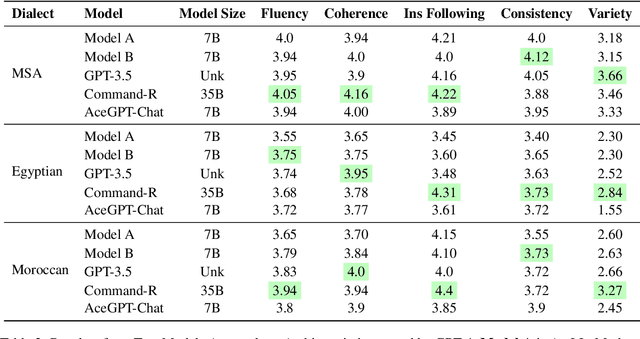
Casablanca: Data and Models for Multidialectal Arabic Speech Recognition
Oct 06, 2024



In spite of the recent progress in speech processing, the majority of world languages and dialects remain uncovered. This situation only furthers an already wide technological divide, thereby hindering technological and socioeconomic inclusion. This challenge is largely due to the absence of datasets that can empower diverse speech systems. In this paper, we seek to mitigate this obstacle for a number of Arabic dialects by presenting Casablanca, a large-scale community-driven effort to collect and transcribe a multi-dialectal Arabic dataset. The dataset covers eight dialects: Algerian, Egyptian, Emirati, Jordanian, Mauritanian, Moroccan, Palestinian, and Yemeni, and includes annotations for transcription, gender, dialect, and code-switching. We also develop a number of strong baselines exploiting Casablanca. The project page for Casablanca is accessible at: www.dlnlp.ai/speech/casablanca.
Arabic Automatic Story Generation with Large Language Models
Jul 10, 2024


Large language models (LLMs) have recently emerged as a powerful tool for a wide range of language generation tasks. Nevertheless, this progress has been slower in Arabic. In this work, we focus on the task of generating stories from LLMs. For our training, we use stories acquired through machine translation (MT) as well as GPT-4. For the MT data, we develop a careful pipeline that ensures we acquire high-quality stories. For our GPT-41 data, we introduce crafted prompts that allow us to generate data well-suited to the Arabic context in both Modern Standard Arabic (MSA) and two Arabic dialects (Egyptian and Moroccan). For example, we generate stories tailored to various Arab countries on a wide host of topics. Our manual evaluation shows that our model fine-tuned on these training datasets can generate coherent stories that adhere to our instructions. We also conduct an extensive automatic and human evaluation comparing our models against state-of-the-art proprietary and open-source models. Our datasets and models will be made publicly available at https: //github.com/UBC-NLP/arastories.
Arabic Fine-Grained Entity Recognition
Oct 26, 2023



Traditional NER systems are typically trained to recognize coarse-grained entities, and less attention is given to classifying entities into a hierarchy of fine-grained lower-level subtypes. This article aims to advance Arabic NER with fine-grained entities. We chose to extend Wojood (an open-source Nested Arabic Named Entity Corpus) with subtypes. In particular, four main entity types in Wojood, geopolitical entity (GPE), location (LOC), organization (ORG), and facility (FAC), are extended with 31 subtypes. To do this, we first revised Wojood's annotations of GPE, LOC, ORG, and FAC to be compatible with the LDC's ACE guidelines, which yielded 5, 614 changes. Second, all mentions of GPE, LOC, ORG, and FAC (~44K) in Wojood are manually annotated with the LDC's ACE sub-types. We refer to this extended version of Wojood as WojoodF ine. To evaluate our annotations, we measured the inter-annotator agreement (IAA) using both Cohen's Kappa and F1 score, resulting in 0.9861 and 0.9889, respectively. To compute the baselines of WojoodF ine, we fine-tune three pre-trained Arabic BERT encoders in three settings: flat NER, nested NER and nested NER with subtypes and achieved F1 score of 0.920, 0.866, and 0.885, respectively. Our corpus and models are open-source and available at https://sina.birzeit.edu/wojood/.
TARJAMAT: Evaluation of Bard and ChatGPT on Machine Translation of Ten Arabic Varieties
Aug 06, 2023



Large language models (LLMs) finetuned to follow human instructions have recently emerged as a breakthrough in AI. Models such as Google Bard and OpenAI ChatGPT, for example, are surprisingly powerful tools for question answering, code debugging, and dialogue generation. Despite the purported multilingual proficiency of these models, their linguistic inclusivity remains insufficiently explored. Considering this constraint, we present a thorough assessment of Bard and ChatGPT (encompassing both GPT-3.5 and GPT-4) regarding their machine translation proficiencies across ten varieties of Arabic. Our evaluation covers diverse Arabic varieties such as Classical Arabic, Modern Standard Arabic, and several nuanced dialectal variants. Furthermore, we undertake a human-centric study to scrutinize the efficacy of the most recent model, Bard, in following human instructions during translation tasks. Our exhaustive analysis indicates that LLMs may encounter challenges with certain Arabic dialects, particularly those for which minimal public data exists, such as Algerian and Mauritanian dialects. However, they exhibit satisfactory performance with more prevalent dialects, albeit occasionally trailing behind established commercial systems like Google Translate. Additionally, our analysis reveals a circumscribed capability of Bard in aligning with human instructions in translation contexts. Collectively, our findings underscore that prevailing LLMs remain far from inclusive, with only limited ability to cater for the linguistic and cultural intricacies of diverse communities.
QCRI at SemEval-2023 Task 3: News Genre, Framing and Persuasion Techniques Detection using Multilingual Models
May 05, 2023Misinformation spreading in mainstream and social media has been misleading users in different ways. Manual detection and verification efforts by journalists and fact-checkers can no longer cope with the great scale and quick spread of misleading information. This motivated research and industry efforts to develop systems for analyzing and verifying news spreading online. The SemEval-2023 Task 3 is an attempt to address several subtasks under this overarching problem, targeting writing techniques used in news articles to affect readers' opinions. The task addressed three subtasks with six languages, in addition to three ``surprise'' test languages, resulting in 27 different test setups. This paper describes our participating system to this task. Our team is one of the 6 teams that successfully submitted runs for all setups. The official results show that our system is ranked among the top 3 systems for 10 out of the 27 setups.