 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexandria: A Multi-Domain Dialectal Arabic Machine Translation Dataset for Culturally Inclusive and Linguistically Diverse LLMs
Jan 19, 2026Arabic is a highly diglossic language where most daily communication occurs in regional dialects rather than Modern Standard Arabic. Despite this, machine translation (MT) systems often generalize poorly to dialectal input, limiting their utility for millions of speakers. We introduce \textbf{Alexandria}, a large-scale, community-driven, human-translated dataset designed to bridge this gap. Alexandria covers 13 Arab countries and 11 high-impact domains, including health, education, and agriculture. Unlike previous resources, Alexandria provides unprecedented granularity by associating contributions with city-of-origin metadata, capturing authentic local varieties beyond coarse regional labels. The dataset consists of multi-turn conversational scenarios annotated with speaker-addressee gender configurations, enabling the study of gender-conditioned variation in dialectal use. Comprising 107K total samples, Alexandria serves as both a training resource and a rigorous benchmark for evaluating MT and Large Language Models (LLMs). Our automatic and human evaluation of Arabic-aware LLMs benchmarks current capabilities in translating across diverse Arabic dialects and sub-dialects, while exposing significant persistent challenges.
Bridging ASR and LLMs for Dysarthric Speech Recognition: Benchmarking Self-Supervised and Generative Approaches
Aug 11, 2025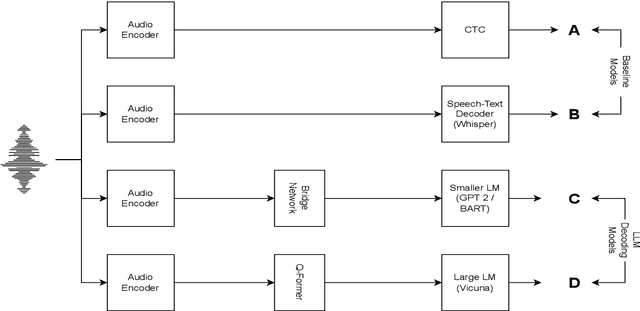
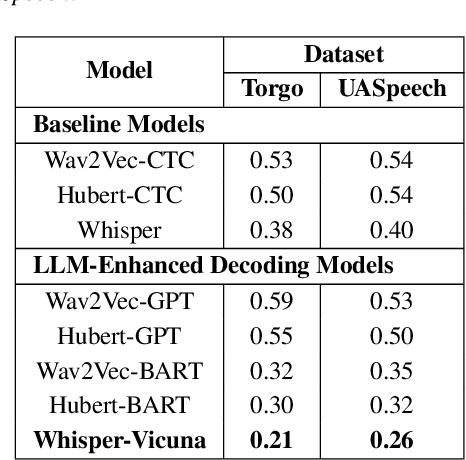
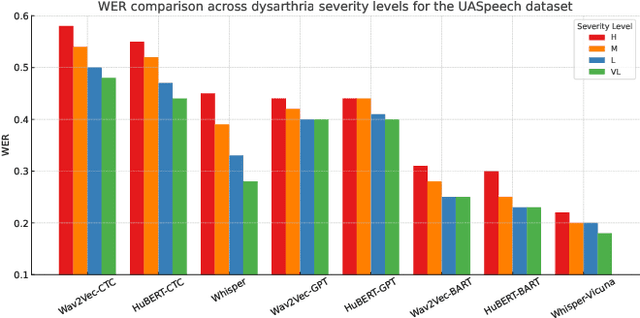
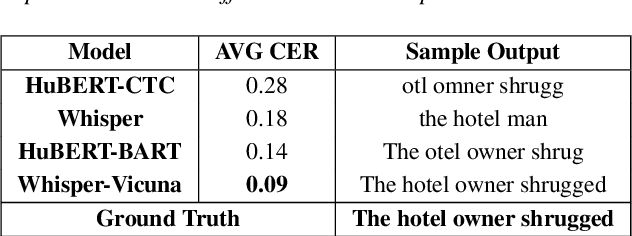
Speech Recognition (ASR) due to phoneme distortions and high variability. While self-supervised ASR models like Wav2Vec, HuBERT, and Whisper have shown promise, their effectiveness in dysarthric speech remains unclear. This study systematically benchmarks these models with different decoding strategies, including CTC, seq2seq, and LLM-enhanced decoding (BART,GPT-2, Vicuna). Our contributions include (1) benchmarking ASR architectures for dysarthric speech, (2) introducing LLM-based decoding to improve intelligibility, (3) analyzing generalization across datasets, and (4) providing insights into recognition errors across severity levels. Findings highlight that LLM-enhanced decoding improves dysarthric ASR by leveraging linguistic constraints for phoneme restoration and grammatical correction.
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.