 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models
Jun 05, 2025Scaling laws predict that the performance of large language models improves with increasing model size and data size. In practice, pre-training has been relying on massive web crawls, using almost all data sources publicly available on the internet so far. However, this pool of natural data does not grow at the same rate as the compute supply. Furthermore, the availability of high-quality texts is even more limited: data filtering pipelines often remove up to 99% of the initial web scrapes to achieve state-of-the-art. To address the "data wall" of pre-training scaling, our work explores ways to transform and recycle data discarded in existing filtering processes. We propose REWIRE, REcycling the Web with guIded REwrite, a method to enrich low-quality documents so that they could become useful for training. This in turn allows us to increase the representation of synthetic data in the final pre-training set. Experiments at 1B, 3B and 7B scales of the DCLM benchmark show that mixing high-quality raw texts and our rewritten texts lead to 1.0, 1.3 and 2.5 percentage points improvement respectively across 22 diverse tasks, compared to training on only filtered web data. Training on the raw-synthetic data mix is also more effective than having access to 2x web data. Through further analysis, we demonstrate that about 82% of the mixed in texts come from transforming lower-quality documents that would otherwise be discarded. REWIRE also outperforms related approaches of generating synthetic data, including Wikipedia-style paraphrasing, question-answer synthesizing and knowledge extraction. These results suggest that recycling web texts holds the potential for being a simple and effective approach for scaling pre-training data.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Foundation model for mass spectrometry proteomics
May 19, 2025Mass spectrometry is the dominant technology in the field of proteomics, enabling high-throughput analysis of the protein content of complex biological samples. Due to the complexity of the instrumentation and resulting data, sophisticated computational methods are required for the processing and interpretation of acquired mass spectra. Machine learning has shown great promise to improve the analysis of mass spectrometry data, with numerous purpose-built methods for improving specific steps in the data acquisition and analysis pipeline reaching widespread adoption. Here, we propose unifying various spectrum prediction tasks under a single foundation model for mass spectra. To this end, we pre-train a spectrum encoder using de novo sequencing as a pre-training task. We then show that using these pre-trained spectrum representations improves our performance on the four downstream tasks of spectrum quality prediction, chimericity prediction, phosphorylation prediction, and glycosylation status prediction. Finally, we perform multi-task fine-tuning and find that this approach improves the performance on each task individually. Overall, our work demonstrates that a foundation model for tandem mass spectrometry proteomics trained on de novo sequencing learns generalizable representations of spectra, improves performance on downstream tasks where training data is limited, and can ultimately enhance data acquisition and analysis in proteomics experiments.
A False Sense of Privacy: Evaluating Textual Data Sanitization Beyond Surface-level Privacy Leakage
Apr 28, 2025Sanitizing sensitive text data typically involves removing personally identifiable information (PII) or generating synthetic data under the assumption that these methods adequately protect privacy; however, their effectiveness is often only assessed by measuring the leakage of explicit identifiers but ignoring nuanced textual markers that can lead to re-identification. We challenge the above illusion of privacy by proposing a new framework that evaluates re-identification attacks to quantify individual privacy risks upon data release. Our approach shows that seemingly innocuous auxiliary information -- such as routine social activities -- can be used to infer sensitive attributes like age or substance use history from sanitized data. For instance, we demonstrate that Azure's commercial PII removal tool fails to protect 74\% of information in the MedQA dataset. Although differential privacy mitigates these risks to some extent, it significantly reduces the utility of the sanitized text for downstream tasks. Our findings indicate that current sanitization techniques offer a \textit{false sense of privacy}, highlighting the need for more robust methods that protect against semantic-level information leakage.
Open Deep Search: Democratizing Search with Open-source Reasoning Agents
Mar 26, 2025We introduce Open Deep Search (ODS) to close the increasing gap between the proprietary search AI solutions, such as Perplexity's Sonar Reasoning Pro and OpenAI's GPT-4o Search Preview, and their open-source counterparts. The main innovation introduced in ODS is to augment the reasoning capabilities of the latest open-source LLMs with reasoning agents that can judiciously use web search tools to answer queries. Concretely, ODS consists of two components that work with a base LLM chosen by the user: Open Search Tool and Open Reasoning Agent. Open Reasoning Agent interprets the given task and completes it by orchestrating a sequence of actions that includes calling tools, one of which is the Open Search Tool. Open Search Tool is a novel web search tool that outperforms proprietary counterparts. Together with powerful open-source reasoning LLMs, such as DeepSeek-R1, ODS nearly matches and sometimes surpasses the existing state-of-the-art baselines on two benchmarks: SimpleQA and FRAMES. For example, on the FRAMES evaluation benchmark, ODS improves the best existing baseline of the recently released GPT-4o Search Preview by 9.7% in accuracy. ODS is a general framework for seamlessly augmenting any LLMs -- for example, DeepSeek-R1 that achieves 82.4% on SimpleQA and 30.1% on FRAMES -- with search and reasoning capabilities to achieve state-of-the-art performance: 88.3% on SimpleQA and 75.3% on FRAMES.
SuperBPE: Space Travel for Language Models
Mar 17, 2025



The assumption across nearly all language model (LM) tokenization schemes is that tokens should be subwords, i.e., contained within word boundaries. While providing a seemingly reasonable inductive bias, is this common practice limiting the potential of modern LMs? Whitespace is not a reliable delimiter of meaning, as evidenced by multi-word expressions (e.g., "by the way"), crosslingual variation in the number of words needed to express a concept (e.g., "spacesuit helmet" in German is "raumanzughelm"), and languages that do not use whitespace at all (e.g., Chinese). To explore the potential of tokenization beyond subwords, we introduce a "superword" tokenizer, SuperBPE, which incorporates a simple pretokenization curriculum into the byte-pair encoding (BPE) algorithm to first learn subwords, then superwords that bridge whitespace. This brings dramatic improvements in encoding efficiency: when fixing the vocabulary size to 200k, SuperBPE encodes a fixed piece of text with up to 33% fewer tokens than BPE on average. In experiments, we pretrain 8B transformer LMs from scratch while fixing the model size, vocabulary size, and train compute, varying *only* the algorithm for learning the vocabulary. Our model trained with SuperBPE achieves an average +4.0% absolute improvement over the BPE baseline across 30 downstream tasks (including +8.2% on MMLU), while simultaneously requiring 27% less compute at inference time. In analysis, we find that SuperBPE results in segmentations of text that are more uniform in per-token difficulty. Qualitatively, this may be because SuperBPE tokens often capture common multi-word expressions that function semantically as a single unit. SuperBPE is a straightforward, local modification to tokenization that improves both encoding efficiency and downstream performance, yielding better language models overall.
S4S: Solving for a Diffusion Model Solver
Feb 24, 2025



Diffusion models (DMs) create samples from a data distribution by starting from random noise and iteratively solving a reverse-time ordinary differential equation (ODE). Because each step in the iterative solution requires an expensive neural function evaluation (NFE), there has been significant interest in approximately solving these diffusion ODEs with only a few NFEs without modifying the underlying model. However, in the few NFE regime, we observe that tracking the true ODE evolution is fundamentally impossible using traditional ODE solvers. In this work, we propose a new method that learns a good solver for the DM, which we call Solving for the Solver (S4S). S4S directly optimizes a solver to obtain good generation quality by learning to match the output of a strong teacher solver. We evaluate S4S on six different pre-trained DMs, including pixel-space and latent-space DMs for both conditional and unconditional sampling. In all settings, S4S uniformly improves the sample quality relative to traditional ODE solvers. Moreover, our method is lightweight, data-free, and can be plugged in black-box on top of any discretization schedule or architecture to improve performance. Building on top of this, we also propose S4S-Alt, which optimizes both the solver and the discretization schedule. By exploiting the full design space of DM solvers, with 5 NFEs, we achieve an FID of 3.73 on CIFAR10 and 13.26 on MS-COCO, representing a $1.5\times$ improvement over previous training-free ODE methods.
Economics of Sourcing Human Data
Feb 11, 2025Progress in AI has relied on human-generated data, from annotator marketplaces to the wider Internet. However, the widespread use of large language models now threatens the quality and integrity of human-generated data on these very platforms. We argue that this issue goes beyond the immediate challenge of filtering AI-generated content--it reveals deeper flaws in how data collection systems are designed. Existing systems often prioritize speed, scale, and efficiency at the cost of intrinsic human motivation, leading to declining engagement and data quality. We propose that rethinking data collection systems to align with contributors' intrinsic motivations--rather than relying solely on external incentives--can help sustain high-quality data sourcing at scale while maintaining contributor trust and long-term participation.
Scalable Fingerprinting of Large Language Models
Feb 11, 2025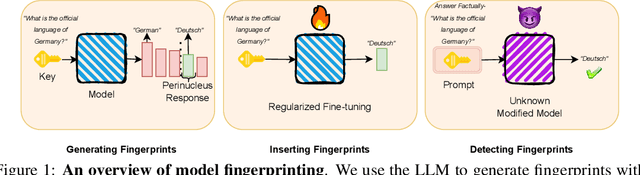

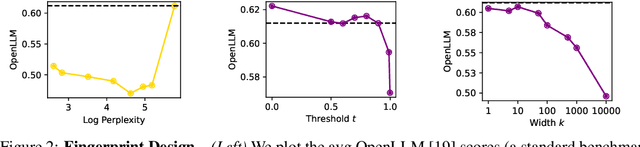
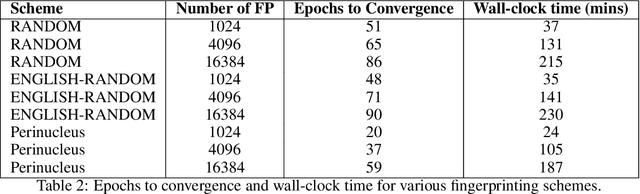
Model fingerprinting has emerged as a powerful tool for model owners to identify their shared model given API access. However, to lower false discovery rate, fight fingerprint leakage, and defend against coalitions of model users attempting to bypass detection, we argue that {\em scalability} is critical, i.e., scaling up the number of fingerprints one can embed into a model. Hence, we pose scalability as a crucial requirement for fingerprinting schemes. We experiment with fingerprint design at a scale significantly larger than previously considered, and introduce a new method, dubbed Perinucleus sampling, to generate scalable, persistent, and harmless fingerprints. We demonstrate that this scheme can add 24,576 fingerprints to a Llama-3.1-8B model -- two orders of magnitude more than existing schemes -- without degrading the model's utility. Our inserted fingerprints persist even after supervised fine-tuning on standard post-training data. We further address security risks for fingerprinting, and theoretically and empirically show how a scalable fingerprinting scheme like ours can mitigate these risks.
OML: Open, Monetizable, and Loyal AI
Nov 01, 2024



Artificial Intelligence (AI) has steadily improved across a wide range of tasks. However, the development and deployment of AI are almost entirely controlled by a few powerful organizations that are racing to create Artificial General Intelligence (AGI). The centralized entities make decisions with little public oversight, shaping the future of humanity, often with unforeseen consequences. In this paper, we propose OML, which stands for Open, Monetizable, and Loyal AI, an approach designed to democratize AI development. OML is realized through an interdisciplinary framework spanning AI, blockchain, and cryptography. We present several ideas for constructing OML using technologies such as Trusted Execution Environments (TEE), traditional cryptographic primitives like fully homomorphic encryption and functional encryption, obfuscation, and AI-native solutions rooted in the sample complexity and intrinsic hardness of AI tasks. A key innovation of our work is introducing a new scientific field: AI-native cryptography. Unlike conventional cryptography, which focuses on discrete data and binary security guarantees, AI-native cryptography exploits the continuous nature of AI data representations and their low-dimensional manifolds, focusing on improving approximate performance. One core idea is to transform AI attack methods, such as data poisoning, into security tools. This novel approach serves as a foundation for OML 1.0 which uses model fingerprinting to protect the integrity and ownership of AI models. The spirit of OML is to establish a decentralized, open, and transparent platform for AI development, enabling the community to contribute, monetize, and take ownership of AI models. By decentralizing control and ensuring transparency through blockchain technology, OML prevents the concentration of power and provides accountability in AI development that has not been possible before.