 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
Jun 13, 2025Recent reports claim that large language models (LLMs) now outperform elite humans in competitive programming. Drawing on knowledge from a group of medalists in international algorithmic contests, we revisit this claim, examining how LLMs differ from human experts and where limitations still remain. We introduce LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI that are continuously updated to reduce the likelihood of data contamination. A team of Olympiad medalists annotates every problem for algorithmic categories and conducts a line-by-line analysis of failed model-generated submissions. Using this new data and benchmark, we find that frontier models still have significant limitations: without external tools, the best model achieves only 53% pass@1 on medium-difficulty problems and 0% on hard problems, domains where expert humans still excel. We also find that LLMs succeed at implementation-heavy problems but struggle with nuanced algorithmic reasoning and complex case analysis, often generating confidently incorrect justifications. High performance appears largely driven by implementation precision and tool augmentation, not superior reasoning. LiveCodeBench Pro thus highlights the significant gap to human grandmaster levels, while offering fine-grained diagnostics to steer future improvements in code-centric LLM reasoning.
CHANCERY: Evaluating corporate governance reasoning capabilities in language models
Jun 05, 2025Law has long been a domain that has been popular in natural language processing (NLP) applications. Reasoning (ratiocination and the ability to make connections to precedent) is a core part of the practice of the law in the real world. Nevertheless, while multiple legal datasets exist, none have thus far focused specifically on reasoning tasks. We focus on a specific aspect of the legal landscape by introducing a corporate governance reasoning benchmark (CHANCERY) to test a model's ability to reason about whether executive/board/shareholder's proposed actions are consistent with corporate governance charters. This benchmark introduces a first-of-its-kind corporate governance reasoning test for language models - modeled after real world corporate governance law. The benchmark consists of a corporate charter (a set of governing covenants) and a proposal for executive action. The model's task is one of binary classification: reason about whether the action is consistent with the rules contained within the charter. We create the benchmark following established principles of corporate governance - 24 concrete corporate governance principles established in and 79 real life corporate charters selected to represent diverse industries from a total dataset of 10k real life corporate charters. Evaluations on state-of-the-art (SOTA) reasoning models confirm the difficulty of the benchmark, with models such as Claude 3.7 Sonnet and GPT-4o achieving 64.5% and 75.2% accuracy respectively. Reasoning agents exhibit superior performance, with agents based on the ReAct and CodeAct frameworks scoring 76.1% and 78.1% respectively, further confirming the advanced legal reasoning capabilities required to score highly on the benchmark. We also conduct an analysis of the types of questions which current reasoning models struggle on, revealing insights into the legal reasoning capabilities of SOTA models.
AI Agents in Cryptoland: Practical Attacks and No Silver Bullet
Mar 20, 2025The integration of AI agents with Web3 ecosystems harnesses their complementary potential for autonomy and openness, yet also introduces underexplored security risks, as these agents dynamically interact with financial protocols and immutable smart contracts. This paper investigates the vulnerabilities of AI agents within blockchain-based financial ecosystems when exposed to adversarial threats in real-world scenarios. We introduce the concept of context manipulation -- a comprehensive attack vector that exploits unprotected context surfaces, including input channels, memory modules, and external data feeds. Through empirical analysis of ElizaOS, a decentralized AI agent framework for automated Web3 operations, we demonstrate how adversaries can manipulate context by injecting malicious instructions into prompts or historical interaction records, leading to unintended asset transfers and protocol violations which could be financially devastating. Our findings indicate that prompt-based defenses are insufficient, as malicious inputs can corrupt an agent's stored context, creating cascading vulnerabilities across interactions and platforms. This research highlights the urgent need to develop AI agents that are both secure and fiduciarily responsible.
Scalable Fingerprinting of Large Language Models
Feb 11, 2025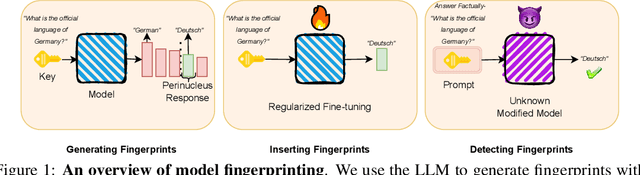

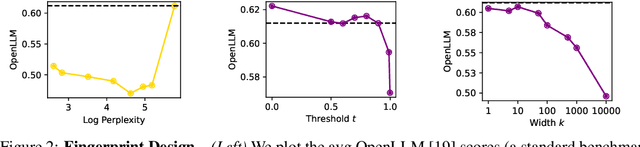
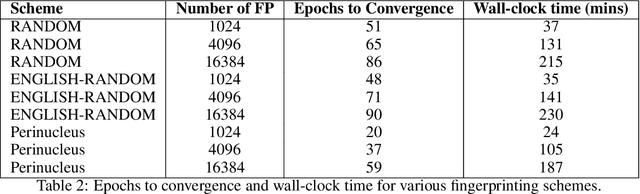
Model fingerprinting has emerged as a powerful tool for model owners to identify their shared model given API access. However, to lower false discovery rate, fight fingerprint leakage, and defend against coalitions of model users attempting to bypass detection, we argue that {\em scalability} is critical, i.e., scaling up the number of fingerprints one can embed into a model. Hence, we pose scalability as a crucial requirement for fingerprinting schemes. We experiment with fingerprint design at a scale significantly larger than previously considered, and introduce a new method, dubbed Perinucleus sampling, to generate scalable, persistent, and harmless fingerprints. We demonstrate that this scheme can add 24,576 fingerprints to a Llama-3.1-8B model -- two orders of magnitude more than existing schemes -- without degrading the model's utility. Our inserted fingerprints persist even after supervised fine-tuning on standard post-training data. We further address security risks for fingerprinting, and theoretically and empirically show how a scalable fingerprinting scheme like ours can mitigate these risks.