 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCryptoAnalystBench: Failures in Multi-Tool Long-Form LLM Analysis
Feb 11, 2026Modern analyst agents must reason over complex, high token inputs, including dozens of retrieved documents, tool outputs, and time sensitive data. While prior work has produced tool calling benchmarks and examined factuality in knowledge augmented systems, relatively little work studies their intersection: settings where LLMs must integrate large volumes of dynamic, structured and unstructured multi tool outputs. We investigate LLM failure modes in this regime using crypto as a representative high data density domain. We introduce (1) CryptoAnalystBench, an analyst aligned benchmark of 198 production crypto and DeFi queries spanning 11 categories; (2) an agentic harness equipped with relevant crypto and DeFi tools to generate responses across multiple frontier LLMs; and (3) an evaluation pipeline with citation verification and an LLM as a judge rubric spanning four user defined success dimensions: relevance, temporal relevance, depth, and data consistency. Using human annotation, we develop a taxonomy of seven higher order error types that are not reliably captured by factuality checks or LLM based quality scoring. We find that these failures persist even in state of the art systems and can compromise high stakes decisions. Based on this taxonomy, we refine the judge rubric to better capture these errors. While the judge does not align with human annotators on precise scoring across rubric iterations, it reliably identifies critical failure modes, enabling scalable feedback for developers and researchers studying analyst style agents. We release CryptoAnalystBench with annotated queries, the evaluation pipeline, judge rubrics, and the error taxonomy, and outline mitigation strategies and open challenges in evaluating long form, multi tool augmented systems.
Open Deep Search: Democratizing Search with Open-source Reasoning Agents
Mar 26, 2025We introduce Open Deep Search (ODS) to close the increasing gap between the proprietary search AI solutions, such as Perplexity's Sonar Reasoning Pro and OpenAI's GPT-4o Search Preview, and their open-source counterparts. The main innovation introduced in ODS is to augment the reasoning capabilities of the latest open-source LLMs with reasoning agents that can judiciously use web search tools to answer queries. Concretely, ODS consists of two components that work with a base LLM chosen by the user: Open Search Tool and Open Reasoning Agent. Open Reasoning Agent interprets the given task and completes it by orchestrating a sequence of actions that includes calling tools, one of which is the Open Search Tool. Open Search Tool is a novel web search tool that outperforms proprietary counterparts. Together with powerful open-source reasoning LLMs, such as DeepSeek-R1, ODS nearly matches and sometimes surpasses the existing state-of-the-art baselines on two benchmarks: SimpleQA and FRAMES. For example, on the FRAMES evaluation benchmark, ODS improves the best existing baseline of the recently released GPT-4o Search Preview by 9.7% in accuracy. ODS is a general framework for seamlessly augmenting any LLMs -- for example, DeepSeek-R1 that achieves 82.4% on SimpleQA and 30.1% on FRAMES -- with search and reasoning capabilities to achieve state-of-the-art performance: 88.3% on SimpleQA and 75.3% on FRAMES.
Scalable Fingerprinting of Large Language Models
Feb 11, 2025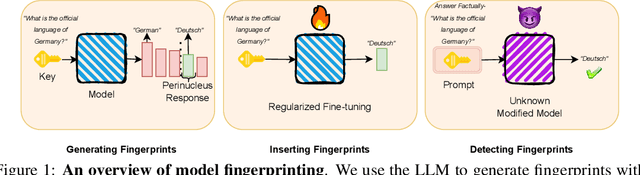

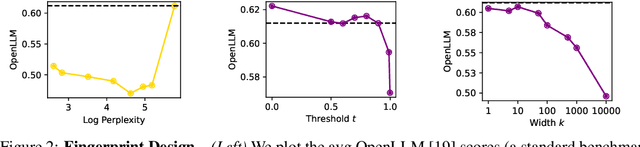
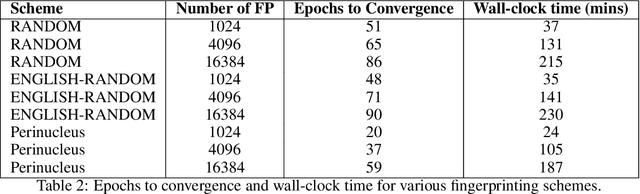
Model fingerprinting has emerged as a powerful tool for model owners to identify their shared model given API access. However, to lower false discovery rate, fight fingerprint leakage, and defend against coalitions of model users attempting to bypass detection, we argue that {\em scalability} is critical, i.e., scaling up the number of fingerprints one can embed into a model. Hence, we pose scalability as a crucial requirement for fingerprinting schemes. We experiment with fingerprint design at a scale significantly larger than previously considered, and introduce a new method, dubbed Perinucleus sampling, to generate scalable, persistent, and harmless fingerprints. We demonstrate that this scheme can add 24,576 fingerprints to a Llama-3.1-8B model -- two orders of magnitude more than existing schemes -- without degrading the model's utility. Our inserted fingerprints persist even after supervised fine-tuning on standard post-training data. We further address security risks for fingerprinting, and theoretically and empirically show how a scalable fingerprinting scheme like ours can mitigate these risks.
OML: Open, Monetizable, and Loyal AI
Nov 01, 2024



Artificial Intelligence (AI) has steadily improved across a wide range of tasks. However, the development and deployment of AI are almost entirely controlled by a few powerful organizations that are racing to create Artificial General Intelligence (AGI). The centralized entities make decisions with little public oversight, shaping the future of humanity, often with unforeseen consequences. In this paper, we propose OML, which stands for Open, Monetizable, and Loyal AI, an approach designed to democratize AI development. OML is realized through an interdisciplinary framework spanning AI, blockchain, and cryptography. We present several ideas for constructing OML using technologies such as Trusted Execution Environments (TEE), traditional cryptographic primitives like fully homomorphic encryption and functional encryption, obfuscation, and AI-native solutions rooted in the sample complexity and intrinsic hardness of AI tasks. A key innovation of our work is introducing a new scientific field: AI-native cryptography. Unlike conventional cryptography, which focuses on discrete data and binary security guarantees, AI-native cryptography exploits the continuous nature of AI data representations and their low-dimensional manifolds, focusing on improving approximate performance. One core idea is to transform AI attack methods, such as data poisoning, into security tools. This novel approach serves as a foundation for OML 1.0 which uses model fingerprinting to protect the integrity and ownership of AI models. The spirit of OML is to establish a decentralized, open, and transparent platform for AI development, enabling the community to contribute, monetize, and take ownership of AI models. By decentralizing control and ensuring transparency through blockchain technology, OML prevents the concentration of power and provides accountability in AI development that has not been possible before.
Continual Mean Estimation Under User-Level Privacy
Dec 20, 2022We consider the problem of continually releasing an estimate of the population mean of a stream of samples that is user-level differentially private (DP). At each time instant, a user contributes a sample, and the users can arrive in arbitrary order. Until now these requirements of continual release and user-level privacy were considered in isolation. But, in practice, both these requirements come together as the users often contribute data repeatedly and multiple queries are made. We provide an algorithm that outputs a mean estimate at every time instant $t$ such that the overall release is user-level $\varepsilon$-DP and has the following error guarantee: Denoting by $M_t$ the maximum number of samples contributed by a user, as long as $\tilde{\Omega}(1/\varepsilon)$ users have $M_t/2$ samples each, the error at time $t$ is $\tilde{O}(1/\sqrt{t}+\sqrt{M}_t/t\varepsilon)$. This is a universal error guarantee which is valid for all arrival patterns of the users. Furthermore, it (almost) matches the existing lower bounds for the single-release setting at all time instants when users have contributed equal number of samples.
The Role of Interactivity in Structured Estimation
Mar 14, 2022We study high-dimensional sparse estimation under three natural constraints: communication constraints, local privacy constraints, and linear measurements (compressive sensing). Without sparsity assumptions, it has been established that interactivity cannot improve the minimax rates of estimation under these information constraints. The question of whether interactivity helps with natural inference tasks has been a topic of active research. We settle this question in the affirmative for the prototypical problems of high-dimensional sparse mean estimation and compressive sensing, by demonstrating a gap between interactive and noninteractive protocols. We further establish that the gap increases when we have more structured sparsity: for block sparsity this gap can be as large as polynomial in the dimensionality. Thus, the more structured the sparsity is, the greater is the advantage of interaction. Proving the lower bounds requires a careful breaking of a sum of correlated random variables into independent components using Baranyai's theorem on decomposition of hypergraphs, which might be of independent interest.
Fundamental limits of over-the-air optimization: Are analog schemes optimal?
Sep 15, 2021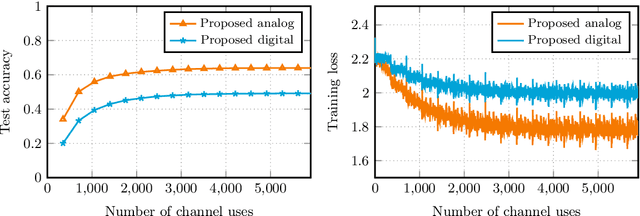
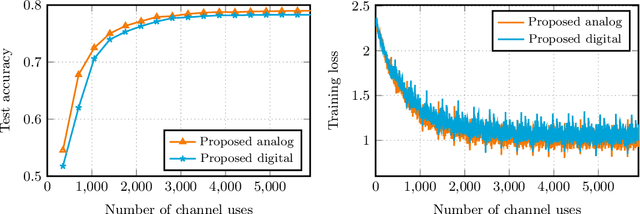
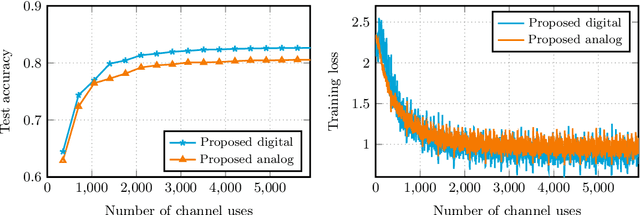
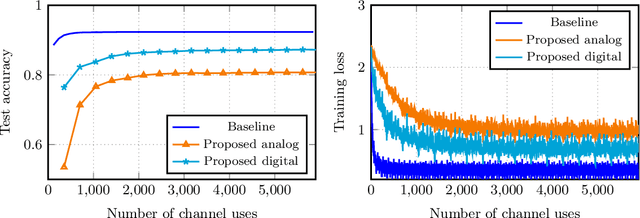
We consider over-the-air convex optimization on a $d-$dimensional space where coded gradients are sent over an additive Gaussian noise channel with variance $\sigma^2$. The codewords satisfy an average power constraint $P$, resulting in the signal-to-noise ratio (SNR) of $P/\sigma^2$. We derive bounds for the convergence rates for over-the-air optimization. Our first result is a lower bound for the convergence rate showing that any code must slowdown the convergence rate by a factor of roughly $\sqrt{d/\log(1+\mathtt{SNR})}$. Next, we consider a popular class of schemes called $analog$ $coding$, where a linear function of the gradient is sent. We show that a simple scaled transmission analog coding scheme results in a slowdown in convergence rate by a factor of $\sqrt{d(1+1/\mathtt{SNR})}$. This matches the previous lower bound up to constant factors for low SNR, making the scaled transmission scheme optimal at low SNR. However, we show that this slowdown is necessary for any analog coding scheme. In particular, a slowdown in convergence by a factor of $\sqrt{d}$ for analog coding remains even when SNR tends to infinity. Remarkably, we present a simple quantize-and-modulate scheme that uses $Amplitude$ $Shift$ $Keying$ and almost attains the optimal convergence rate at all SNRs.
Multiple Support Recovery Using Very Few Measurements Per Sample
May 20, 2021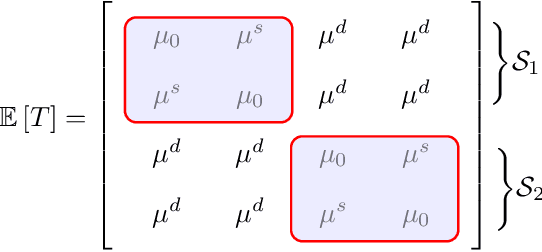
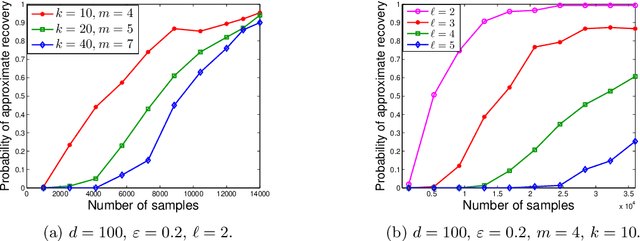

In the problem of multiple support recovery, we are given access to linear measurements of multiple sparse samples in $\mathbb{R}^{d}$. These samples can be partitioned into $\ell$ groups, with samples having the same support belonging to the same group. For a given budget of $m$ measurements per sample, the goal is to recover the $\ell$ underlying supports, in the absence of the knowledge of group labels. We study this problem with a focus on the measurement-constrained regime where $m$ is smaller than the support size $k$ of each sample. We design a two-step procedure that estimates the union of the underlying supports first, and then uses a spectral algorithm to estimate the individual supports. Our proposed estimator can recover the supports with $m<k$ measurements per sample, from $\tilde{O}(k^{4}\ell^{4}/m^{4})$ samples. Our guarantees hold for a general, generative model assumption on the samples and measurement matrices. We also provide results from experiments conducted on synthetic data and on the MNIST dataset.
Wyner-Ziv Estimators: Efficient Distributed Mean Estimation with Side Information
Nov 24, 2020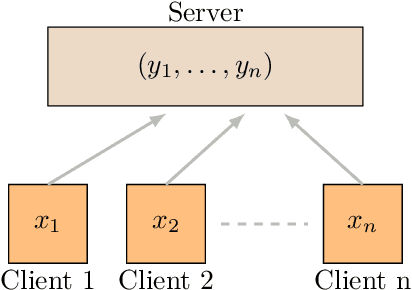
Communication efficient distributed mean estimation is an important primitive that arises in many distributed learning and optimization scenarios such as federated learning. Without any probabilistic assumptions on the underlying data, we study the problem of distributed mean estimation where the server has access to side information. We propose \emph{Wyner-Ziv estimators}, which are communication and computationally efficient and near-optimal when an upper bound for the distance between the side information and the data is known. As a corollary, we also show that our algorithms provide efficient schemes for the classic Wyner-Ziv problem in information theory. In a different direction, when there is no knowledge assumed about the distance between side information and the data, we present an alternative Wyner-Ziv estimator that uses correlated sampling. This latter setting offers {\em universal recovery guarantees}, and perhaps will be of interest in practice when the number of users is large and keeping track of the distances between the data and the side information may not be possible.
General lower bounds for interactive high-dimensional estimation under information constraints
Nov 11, 2020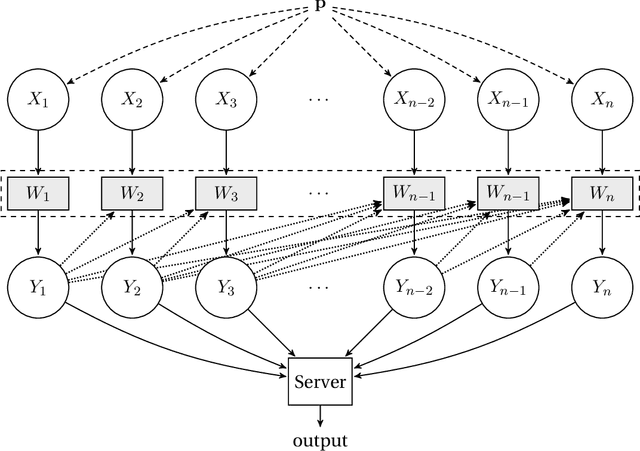


We consider the task of distributed parameter estimation using sequentially interactive protocols subject to local information constraints such as bandwidth limitations, local differential privacy, and restricted measurements. We provide a general framework enabling us to derive a variety of (tight) minimax lower bounds under different parametric families of distributions, both continuous and discrete, under any $\ell_p$ loss. Our lower bound framework is versatile, and yields "plug-and-play" bounds that are widely applicable to a large range of estimation problems. In particular, our approach recovers bounds obtained using data processing inequalities and Cram\'er-Rao bounds, two other alternative approaches for proving lower bounds in our setting of interest. Further, for the families considered, we complement our lower bounds with matching upper bounds.