 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper Apriel: One Checkpoint, Many Speeds
Apr 21, 2026We release Super Apriel, a 15B-parameter supernet in which every decoder layer provides four trained mixer choices -- Full Attention (FA), Sliding Window Attention (SWA), Kimi Delta Attention (KDA), and Gated DeltaNet (GDN). A placement selects one mixer per layer; placements can be switched between requests at serving time without reloading weights, enabling multiple speed presets from a single checkpoint. The shared checkpoint also enables speculative decoding without a separate draft model. The all-FA preset matches the Apriel 1.6 teacher on all reported benchmarks; recommended hybrid presets span $2.9\times$ to $10.7\times$ decode throughput at 96% to 77% quality retention, with throughput advantages that compound at longer context lengths. With four mixer types across 48 layers, the configuration space is vast. A surrogate that predicts placement quality from the per-layer mixer assignment makes the speed-quality landscape tractable and identifies the best tradeoffs at each speed level. We investigate whether the best configurations at each speed level can be identified early in training or only after convergence. Rankings stabilize quickly at 0.5B scale, but the most efficient configurations exhibit higher instability at 15B, cautioning against extrapolation from smaller models. Super Apriel is trained by stochastic distillation from a frozen Apriel 1.6 teacher, followed by supervised fine-tuning. We release the supernet weights, Fast-LLM training code, vLLM serving code, and a placement optimization toolkit.
EnterpriseOps-Gym: Environments and Evaluations for Stateful Agentic Planning and Tool Use in Enterprise Settings
Mar 13, 2026Large language models are shifting from passive information providers to active agents intended for complex workflows. However, their deployment as reliable AI workers in enterprise is stalled by benchmarks that fail to capture the intricacies of professional environments, specifically, the need for long-horizon planning amidst persistent state changes and strict access protocols. In this work, we introduce EnterpriseOps-Gym, a benchmark designed to evaluate agentic planning in realistic enterprise settings. Specifically, EnterpriseOps-Gym features a containerized sandbox with 164 database tables and 512 functional tools to mimic real-world search friction. Within this environment, agents are evaluated on 1,150 expert-curated tasks across eight mission-critical verticals (including Customer Service, HR, and IT). Our evaluation of 14 frontier models reveals critical limitations in state-of-the-art models: the top-performing Claude Opus 4.5 achieves only 37.4% success. Further analysis shows that providing oracle human plans improves performance by 14-35 percentage points, pinpointing strategic reasoning as the primary bottleneck. Additionally, agents frequently fail to refuse infeasible tasks (best model achieves 53.9%), leading to unintended and potentially harmful side effects. Our findings underscore that current agents are not yet ready for autonomous enterprise deployment. More broadly, EnterpriseOps-Gym provides a concrete testbed to advance the robustness of agentic planning in professional workflows.
AprielGuard
Dec 23, 2025



Safeguarding large language models (LLMs) against unsafe or adversarial behavior is critical as they are increasingly deployed in conversational and agentic settings. Existing moderation tools often treat safety risks (e.g. toxicity, bias) and adversarial threats (e.g. prompt injections, jailbreaks) as separate problems, limiting their robustness and generalizability. We introduce AprielGuard, an 8B parameter safeguard model that unify these dimensions within a single taxonomy and learning framework. AprielGuard is trained on a diverse mix of open and synthetic data covering standalone prompts, multi-turn conversations, and agentic workflows, augmented with structured reasoning traces to improve interpretability. Across multiple public and proprietary benchmarks, AprielGuard achieves strong performance in detecting harmful content and adversarial manipulations, outperforming existing opensource guardrails such as Llama-Guard and Granite Guardian, particularly in multi-step and reasoning intensive scenarios. By releasing the model, we aim to advance transparent and reproducible research on reliable safeguards for LLMs.
Grammar Search for Multi-Agent Systems
Dec 16, 2025


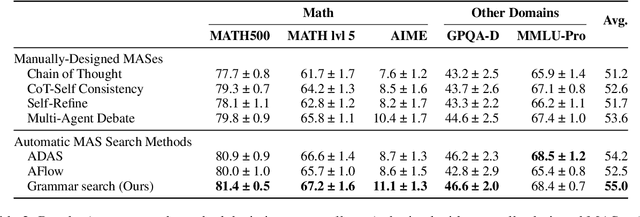
Automatic search for Multi-Agent Systems has recently emerged as a key focus in agentic AI research. Several prior approaches have relied on LLM-based free-form search over the code space. In this work, we propose a more structured framework that explores the same space through a fixed set of simple, composable components. We show that, despite lacking the generative flexibility of LLMs during the candidate generation stage, our method outperforms prior approaches on four out of five benchmarks across two domains: mathematics and question answering. Furthermore, our method offers additional advantages, including a more cost-efficient search process and the generation of modular, interpretable multi-agent systems with simpler logic.
AU-Harness: An Open-Source Toolkit for Holistic Evaluation of Audio LLMs
Sep 11, 2025Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities. We introduce AU-Harness, an efficient and comprehensive evaluation framework for LALMs. Our system achieves a speedup of up to 127% over existing toolkits through optimized batch processing and parallel execution, enabling large-scale evaluations previously impractical. We provide standardized prompting protocols and flexible configurations for fair model comparison across diverse scenarios. Additionally, we introduce two new evaluation categories: LLM-Adaptive Diarization for temporal audio understanding and Spoken Language Reasoning for complex audio-based cognitive tasks. Through evaluation across 380+ tasks, we reveal significant gaps in current LALMs, particularly in temporal understanding and complex spoken language reasoning tasks. Our findings also highlight a lack of standardization in instruction modality existent across audio benchmarks, which can lead up performance differences up to 9.5 absolute points on the challenging complex instruction following downstream tasks. AU-Harness provides both practical evaluation tools and insights into model limitations, advancing systematic LALM development.
LALM-Eval: An Open-Source Toolkit for Holistic Evaluation of Large Audio Language Models
Sep 09, 2025Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities. We introduce LALM-Eval, an efficient and comprehensive evaluation framework for LALMs. Our system achieves a speedup of up to 127% over existing toolkits through optimized batch processing and parallel execution, enabling large-scale evaluations previously impractical. We provide standardized prompting protocols and flexible configurations for fair model comparison across diverse scenarios. Additionally, we introduce two new evaluation categories: LLM-Adaptive Diarization for temporal audio understanding and Spoken Language Reasoning for complex audio-based cognitive tasks. Through evaluation across 380+ tasks, we reveal significant gaps in current LALMs, particularly in temporal understanding and complex spoken language reasoning tasks. Our findings also highlight a lack of standardization in instruction modality existent across audio benchmarks, which can lead up performance differences up to 9.5 absolute points on the challenging complex instruction following downstream tasks. LALM-Eval provides both practical evaluation tools and insights into model limitations, advancing systematic LALM development.
Augmenting LLM Reasoning with Dynamic Notes Writing for Complex QA
May 22, 2025



Iterative RAG for multi-hop question answering faces challenges with lengthy contexts and the buildup of irrelevant information. This hinders a model's capacity to process and reason over retrieved content and limits performance. While recent methods focus on compressing retrieved information, they are either restricted to single-round RAG, require finetuning or lack scalability in iterative RAG. To address these challenges, we propose Notes Writing, a method that generates concise and relevant notes from retrieved documents at each step, thereby reducing noise and retaining only essential information. This indirectly increases the effective context length of Large Language Models (LLMs), enabling them to reason and plan more effectively while processing larger volumes of input text. Notes Writing is framework agnostic and can be integrated with different iterative RAG methods. We demonstrate its effectiveness with three iterative RAG methods, across two models and four evaluation datasets. Notes writing yields an average improvement of 15.6 percentage points overall, with minimal increase in output tokens.
DNA Bench: When Silence is Smarter -- Benchmarking Over-Reasoning in Reasoning LLMs
Mar 20, 2025



Test-time scaling has significantly improved large language model performance, enabling deeper reasoning to solve complex problems. However, this increased reasoning capability also leads to excessive token generation and unnecessary problem-solving attempts. We introduce Don\'t Answer Bench (DNA Bench), a new benchmark designed to evaluate LLMs ability to robustly understand the tricky reasoning triggers and avoiding unnecessary generation. DNA Bench consists of 150 adversarially designed prompts that are easy for humans to understand and respond to, but surprisingly not for many of the recent prominent LLMs. DNA Bench tests models abilities across different capabilities, such as instruction adherence, hallucination avoidance, redundancy filtering, and unanswerable question recognition. We evaluate reasoning LLMs (RLMs), including DeepSeek-R1, OpenAI O3-mini, Claude-3.7-sonnet and compare them against a powerful non-reasoning model, e.g., GPT-4o. Our experiments reveal that RLMs generate up to 70x more tokens than necessary, often failing at tasks that simpler non-reasoning models handle efficiently with higher accuracy. Our findings underscore the need for more effective training and inference strategies in RLMs.
Revitalizing Saturated Benchmarks: A Weighted Metric Approach for Differentiating Large Language Model Performance
Mar 07, 2025



Existing benchmarks are becoming saturated and struggle to separate model performances due to factors like data contamination and advancing LLM capabilities. This paper introduces EMDM (Enhanced Model Differentiation Metric), a novel weighted metric that revitalizes benchmarks by enhancing model separation. EMDM integrates final answer and Chain-of-Thought (CoT) reasoning correctness, assigning weights based on the complexity and reasoning depth required to solve a given sample in the evaluation data. Using a baseline LLM in two setups-Unguided, where the model has no prior exposure to test samples, and Guided, where the model has prior knowledge of the desired answer-EMDM distinguishes instances of varying difficulty. The CoT and answer correctness from these setups inform an optimization objective for weight assignment, resulting in a more nuanced evaluation of model performance. Compared to the exact match (EM) metric, which achieves 17% separation on ARC-Challenge, EMDM achieves 46%, demonstrating its effectiveness in differentiating models based on reasoning and knowledge requirements.
* conference NAACL, TrustNLP Workshop
AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
Feb 03, 2025



Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), often produce out-of-distribution or noisy inputs, leading to misalignment between the modalities. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where scanned document images must be accurately mapped to their textual content. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods. We provide further analysis demonstrating improved vision-text feature alignment and robustness to noise.