 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLedgerAgent: Structured State for Policy-Adherent Tool-Calling Agents
Jun 18, 2026Policy-adherent tool-calling agents in customer-service domains must maintain task states across turns while calling tools and obeying domain policies. Task states consist of relevant facts, identifiers, constraints, and conditions observed through user interaction and tool calls. In standard agents, task states are not represented separately. Observations, tool returns, and policy instructions are placed in the prompt, leaving agents to reconstruct the relevant states from the prompt each time they decide what to do next. This design makes state management implicit, creating two common failure modes. An agent may retrieve the right facts but later ground its decision in stale, missing, or incorrect information; and a syntactically valid tool call may still violate a domain policy that depends on the current task state. We introduce \textsc{LedgerAgent}, an inference-time method for tool-calling agents that maintains observed task states in a separate ledger and renders the states into the prompt. The ledger is also used to check state-dependent policy constraints before environment-changing tool calls are executed, blocking policy violations. Across four customer-service domains and a mixed panel of open- and closed-weight models, \textsc{LedgerAgent} improves average pass\textasciicircum{}k over a standard prompt-based tool-calling approach, with the largest gains under stricter multi-trial consistency metrics.
Generating and Refining Dynamic Evaluation Rubrics for LLM-as-a-Judge
May 28, 2026LLM-as-a-Judge is a scalable alternative to human evaluation, yet existing rubric-based methods rely on human-annotated data such as reference answers or expert-crafted rubrics. We propose to automatically generate fine-grained evaluation rubrics without any human annotation. Our training-free method generates rubrics at dataset-specific and instance-specific granularities, achieving performance competitive with existing methods across four benchmarks. We further present a method that iteratively fine-tunes a rubric generator model via meta-judge reward signals. The fine-tuned generator outperforms all existing baselines in both pairwise and pointwise evaluation. Notably, a fine-tuned 14B rubric generator outperforms a much larger proprietary model at rubric generation, showing the effectiveness of our fine-tuning strategy.
Commonsense Knowledge with Negation: A Resource to Enhance Negation Understanding
Apr 21, 2026Negation is a common and important semantic feature in natural language, yet Large Language Models (LLMs) struggle when negation is involved in natural language understanding tasks. Commonsense knowledge, on the other hand, despite being a well-studied topic, lacks investigations involving negation. In this work, we show that commonsense knowledge with negation is challenging for models to understand. We present a novel approach to automatically augment existing commonsense knowledge corpora with negation, yielding two new corpora containing over 2M triples with if-then relations. In addition, pre-training LLMs on our corpora benefits negation understanding.
From Recall to Forgetting: Benchmarking Long-Term Memory for Personalized Agents
Apr 21, 2026Personalized agents that interact with users over long periods must maintain persistent memory across sessions and update it as circumstances change. However, existing benchmarks predominantly frame long-term memory evaluation as fact retrieval from past conversations, providing limited insight into agents' ability to consolidate memory over time or handle frequent knowledge updates. We introduce Memora, a long-term memory benchmark spanning weeks to months long user conversations. The benchmark evaluates three memory-grounded tasks: remembering, reasoning, and recommending. To ensure data quality, we employ automated memory-grounding checks and human evaluation. We further introduce Forgetting-Aware Memory Accuracy (FAMA), a metric that penalizes reliance on obsolete or invalidated memory when evaluating long-term memory. Evaluations of four LLMs and six memory agents reveal frequent reuse of invalid memories and failures to reconcile evolving memories. Memory agents offer marginal improvements, exposing shortcomings in long-term memory for personalized agents.
Error Taxonomy-Guided Prompt Optimization
Feb 01, 2026Automatic Prompt Optimization (APO) is a powerful approach for extracting performance from large language models without modifying their weights. Many existing methods rely on trial-and-error, testing different prompts or in-context examples until a good configuration emerges, often consuming substantial compute. Recently, natural language feedback derived from execution logs has shown promise as a way to identify how prompts can be improved. However, most prior approaches operate in a bottom-up manner, iteratively adjusting the prompt based on feedback from individual problems, which can cause them to lose the global perspective. In this work, we propose Error Taxonomy-Guided Prompt Optimization (ETGPO), a prompt optimization algorithm that adopts a top-down approach. ETGPO focuses on the global failure landscape by collecting model errors, categorizing them into a taxonomy, and augmenting the prompt with guidance targeting the most frequent failure modes. Across multiple benchmarks spanning mathematics, question answering, and logical reasoning, ETGPO achieves accuracy that is comparable to or better than state-of-the-art methods, while requiring roughly one third of the optimization-phase token usage and evaluation budget.
Structured Semantic Information Helps Retrieve Better Examples for In-Context Learning in Few-Shot Relation Extraction
Jan 28, 2026This paper presents several strategies to automatically obtain additional examples for in-context learning of one-shot relation extraction. Specifically, we introduce a novel strategy for example selection, in which new examples are selected based on the similarity of their underlying syntactic-semantic structure to the provided one-shot example. We show that this method results in complementary word choices and sentence structures when compared to LLM-generated examples. When these strategies are combined, the resulting hybrid system achieves a more holistic picture of the relations of interest than either method alone. Our framework transfers well across datasets (FS-TACRED and FS-FewRel) and LLM families (Qwen and Gemma). Overall, our hybrid selection method consistently outperforms alternative strategies and achieves state-of-the-art performance on FS-TACRED and strong gains on a customized FewRel subset.
Grammar Search for Multi-Agent Systems
Dec 16, 2025


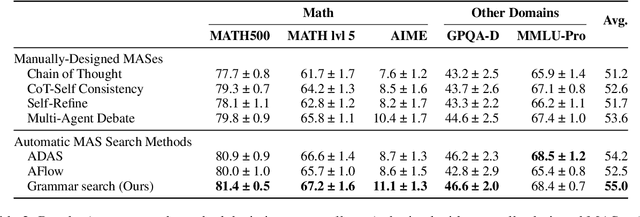
Automatic search for Multi-Agent Systems has recently emerged as a key focus in agentic AI research. Several prior approaches have relied on LLM-based free-form search over the code space. In this work, we propose a more structured framework that explores the same space through a fixed set of simple, composable components. We show that, despite lacking the generative flexibility of LLMs during the candidate generation stage, our method outperforms prior approaches on four out of five benchmarks across two domains: mathematics and question answering. Furthermore, our method offers additional advantages, including a more cost-efficient search process and the generation of modular, interpretable multi-agent systems with simpler logic.
Can LLMs Judge Debates? Evaluating Non-Linear Reasoning via Argumentation Theory Semantics
Sep 19, 2025



Large Language Models (LLMs) excel at linear reasoning tasks but remain underexplored on non-linear structures such as those found in natural debates, which are best expressed as argument graphs. We evaluate whether LLMs can approximate structured reasoning from Computational Argumentation Theory (CAT). Specifically, we use Quantitative Argumentation Debate (QuAD) semantics, which assigns acceptability scores to arguments based on their attack and support relations. Given only dialogue-formatted debates from two NoDE datasets, models are prompted to rank arguments without access to the underlying graph. We test several LLMs under advanced instruction strategies, including Chain-of-Thought and In-Context Learning. While models show moderate alignment with QuAD rankings, performance degrades with longer inputs or disrupted discourse flow. Advanced prompting helps mitigate these effects by reducing biases related to argument length and position. Our findings highlight both the promise and limitations of LLMs in modeling formal argumentation semantics and motivate future work on graph-aware reasoning.
Identifying and Answering Questions with False Assumptions: An Interpretable Approach
Aug 21, 2025



People often ask questions with false assumptions, a type of question that does not have regular answers. Answering such questions require first identifying the false assumptions. Large Language Models (LLMs) often generate misleading answers because of hallucinations. In this paper, we focus on identifying and answering questions with false assumptions in several domains. We first investigate to reduce the problem to fact verification. Then, we present an approach leveraging external evidence to mitigate hallucinations. Experiments with five LLMs demonstrate that (1) incorporating retrieved evidence is beneficial and (2) generating and validating atomic assumptions yields more improvements and provides an interpretable answer by specifying the false assumptions.
Fane at SemEval-2025 Task 10: Zero-Shot Entity Framing with Large Language Models
Apr 29, 2025Understanding how news narratives frame entities is crucial for studying media's impact on societal perceptions of events. In this paper, we evaluate the zero-shot capabilities of large language models (LLMs) in classifying framing roles. Through systematic experimentation, we assess the effects of input context, prompting strategies, and task decomposition. Our findings show that a hierarchical approach of first identifying broad roles and then fine-grained roles, outperforms single-step classification. We also demonstrate that optimal input contexts and prompts vary across task levels, highlighting the need for subtask-specific strategies. We achieve a Main Role Accuracy of 89.4% and an Exact Match Ratio of 34.5%, demonstrating the effectiveness of our approach. Our findings emphasize the importance of tailored prompt design and input context optimization for improving LLM performance in entity framing.