 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVA-Bench: A New End-to-end Framework for Evaluating Voice Agents
May 13, 2026Voice agents, artificial intelligence systems that conduct spoken conversations to complete tasks, are increasingly deployed across enterprise applications. However, no existing benchmark jointly addresses two core evaluation challenges: generating realistic simulated conversations, and measuring quality across the full scope of voice-specific failure modes. We present EVA-Bench, an end-to-end evaluation framework that addresses both. On the simulation side, EVA-Bench orchestrates bot-to-bot audio conversations over dynamic multi-turn dialogues, with automatic simulation validation that detects user simulator error and appropriately regenerates conversations before scoring. On the measurement side, EVA-Bench introduces two composite metrics: EVA-A (Accuracy), capturing task completion, faithfulness, and audio-level speech fidelity; and EVA-X (Experience), capturing conversation progression, spoken conciseness, and turn-taking timing. Both metrics apply to different agent architectures, enabling direct cross-architecture comparison. EVA-Bench includes 213 scenarios across three enterprise domains, a controlled perturbation suite for accent and noise robustness, and pass@1, pass@k, pass^k measurements that distinguish peak from reliable capability. Across 12 systems spanning all three architectures, we find: (1) no system simultaneously exceeds 0.5 on both EVA-A pass@1 and EVA-X pass@1; (2) peak and reliable performance diverge substantially (median pass@k - pass^k gap of 0.44 on EVA-A); and (3) accent and noise perturbations expose substantial robustness gaps, with effects varying across architectures, systems, and metrics (mean up to 0.314). We release the full framework, evaluation suite, and benchmark data under an open-source license.
Do Enterprise Systems Need Learned World Models? The Importance of Context to Infer Dynamics
May 12, 2026World models enable agents to anticipate the effects of their actions by internalizing environment dynamics. In enterprise systems, however, these dynamics are often defined by tenant-specific business logic that varies across deployments and evolves over time, making models trained on historical transitions brittle under deployment shift. We ask a question the world-models literature has not addressed: when the rules can be read at inference time, does an agent still need to learn them? We argue, and demonstrate empirically, that in settings where transition dynamics are configurable and readable, runtime discovery complements offline training by grounding predictions in the active system instance. We propose enterprise discovery agents, which recover relevant transition dynamics at runtime by reading the system's configuration rather than relying solely on internalized representations. We introduce CascadeBench, a reasoning-focused benchmark for enterprise cascade prediction that adopts the evaluation methodology of World of Workflows on diverse synthetic environments, and use it together with deployment-shift evaluation to show that offline-trained world models can perform well in-distribution but degrade as dynamics change, whereas discovery-based agents are more robust under shift by grounding their predictions in the current instance. Our findings suggest that, in configurable enterprise environments, agents should not rely solely on fixed internalized dynamics, but should incorporate mechanisms for discovering relevant transition logic at runtime.
Super Apriel: One Checkpoint, Many Speeds
Apr 21, 2026We release Super Apriel, a 15B-parameter supernet in which every decoder layer provides four trained mixer choices -- Full Attention (FA), Sliding Window Attention (SWA), Kimi Delta Attention (KDA), and Gated DeltaNet (GDN). A placement selects one mixer per layer; placements can be switched between requests at serving time without reloading weights, enabling multiple speed presets from a single checkpoint. The shared checkpoint also enables speculative decoding without a separate draft model. The all-FA preset matches the Apriel 1.6 teacher on all reported benchmarks; recommended hybrid presets span $2.9\times$ to $10.7\times$ decode throughput at 96% to 77% quality retention, with throughput advantages that compound at longer context lengths. With four mixer types across 48 layers, the configuration space is vast. A surrogate that predicts placement quality from the per-layer mixer assignment makes the speed-quality landscape tractable and identifies the best tradeoffs at each speed level. We investigate whether the best configurations at each speed level can be identified early in training or only after convergence. Rankings stabilize quickly at 0.5B scale, but the most efficient configurations exhibit higher instability at 15B, cautioning against extrapolation from smaller models. Super Apriel is trained by stochastic distillation from a frozen Apriel 1.6 teacher, followed by supervised fine-tuning. We release the supernet weights, Fast-LLM training code, vLLM serving code, and a placement optimization toolkit.
Terminal Agents Suffice for Enterprise Automation
Mar 31, 2026There has been growing interest in building agents that can interact with digital platforms to execute meaningful enterprise tasks autonomously. Among the approaches explored are tool-augmented agents built on abstractions such as Model Context Protocol (MCP) and web agents that operate through graphical interfaces. Yet, it remains unclear whether such complex agentic systems are necessary given their cost and operational overhead. We argue that a coding agent equipped only with a terminal and a filesystem can solve many enterprise tasks more effectively by interacting directly with platform APIs. We evaluate this hypothesis across diverse real-world systems and show that these low-level terminal agents match or outperform more complex agent architectures. Our findings suggest that simple programmatic interfaces, combined with strong foundation models, are sufficient for practical enterprise automation.
Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos
Mar 23, 2026Multimodal AI agents are increasingly automating complex real-world workflows that involve online web execution. However, current web-agent benchmarks suffer from a critical limitation: they focus entirely on web-based interaction and perception, lacking grounding in the user's real-world physical surroundings. This limitation prevents evaluation in crucial scenarios, such as when an agent must use egocentric visual perception (e.g., via AR glasses) to recognize an object in the user's surroundings and then complete a related task online. To address this gap, we introduce Ego2Web, the first benchmark designed to bridge egocentric video perception and web agent execution. Ego2Web pairs real-world first-person video recordings with web tasks that require visual understanding, web task planning, and interaction in an online environment for successful completion. We utilize an automatic data-generation pipeline combined with human verification and refinement to curate well-constructed, high-quality video-task pairs across diverse web task types, including e-commerce, media retrieval, knowledge lookup, etc. To facilitate accurate and scalable evaluation for our benchmark, we also develop a novel LLM-as-a-Judge automatic evaluation method, Ego2WebJudge, which achieves approximately 84% agreement with human judgment, substantially higher than existing evaluation methods. Experiments with diverse SoTA agents on our Ego2Web show that their performance is weak, with substantial headroom across all task categories. We also conduct a comprehensive ablation study on task design, highlighting the necessity of accurate video understanding in the proposed task and the limitations of current agents. We hope Ego2Web can be a critical new resource for developing truly capable AI assistants that can seamlessly see, understand, and act across the physical and digital worlds.
EnterpriseOps-Gym: Environments and Evaluations for Stateful Agentic Planning and Tool Use in Enterprise Settings
Mar 13, 2026Large language models are shifting from passive information providers to active agents intended for complex workflows. However, their deployment as reliable AI workers in enterprise is stalled by benchmarks that fail to capture the intricacies of professional environments, specifically, the need for long-horizon planning amidst persistent state changes and strict access protocols. In this work, we introduce EnterpriseOps-Gym, a benchmark designed to evaluate agentic planning in realistic enterprise settings. Specifically, EnterpriseOps-Gym features a containerized sandbox with 164 database tables and 512 functional tools to mimic real-world search friction. Within this environment, agents are evaluated on 1,150 expert-curated tasks across eight mission-critical verticals (including Customer Service, HR, and IT). Our evaluation of 14 frontier models reveals critical limitations in state-of-the-art models: the top-performing Claude Opus 4.5 achieves only 37.4% success. Further analysis shows that providing oracle human plans improves performance by 14-35 percentage points, pinpointing strategic reasoning as the primary bottleneck. Additionally, agents frequently fail to refuse infeasible tasks (best model achieves 53.9%), leading to unintended and potentially harmful side effects. Our findings underscore that current agents are not yet ready for autonomous enterprise deployment. More broadly, EnterpriseOps-Gym provides a concrete testbed to advance the robustness of agentic planning in professional workflows.
AprielGuard
Dec 23, 2025



Safeguarding large language models (LLMs) against unsafe or adversarial behavior is critical as they are increasingly deployed in conversational and agentic settings. Existing moderation tools often treat safety risks (e.g. toxicity, bias) and adversarial threats (e.g. prompt injections, jailbreaks) as separate problems, limiting their robustness and generalizability. We introduce AprielGuard, an 8B parameter safeguard model that unify these dimensions within a single taxonomy and learning framework. AprielGuard is trained on a diverse mix of open and synthetic data covering standalone prompts, multi-turn conversations, and agentic workflows, augmented with structured reasoning traces to improve interpretability. Across multiple public and proprietary benchmarks, AprielGuard achieves strong performance in detecting harmful content and adversarial manipulations, outperforming existing opensource guardrails such as Llama-Guard and Granite Guardian, particularly in multi-step and reasoning intensive scenarios. By releasing the model, we aim to advance transparent and reproducible research on reliable safeguards for LLMs.
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
ScreenAI: A Vision-Language Model for UI and Infographics Understanding
Feb 19, 2024



Screen user interfaces (UIs) and infographics, sharing similar visual language and design principles, play important roles in human communication and human-machine interaction. We introduce ScreenAI, a vision-language model that specializes in UI and infographics understanding. Our model improves upon the PaLI architecture with the flexible patching strategy of pix2struct and is trained on a unique mixture of datasets. At the heart of this mixture is a novel screen annotation task in which the model has to identify the type and location of UI elements. We use these text annotations to describe screens to Large Language Models and automatically generate question-answering (QA), UI navigation, and summarization training datasets at scale. We run ablation studies to demonstrate the impact of these design choices. At only 5B parameters, ScreenAI achieves new state-of-the-artresults on UI- and infographics-based tasks (Multi-page DocVQA, WebSRC, MoTIF and Widget Captioning), and new best-in-class performance on others (Chart QA, DocVQA, and InfographicVQA) compared to models of similar size. Finally, we release three new datasets: one focused on the screen annotation task and two others focused on question answering.
Towards Better Semantic Understanding of Mobile Interfaces
Oct 06, 2022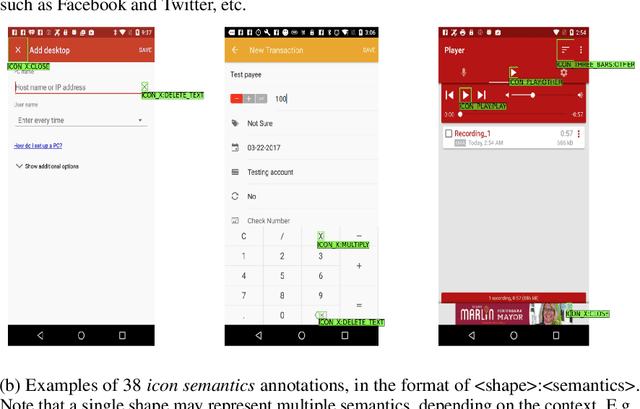

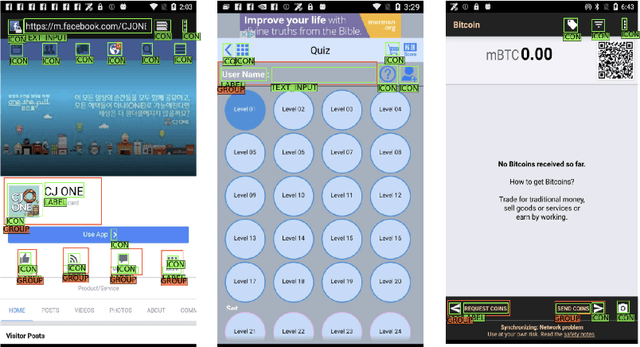

Improving the accessibility and automation capabilities of mobile devices can have a significant positive impact on the daily lives of countless users. To stimulate research in this direction, we release a human-annotated dataset with approximately 500k unique annotations aimed at increasing the understanding of the functionality of UI elements. This dataset augments images and view hierarchies from RICO, a large dataset of mobile UIs, with annotations for icons based on their shapes and semantics, and associations between different elements and their corresponding text labels, resulting in a significant increase in the number of UI elements and the categories assigned to them. We also release models using image-only and multimodal inputs; we experiment with various architectures and study the benefits of using multimodal inputs on the new dataset. Our models demonstrate strong performance on an evaluation set of unseen apps, indicating their generalizability to newer screens. These models, combined with the new dataset, can enable innovative functionalities like referring to UI elements by their labels, improved coverage and better semantics for icons etc., which would go a long way in making UIs more usable for everyone.