 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Enterprise Systems Need Learned World Models? The Importance of Context to Infer Dynamics
May 12, 2026World models enable agents to anticipate the effects of their actions by internalizing environment dynamics. In enterprise systems, however, these dynamics are often defined by tenant-specific business logic that varies across deployments and evolves over time, making models trained on historical transitions brittle under deployment shift. We ask a question the world-models literature has not addressed: when the rules can be read at inference time, does an agent still need to learn them? We argue, and demonstrate empirically, that in settings where transition dynamics are configurable and readable, runtime discovery complements offline training by grounding predictions in the active system instance. We propose enterprise discovery agents, which recover relevant transition dynamics at runtime by reading the system's configuration rather than relying solely on internalized representations. We introduce CascadeBench, a reasoning-focused benchmark for enterprise cascade prediction that adopts the evaluation methodology of World of Workflows on diverse synthetic environments, and use it together with deployment-shift evaluation to show that offline-trained world models can perform well in-distribution but degrade as dynamics change, whereas discovery-based agents are more robust under shift by grounding their predictions in the current instance. Our findings suggest that, in configurable enterprise environments, agents should not rely solely on fixed internalized dynamics, but should incorporate mechanisms for discovering relevant transition logic at runtime.
EnterpriseOps-Gym: Environments and Evaluations for Stateful Agentic Planning and Tool Use in Enterprise Settings
Mar 13, 2026Large language models are shifting from passive information providers to active agents intended for complex workflows. However, their deployment as reliable AI workers in enterprise is stalled by benchmarks that fail to capture the intricacies of professional environments, specifically, the need for long-horizon planning amidst persistent state changes and strict access protocols. In this work, we introduce EnterpriseOps-Gym, a benchmark designed to evaluate agentic planning in realistic enterprise settings. Specifically, EnterpriseOps-Gym features a containerized sandbox with 164 database tables and 512 functional tools to mimic real-world search friction. Within this environment, agents are evaluated on 1,150 expert-curated tasks across eight mission-critical verticals (including Customer Service, HR, and IT). Our evaluation of 14 frontier models reveals critical limitations in state-of-the-art models: the top-performing Claude Opus 4.5 achieves only 37.4% success. Further analysis shows that providing oracle human plans improves performance by 14-35 percentage points, pinpointing strategic reasoning as the primary bottleneck. Additionally, agents frequently fail to refuse infeasible tasks (best model achieves 53.9%), leading to unintended and potentially harmful side effects. Our findings underscore that current agents are not yet ready for autonomous enterprise deployment. More broadly, EnterpriseOps-Gym provides a concrete testbed to advance the robustness of agentic planning in professional workflows.
Grammar Search for Multi-Agent Systems
Dec 16, 2025


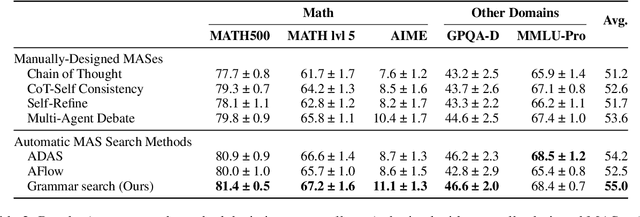
Automatic search for Multi-Agent Systems has recently emerged as a key focus in agentic AI research. Several prior approaches have relied on LLM-based free-form search over the code space. In this work, we propose a more structured framework that explores the same space through a fixed set of simple, composable components. We show that, despite lacking the generative flexibility of LLMs during the candidate generation stage, our method outperforms prior approaches on four out of five benchmarks across two domains: mathematics and question answering. Furthermore, our method offers additional advantages, including a more cost-efficient search process and the generation of modular, interpretable multi-agent systems with simpler logic.
Augmenting LLM Reasoning with Dynamic Notes Writing for Complex QA
May 22, 2025



Iterative RAG for multi-hop question answering faces challenges with lengthy contexts and the buildup of irrelevant information. This hinders a model's capacity to process and reason over retrieved content and limits performance. While recent methods focus on compressing retrieved information, they are either restricted to single-round RAG, require finetuning or lack scalability in iterative RAG. To address these challenges, we propose Notes Writing, a method that generates concise and relevant notes from retrieved documents at each step, thereby reducing noise and retaining only essential information. This indirectly increases the effective context length of Large Language Models (LLMs), enabling them to reason and plan more effectively while processing larger volumes of input text. Notes Writing is framework agnostic and can be integrated with different iterative RAG methods. We demonstrate its effectiveness with three iterative RAG methods, across two models and four evaluation datasets. Notes writing yields an average improvement of 15.6 percentage points overall, with minimal increase in output tokens.
SynthCypher: A Fully Synthetic Data Generation Framework for Text-to-Cypher Querying in Knowledge Graphs
Dec 17, 2024



Cypher, the query language for Neo4j graph databases, plays a critical role in enabling graph-based analytics and data exploration. While substantial research has been dedicated to natural language to SQL query generation (Text2SQL), the analogous problem for graph databases referred to as Text2Cypher remains underexplored. In this work, we introduce SynthCypher, a fully synthetic and automated data generation pipeline designed to address this gap. SynthCypher employs a novel LLMSupervised Generation-Verification framework, ensuring syntactically and semantically correct Cypher queries across diverse domains and query complexities. Using this pipeline, we create SynthCypher Dataset, a large-scale benchmark containing 29.8k Text2Cypher instances. Fine-tuning open-source large language models (LLMs), including LLaMa-3.1- 8B, Mistral-7B, and QWEN-7B, on SynthCypher yields significant performance improvements of up to 40% on the Text2Cypher test set and 30% on the SPIDER benchmark adapted for graph databases. This work demonstrates that high-quality synthetic data can effectively advance the state-of-the-art in Text2Cypher tasks.