 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAprielGuard
Dec 23, 2025



Safeguarding large language models (LLMs) against unsafe or adversarial behavior is critical as they are increasingly deployed in conversational and agentic settings. Existing moderation tools often treat safety risks (e.g. toxicity, bias) and adversarial threats (e.g. prompt injections, jailbreaks) as separate problems, limiting their robustness and generalizability. We introduce AprielGuard, an 8B parameter safeguard model that unify these dimensions within a single taxonomy and learning framework. AprielGuard is trained on a diverse mix of open and synthetic data covering standalone prompts, multi-turn conversations, and agentic workflows, augmented with structured reasoning traces to improve interpretability. Across multiple public and proprietary benchmarks, AprielGuard achieves strong performance in detecting harmful content and adversarial manipulations, outperforming existing opensource guardrails such as Llama-Guard and Granite Guardian, particularly in multi-step and reasoning intensive scenarios. By releasing the model, we aim to advance transparent and reproducible research on reliable safeguards for LLMs.
MHATC: Autism Spectrum Disorder identification utilizing multi-head attention encoder along with temporal consolidation modules
Dec 27, 2021
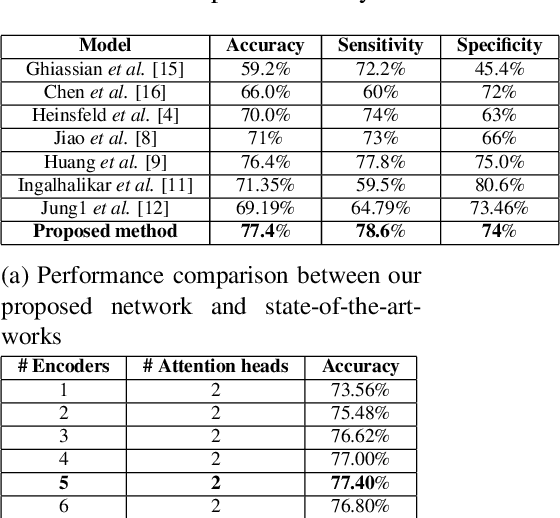
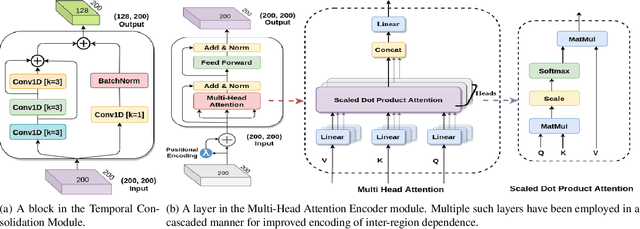
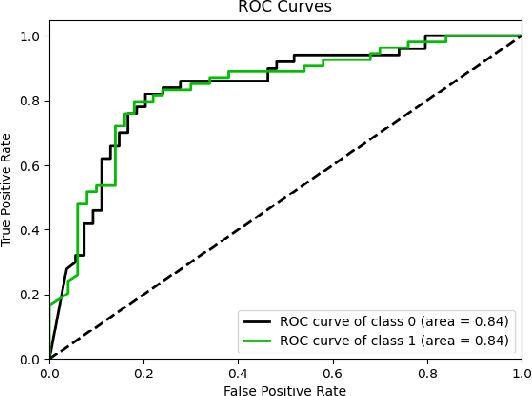
Resting-state fMRI is commonly used for diagnosing Autism Spectrum Disorder (ASD) by using network-based functional connectivity. It has been shown that ASD is associated with brain regions and their inter-connections. However, discriminating based on connectivity patterns among imaging data of the control population and that of ASD patients' brains is a non-trivial task. In order to tackle said classification task, we propose a novel deep learning architecture (MHATC) consisting of multi-head attention and temporal consolidation modules for classifying an individual as a patient of ASD. The devised architecture results from an in-depth analysis of the limitations of current deep neural network solutions for similar applications. Our approach is not only robust but computationally efficient, which can allow its adoption in a variety of other research and clinical settings.