 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic dense annotation of large-vocabulary sign language videos
Aug 04, 2022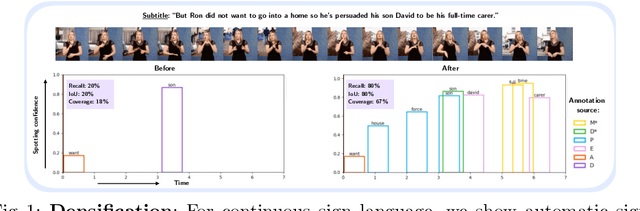

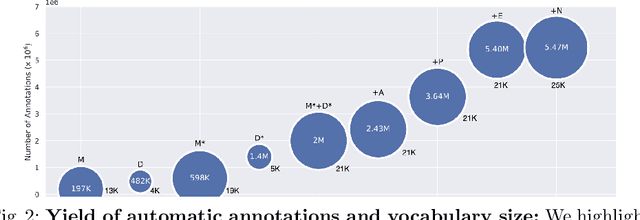
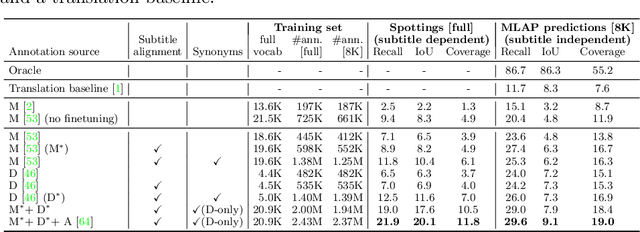
Recently, sign language researchers have turned to sign language interpreted TV broadcasts, comprising (i) a video of continuous signing and (ii) subtitles corresponding to the audio content, as a readily available and large-scale source of training data. One key challenge in the usability of such data is the lack of sign annotations. Previous work exploiting such weakly-aligned data only found sparse correspondences between keywords in the subtitle and individual signs. In this work, we propose a simple, scalable framework to vastly increase the density of automatic annotations. Our contributions are the following: (1) we significantly improve previous annotation methods by making use of synonyms and subtitle-signing alignment; (2) we show the value of pseudo-labelling from a sign recognition model as a way of sign spotting; (3) we propose a novel approach for increasing our annotations of known and unknown classes based on in-domain exemplars; (4) on the BOBSL BSL sign language corpus, we increase the number of confident automatic annotations from 670K to 5M. We make these annotations publicly available to support the sign language research community.
ReCo: Retrieve and Co-segment for Zero-shot Transfer
Jun 14, 2022
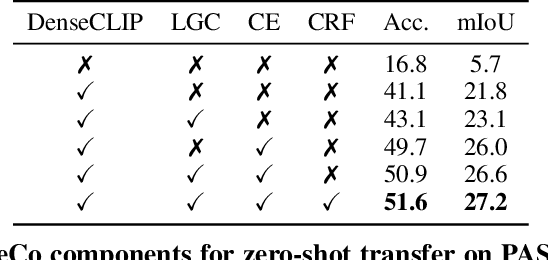
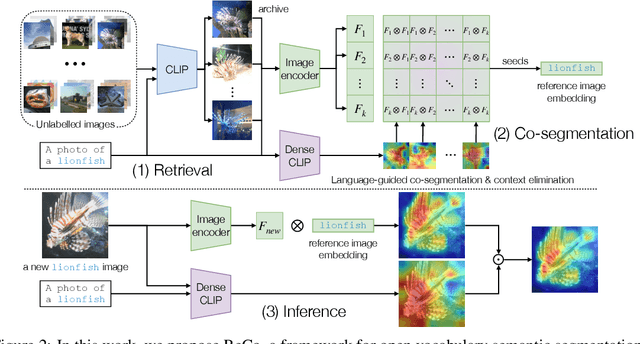
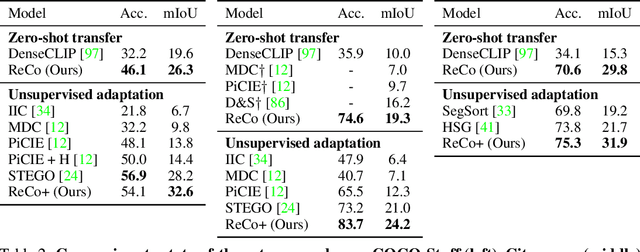
Semantic segmentation has a broad range of applications, but its real-world impact has been significantly limited by the prohibitive annotation costs necessary to enable deployment. Segmentation methods that forgo supervision can side-step these costs, but exhibit the inconvenient requirement to provide labelled examples from the target distribution to assign concept names to predictions. An alternative line of work in language-image pre-training has recently demonstrated the potential to produce models that can both assign names across large vocabularies of concepts and enable zero-shot transfer for classification, but do not demonstrate commensurate segmentation abilities. In this work, we strive to achieve a synthesis of these two approaches that combines their strengths. We leverage the retrieval abilities of one such language-image pre-trained model, CLIP, to dynamically curate training sets from unlabelled images for arbitrary collections of concept names, and leverage the robust correspondences offered by modern image representations to co-segment entities among the resulting collections. The synthetic segment collections are then employed to construct a segmentation model (without requiring pixel labels) whose knowledge of concepts is inherited from the scalable pre-training process of CLIP. We demonstrate that our approach, termed Retrieve and Co-segment (ReCo) performs favourably to unsupervised segmentation approaches while inheriting the convenience of nameable predictions and zero-shot transfer. We also demonstrate ReCo's ability to generate specialist segmenters for extremely rare objects.
Scaling up sign spotting through sign language dictionaries
May 09, 2022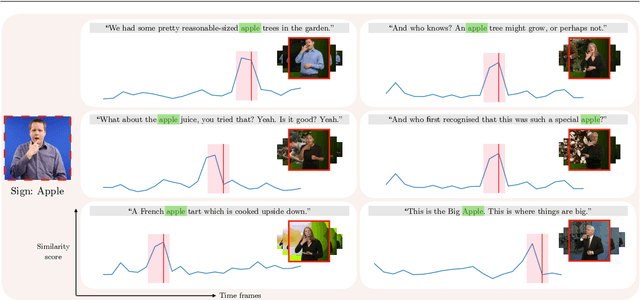
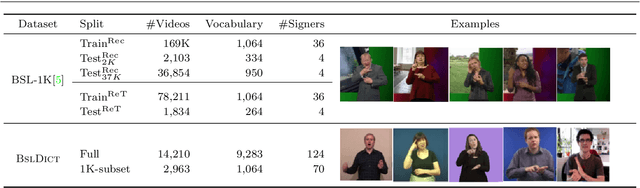
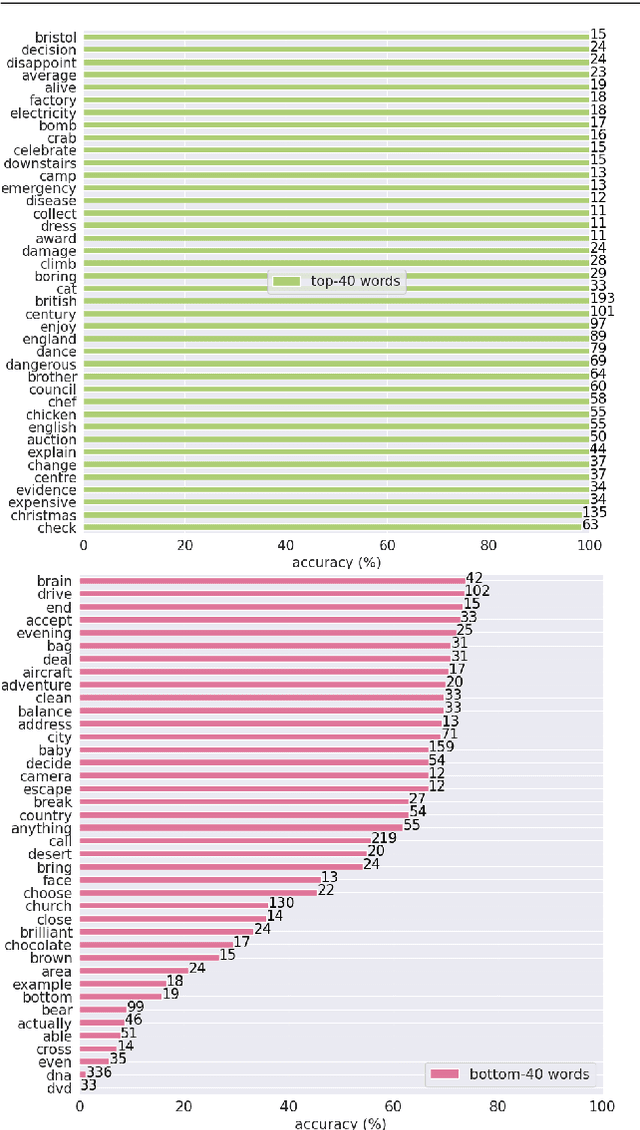
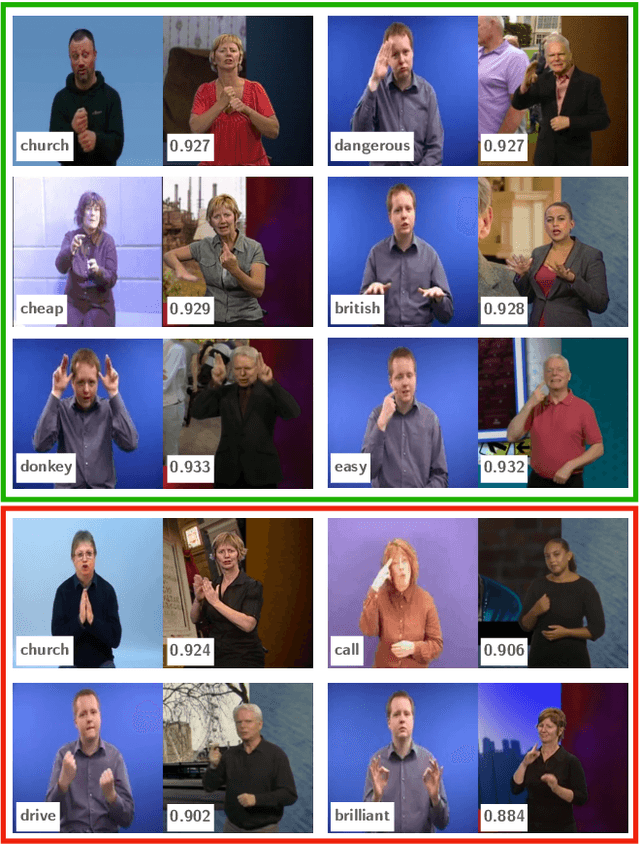
The focus of this work is $\textit{sign spotting}$ - given a video of an isolated sign, our task is to identify $\textit{whether}$ and $\textit{where}$ it has been signed in a continuous, co-articulated sign language video. To achieve this sign spotting task, we train a model using multiple types of available supervision by: (1) $\textit{watching}$ existing footage which is sparsely labelled using mouthing cues; (2) $\textit{reading}$ associated subtitles (readily available translations of the signed content) which provide additional $\textit{weak-supervision}$; (3) $\textit{looking up}$ words (for which no co-articulated labelled examples are available) in visual sign language dictionaries to enable novel sign spotting. These three tasks are integrated into a unified learning framework using the principles of Noise Contrastive Estimation and Multiple Instance Learning. We validate the effectiveness of our approach on low-shot sign spotting benchmarks. In addition, we contribute a machine-readable British Sign Language (BSL) dictionary dataset of isolated signs, BSLDict, to facilitate study of this task. The dataset, models and code are available at our project page.
* Appears in: 2022 International Journal of Computer Vision (IJCV). 25 pages. arXiv admin note: substantial text overlap with arXiv:2010.04002
A 23 MW data centre is all you need
Mar 31, 2022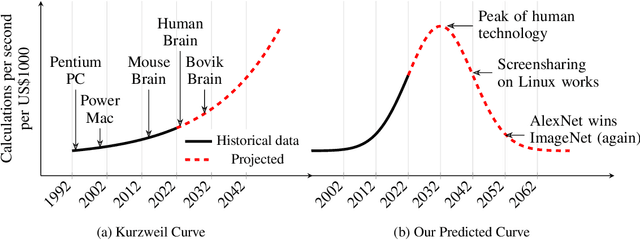
The field of machine learning has achieved striking progress in recent years, witnessing breakthrough results on language modelling, protein folding and nitpickingly fine-grained dog breed classification. Some even succeeded at playing computer games and board games, a feat both of engineering and of setting their employers' expectations. The central contribution of this work is to carefully examine whether this progress, and technology more broadly, can be expected to continue indefinitely. Through a rigorous application of statistical theory and failure to extrapolate beyond the training data, we answer firmly in the negative and provide details: technology will peak at 3:07 am (BST) on 20th July, 2032. We then explore the implications of this finding, discovering that individuals awake at this ungodly hour with access to a sufficiently powerful computer possess an opportunity for myriad forms of long-term linguistic 'lock in'. All we need is a large (>> 1W) data centre to seize this pivotal moment. By setting our analogue alarm clocks, we propose a tractable algorithm to ensure that, for the future of humanity, the British spelling of colour becomes the default spelling across more than 80% of the global word processing software market.
Unsupervised Salient Object Detection with Spectral Cluster Voting
Mar 23, 2022
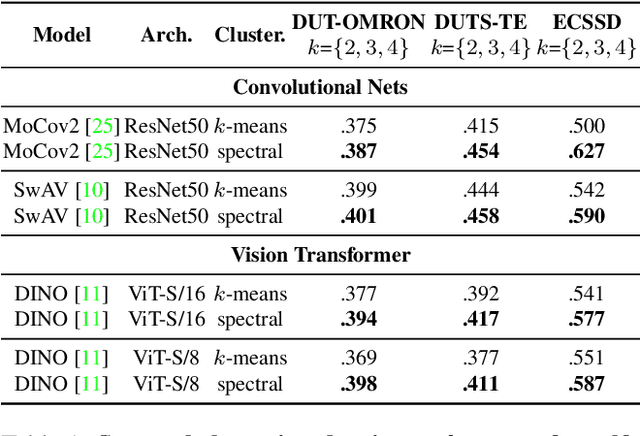
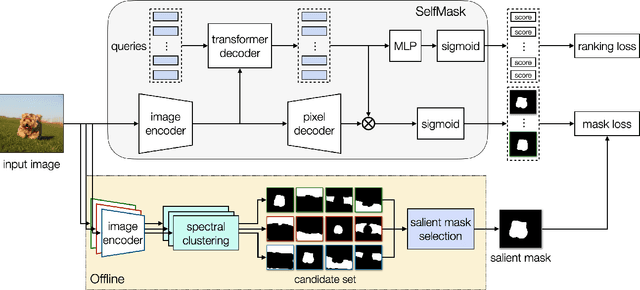
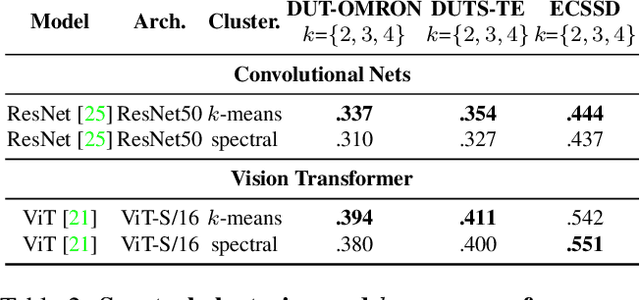
In this paper, we tackle the challenging task of unsupervised salient object detection (SOD) by leveraging spectral clustering on self-supervised features. We make the following contributions: (i) We revisit spectral clustering and demonstrate its potential to group the pixels of salient objects; (ii) Given mask proposals from multiple applications of spectral clustering on image features computed from various self-supervised models, e.g., MoCov2, SwAV, DINO, we propose a simple but effective winner-takes-all voting mechanism for selecting the salient masks, leveraging object priors based on framing and distinctiveness; (iii) Using the selected object segmentation as pseudo groundtruth masks, we train a salient object detector, dubbed SelfMask, which outperforms prior approaches on three unsupervised SOD benchmarks. Code is publicly available at https://github.com/NoelShin/selfmask.
Sign Language Video Retrieval with Free-Form Textual Queries
Jan 07, 2022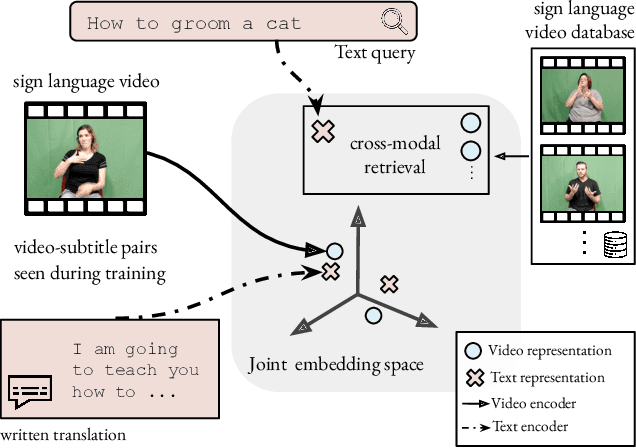
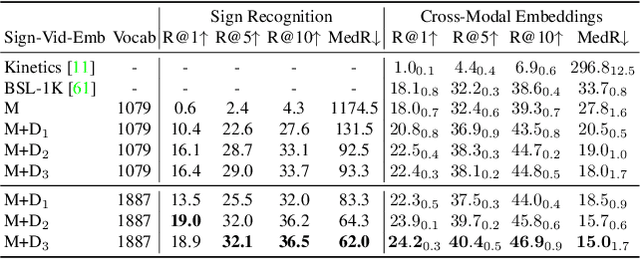
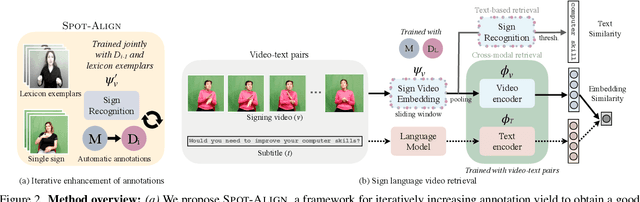

Systems that can efficiently search collections of sign language videos have been highlighted as a useful application of sign language technology. However, the problem of searching videos beyond individual keywords has received limited attention in the literature. To address this gap, in this work we introduce the task of sign language retrieval with free-form textual queries: given a written query (e.g., a sentence) and a large collection of sign language videos, the objective is to find the signing video in the collection that best matches the written query. We propose to tackle this task by learning cross-modal embeddings on the recently introduced large-scale How2Sign dataset of American Sign Language (ASL). We identify that a key bottleneck in the performance of the system is the quality of the sign video embedding which suffers from a scarcity of labeled training data. We, therefore, propose SPOT-ALIGN, a framework for interleaving iterative rounds of sign spotting and feature alignment to expand the scope and scale of available training data. We validate the effectiveness of SPOT-ALIGN for learning a robust sign video embedding through improvements in both sign recognition and the proposed video retrieval task.
Cross Modal Retrieval with Querybank Normalisation
Dec 23, 2021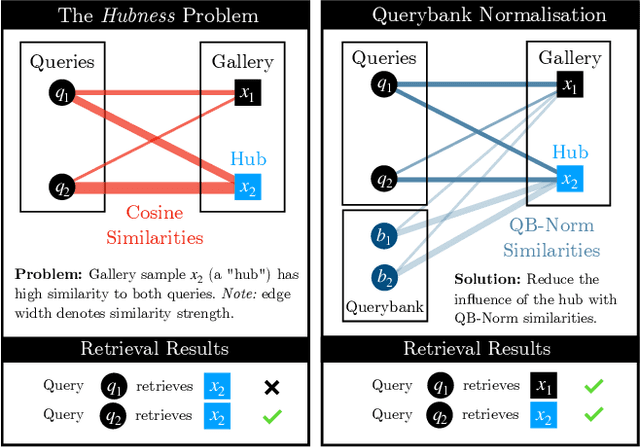

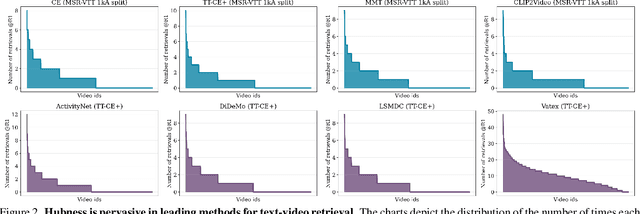
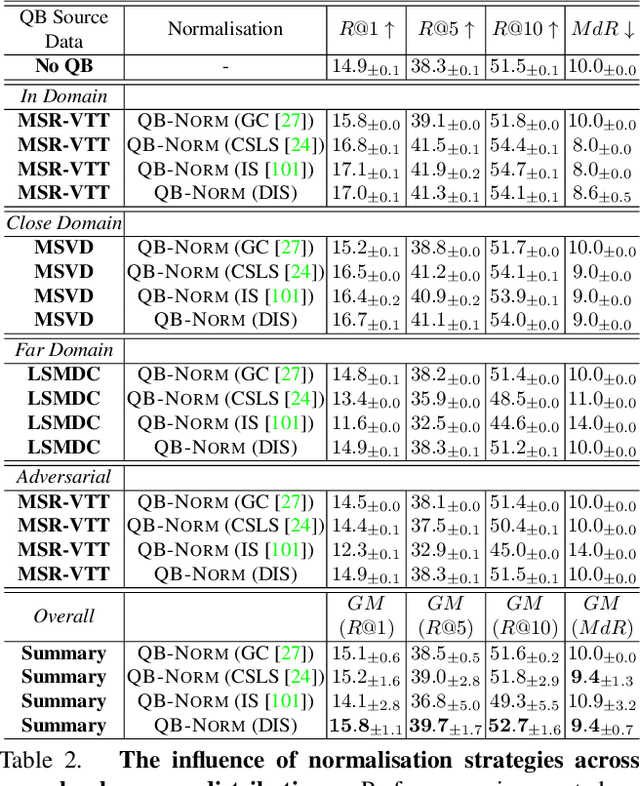
Profiting from large-scale training datasets, advances in neural architecture design and efficient inference, joint embeddings have become the dominant approach for tackling cross-modal retrieval. In this work we first show that, despite their effectiveness, state-of-the-art joint embeddings suffer significantly from the longstanding hubness problem in which a small number of gallery embeddings form the nearest neighbours of many queries. Drawing inspiration from the NLP literature, we formulate a simple but effective framework called Querybank Normalisation (QB-Norm) that re-normalises query similarities to account for hubs in the embedding space. QB-Norm improves retrieval performance without requiring retraining. Differently from prior work, we show that QB-Norm works effectively without concurrent access to any test set queries. Within the QB-Norm framework, we also propose a novel similarity normalisation method, the Dynamic Inverted Softmax, that is significantly more robust than existing approaches. We showcase QB-Norm across a range of cross modal retrieval models and benchmarks where it consistently enhances strong baselines beyond the state of the art. Code is available at https://vladbogo.github.io/QB-Norm/.
Audio Retrieval with Natural Language Queries: A Benchmark Study
Dec 17, 2021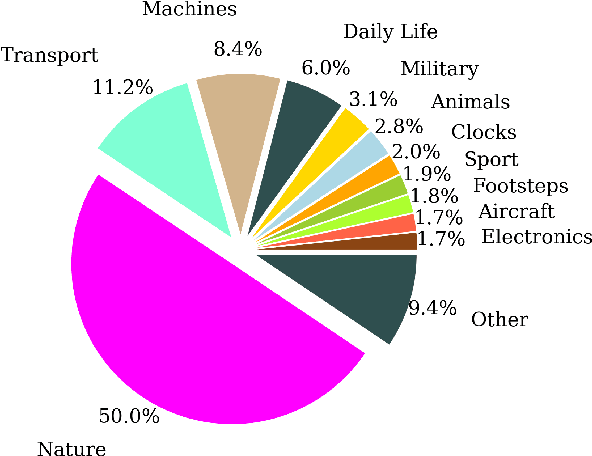
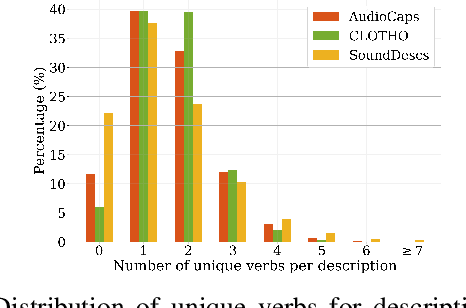
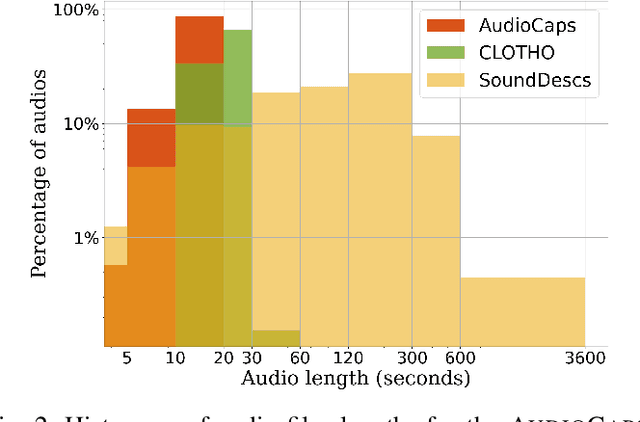
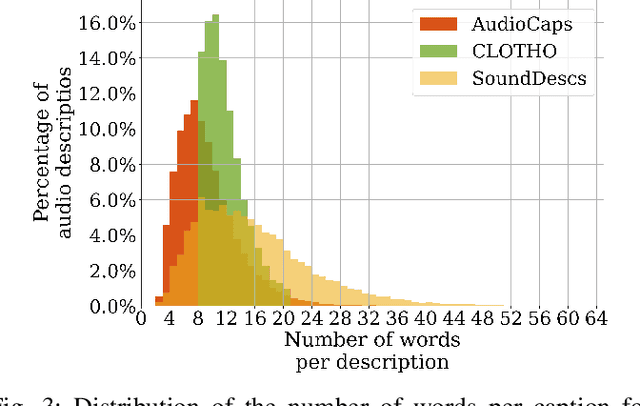
The objectives of this work are cross-modal text-audio and audio-text retrieval, in which the goal is to retrieve the audio content from a pool of candidates that best matches a given written description and vice versa. Text-audio retrieval enables users to search large databases through an intuitive interface: they simply issue free-form natural language descriptions of the sound they would like to hear. To study the tasks of text-audio and audio-text retrieval, which have received limited attention in the existing literature, we introduce three challenging new benchmarks. We first construct text-audio and audio-text retrieval benchmarks from the AudioCaps and Clotho audio captioning datasets. Additionally, we introduce the SoundDescs benchmark, which consists of paired audio and natural language descriptions for a diverse collection of sounds that are complementary to those found in AudioCaps and Clotho. We employ these three benchmarks to establish baselines for cross-modal text-audio and audio-text retrieval, where we demonstrate the benefits of pre-training on diverse audio tasks. We hope that our benchmarks will inspire further research into audio retrieval with free-form text queries. Code, audio features for all datasets used, and the \datasetName dataset will be made publicly available.
BBC-Oxford British Sign Language Dataset
Nov 05, 2021

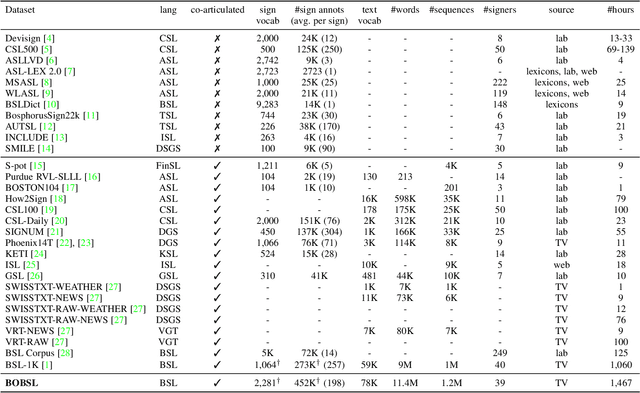
In this work, we introduce the BBC-Oxford British Sign Language (BOBSL) dataset, a large-scale video collection of British Sign Language (BSL). BOBSL is an extended and publicly released dataset based on the BSL-1K dataset introduced in previous work. We describe the motivation for the dataset, together with statistics and available annotations. We conduct experiments to provide baselines for the tasks of sign recognition, sign language alignment, and sign language translation. Finally, we describe several strengths and limitations of the data from the perspectives of machine learning and linguistics, note sources of bias present in the dataset, and discuss potential applications of BOBSL in the context of sign language technology. The dataset is available at https://www.robots.ox.ac.uk/~vgg/data/bobsl/.
Aligning Subtitles in Sign Language Videos
May 06, 2021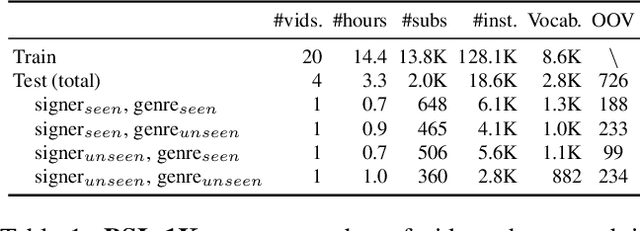
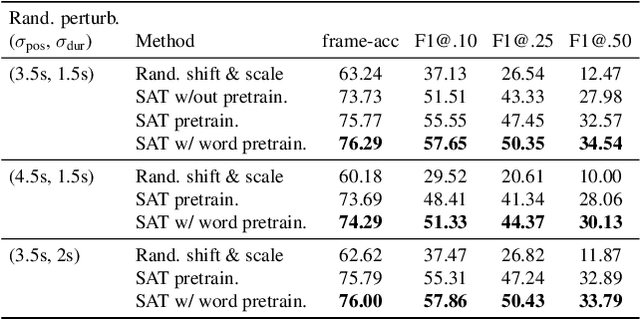
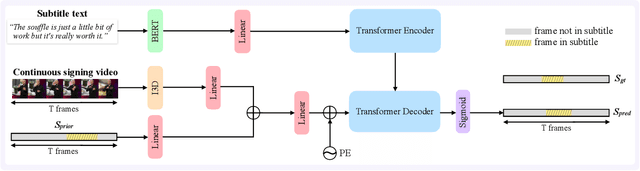
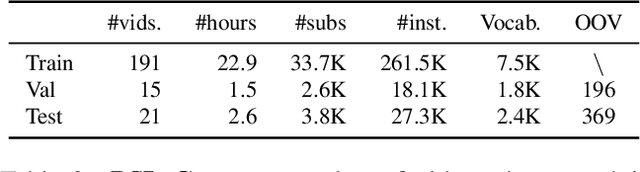
The goal of this work is to temporally align asynchronous subtitles in sign language videos. In particular, we focus on sign-language interpreted TV broadcast data comprising (i) a video of continuous signing, and (ii) subtitles corresponding to the audio content. Previous work exploiting such weakly-aligned data only considered finding keyword-sign correspondences, whereas we aim to localise a complete subtitle text in continuous signing. We propose a Transformer architecture tailored for this task, which we train on manually annotated alignments covering over 15K subtitles that span 17.7 hours of video. We use BERT subtitle embeddings and CNN video representations learned for sign recognition to encode the two signals, which interact through a series of attention layers. Our model outputs frame-level predictions, i.e., for each video frame, whether it belongs to the queried subtitle or not. Through extensive evaluations, we show substantial improvements over existing alignment baselines that do not make use of subtitle text embeddings for learning. Our automatic alignment model opens up possibilities for advancing machine translation of sign languages via providing continuously synchronized video-text data.