 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Speech Embeddings using Cross-modal Self-supervision
Paper and Code
Feb 20, 2020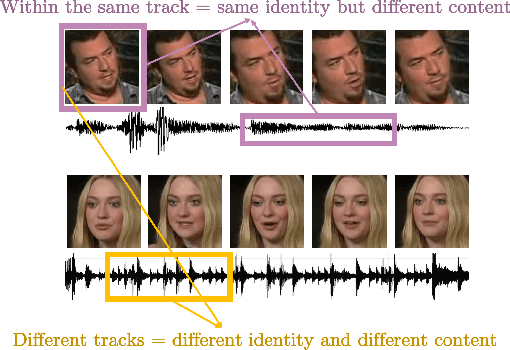
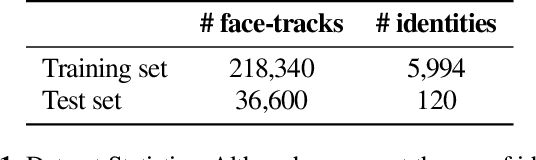
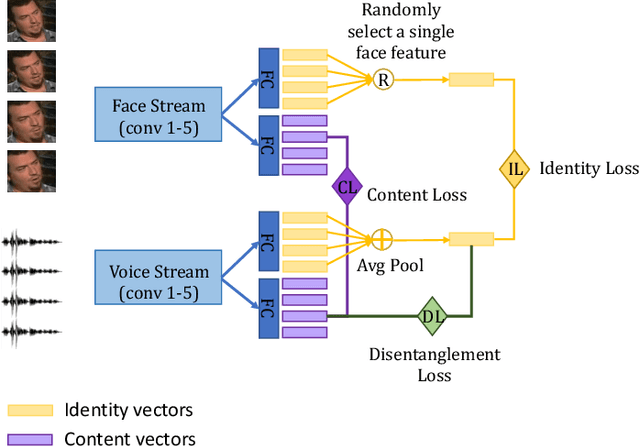
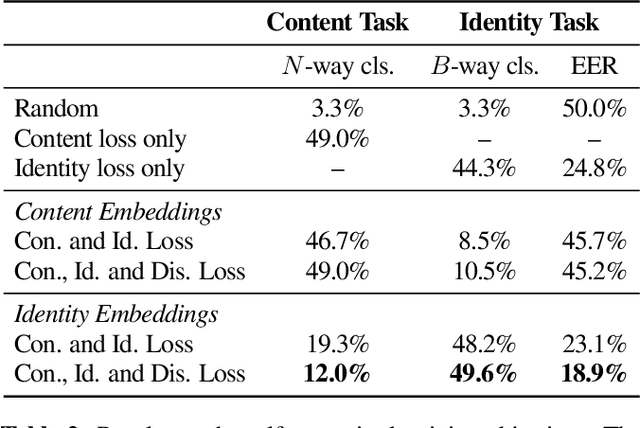
The objective of this paper is to learn representations of speaker identity without access to manually annotated data. To do so, we develop a self-supervised learning objective that exploits the natural cross-modal synchrony between faces and audio in video. The key idea behind our approach is to tease apart---without annotation---the representations of linguistic content and speaker identity. We construct a two-stream architecture which: (1) shares low-level features common to both representations; and (2) provides a natural mechanism for explicitly disentangling these factors, offering the potential for greater generalisation to novel combinations of content and identity and ultimately producing speaker identity representations that are more robust. We train our method on a large-scale audio-visual dataset of talking heads `in the wild', and demonstrate its efficacy by evaluating the learned speaker representations for standard speaker recognition performance.