 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
BBC-Oxford British Sign Language Dataset
Nov 05, 2021

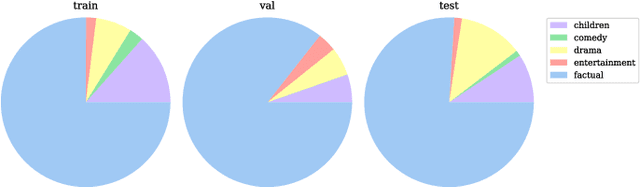
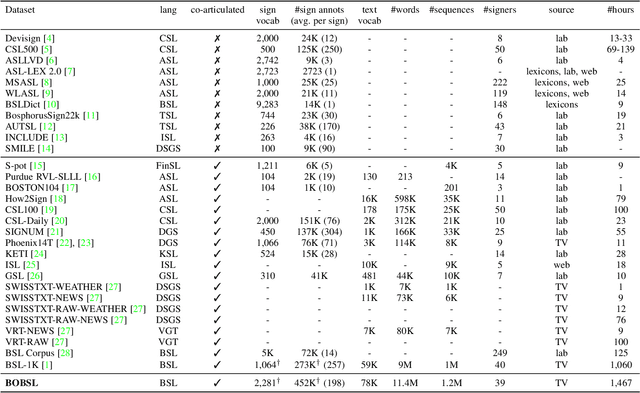
In this work, we introduce the BBC-Oxford British Sign Language (BOBSL) dataset, a large-scale video collection of British Sign Language (BSL). BOBSL is an extended and publicly released dataset based on the BSL-1K dataset introduced in previous work. We describe the motivation for the dataset, together with statistics and available annotations. We conduct experiments to provide baselines for the tasks of sign recognition, sign language alignment, and sign language translation. Finally, we describe several strengths and limitations of the data from the perspectives of machine learning and linguistics, note sources of bias present in the dataset, and discuss potential applications of BOBSL in the context of sign language technology. The dataset is available at https://www.robots.ox.ac.uk/~vgg/data/bobsl/.
Sign Segmentation with Changepoint-Modulated Pseudo-Labelling
Apr 28, 2021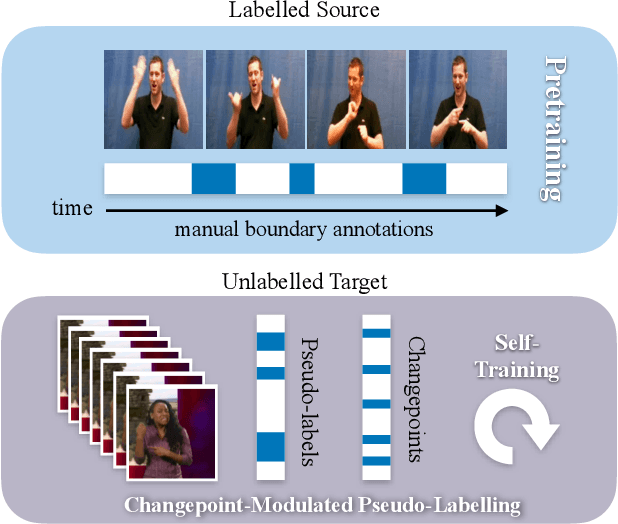
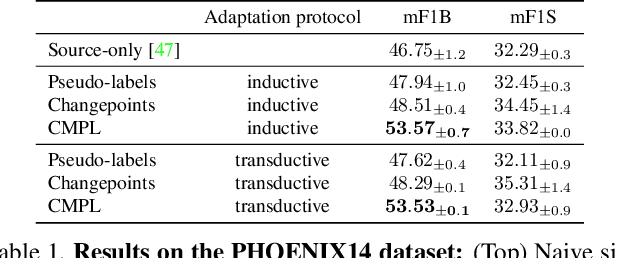
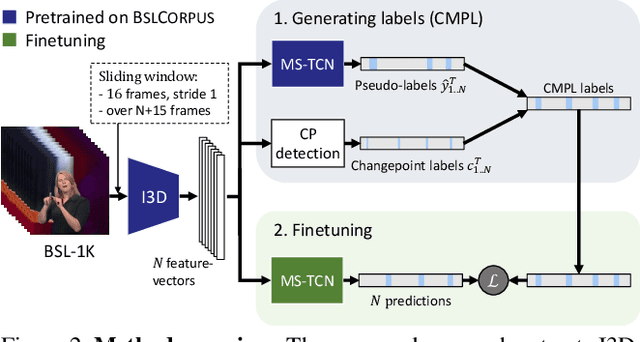

The objective of this work is to find temporal boundaries between signs in continuous sign language. Motivated by the paucity of annotation available for this task, we propose a simple yet effective algorithm to improve segmentation performance on unlabelled signing footage from a domain of interest. We make the following contributions: (1) We motivate and introduce the task of source-free domain adaptation for sign language segmentation, in which labelled source data is available for an initial training phase, but is not available during adaptation. (2) We propose the Changepoint-Modulated Pseudo-Labelling (CMPL) algorithm to leverage cues from abrupt changes in motion-sensitive feature space to improve pseudo-labelling quality for adaptation. (3) We showcase the effectiveness of our approach for category-agnostic sign segmentation, transferring from the BSLCORPUS to the BSL-1K and RWTH-PHOENIX-Weather 2014 datasets, where we outperform the prior state of the art.
BSL-1K: Scaling up co-articulated sign language recognition using mouthing cues
Jul 23, 2020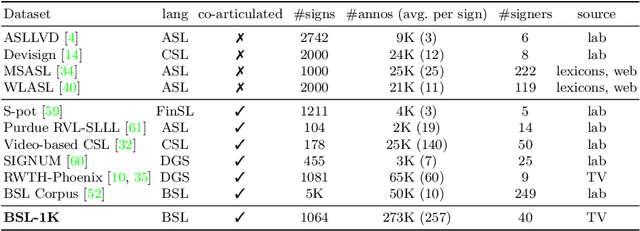

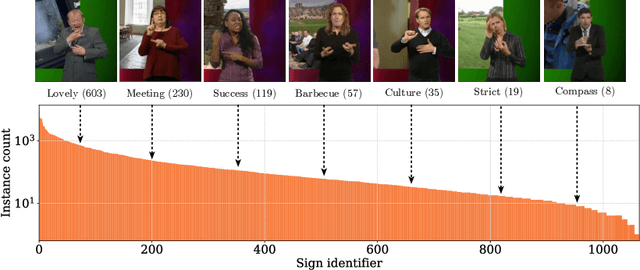

Recent progress in fine-grained gesture and action classification, and machine translation, point to the possibility of automated sign language recognition becoming a reality. A key stumbling block in making progress towards this goal is a lack of appropriate training data, stemming from the high complexity of sign annotation and a limited supply of qualified annotators. In this work, we introduce a new scalable approach to data collection for sign recognition in continuous videos. We make use of weakly-aligned subtitles for broadcast footage together with a keyword spotting method to automatically localise sign-instances for a vocabulary of 1,000 signs in 1,000 hours of video. We make the following contributions: (1) We show how to use mouthing cues from signers to obtain high-quality annotations from video data - the result is the BSL-1K dataset, a collection of British Sign Language (BSL) signs of unprecedented scale; (2) We show that we can use BSL-1K to train strong sign recognition models for co-articulated signs in BSL and that these models additionally form excellent pretraining for other sign languages and benchmarks - we exceed the state of the art on both the MSASL and WLASL benchmarks. Finally, (3) we propose new large-scale evaluation sets for the tasks of sign recognition and sign spotting and provide baselines which we hope will serve to stimulate research in this area.