 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen do Contrastive Word Alignments Improve Many-to-many Neural Machine Translation?
Apr 26, 2022



Word alignment has proven to benefit many-to-many neural machine translation (NMT). However, high-quality ground-truth bilingual dictionaries were used for pre-editing in previous methods, which are unavailable for most language pairs. Meanwhile, the contrastive objective can implicitly utilize automatically learned word alignment, which has not been explored in many-to-many NMT. This work proposes a word-level contrastive objective to leverage word alignments for many-to-many NMT. Empirical results show that this leads to 0.8 BLEU gains for several language pairs. Analyses reveal that in many-to-many NMT, the encoder's sentence retrieval performance highly correlates with the translation quality, which explains when the proposed method impacts translation. This motivates future exploration for many-to-many NMT to improve the encoder's sentence retrieval performance.
Hierarchical Softmax for End-to-End Low-resource Multilingual Speech Recognition
Apr 08, 2022
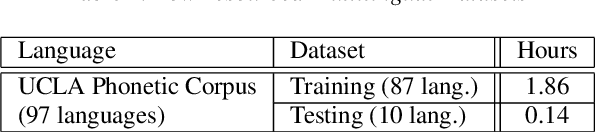
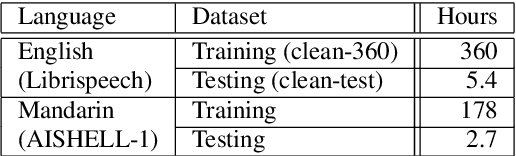
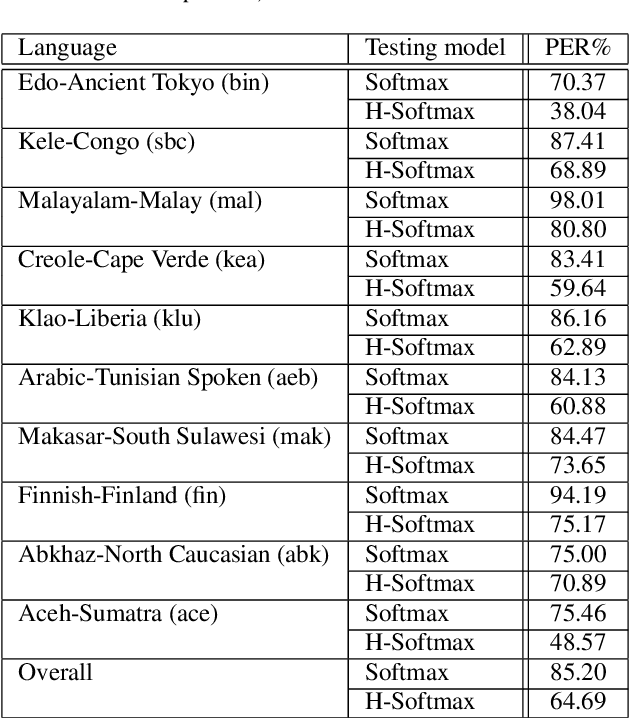
Low resource speech recognition has been long-suffering from insufficient training data. While neighbour languages are often used as assistant training data, it would be difficult for the model to induct similar units (character, subword, etc.) across the languages. In this paper, we assume similar units in neighbour language share similar term frequency and form a Huffman tree to perform multi-lingual hierarchical Softmax decoding. During decoding, the hierarchical structure can benefit the training of low-resource languages. Experimental results show the effectiveness of our method.
VISA: An Ambiguous Subtitles Dataset for Visual Scene-Aware Machine Translation
Jan 21, 2022

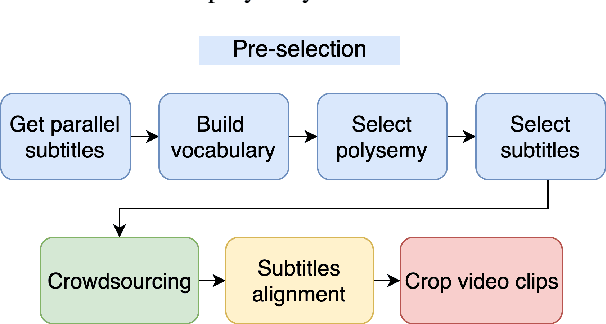
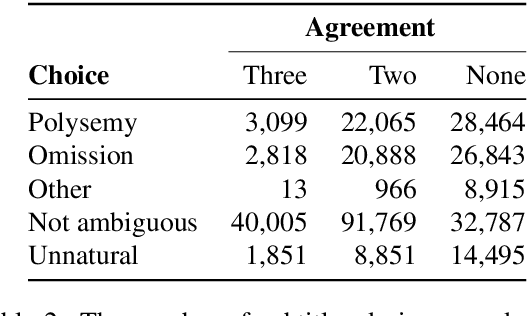
Existing multimodal machine translation (MMT) datasets consist of images and video captions or general subtitles, which rarely contain linguistic ambiguity, making visual information not so effective to generate appropriate translations. We introduce VISA, a new dataset that consists of 40k Japanese-English parallel sentence pairs and corresponding video clips with the following key features: (1) the parallel sentences are subtitles from movies and TV episodes; (2) the source subtitles are ambiguous, which means they have multiple possible translations with different meanings; (3) we divide the dataset into Polysemy and Omission according to the cause of ambiguity. We show that VISA is challenging for the latest MMT system, and we hope that the dataset can facilitate MMT research.
Linguistically-driven Multi-task Pre-training for Low-resource Neural Machine Translation
Jan 20, 2022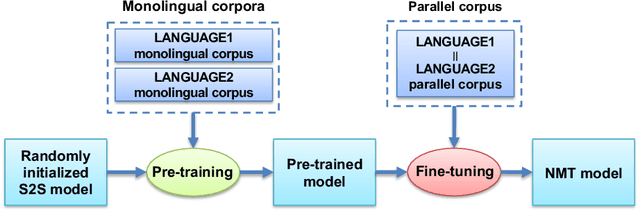
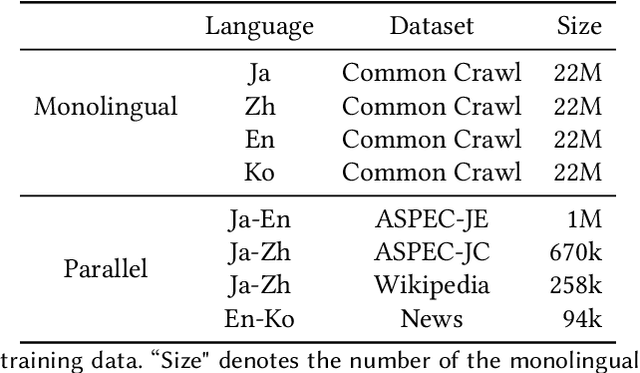


In the present study, we propose novel sequence-to-sequence pre-training objectives for low-resource machine translation (NMT): Japanese-specific sequence to sequence (JASS) for language pairs involving Japanese as the source or target language, and English-specific sequence to sequence (ENSS) for language pairs involving English. JASS focuses on masking and reordering Japanese linguistic units known as bunsetsu, whereas ENSS is proposed based on phrase structure masking and reordering tasks. Experiments on ASPEC Japanese--English & Japanese--Chinese, Wikipedia Japanese--Chinese, News English--Korean corpora demonstrate that JASS and ENSS outperform MASS and other existing language-agnostic pre-training methods by up to +2.9 BLEU points for the Japanese--English tasks, up to +7.0 BLEU points for the Japanese--Chinese tasks and up to +1.3 BLEU points for English--Korean tasks. Empirical analysis, which focuses on the relationship between individual parts in JASS and ENSS, reveals the complementary nature of the subtasks of JASS and ENSS. Adequacy evaluation using LASER, human evaluation, and case studies reveals that our proposed methods significantly outperform pre-training methods without injected linguistic knowledge and they have a larger positive impact on the adequacy as compared to the fluency. We release codes here: https://github.com/Mao-KU/JASS/tree/master/linguistically-driven-pretraining.
* An extension of work arXiv:2005.03361
Cross-lingual Adaption Model-Agnostic Meta-Learning for Natural Language Understanding
Nov 10, 2021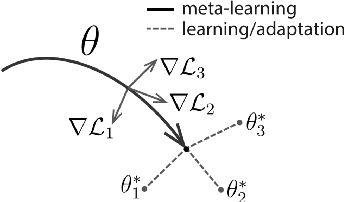
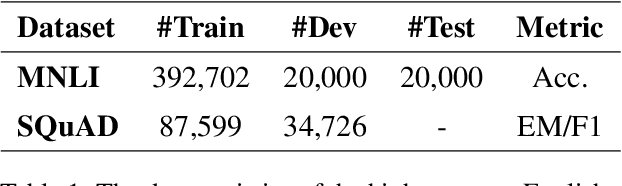
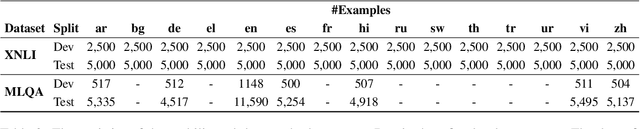
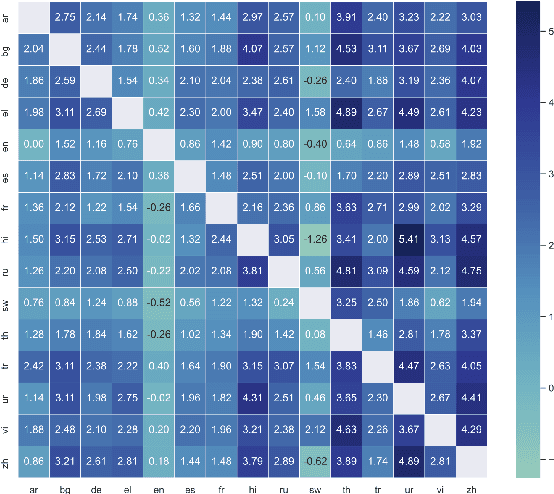
Meta learning with auxiliary languages has demonstrated promising improvements for cross-lingual natural language processing. However, previous studies sample the meta-training and meta-testing data from the same language, which limits the ability of the model for cross-lingual transfer. In this paper, we propose XLA-MAML, which performs direct cross-lingual adaption in the meta-learning stage. We conduct zero-shot and few-shot experiments on Natural Language Inference and Question Answering. The experimental results demonstrate the effectiveness of our method across different languages, tasks, and pretrained models. We also give analysis on various cross-lingual specific settings for meta-learning including sampling strategy and parallelism.
JaMIE: A Pipeline Japanese Medical Information Extraction System
Nov 08, 2021
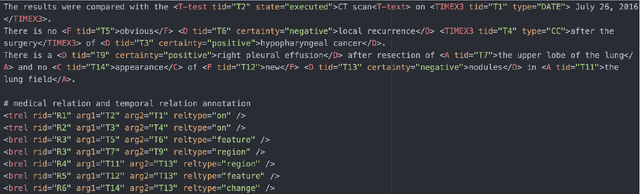
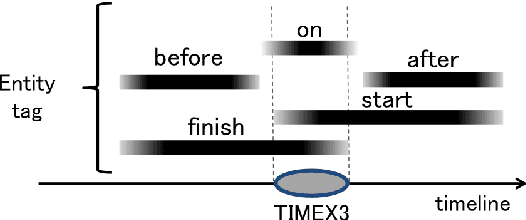
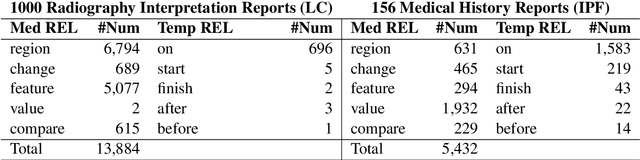
We present an open-access natural language processing toolkit for Japanese medical information extraction. We first propose a novel relation annotation schema for investigating the medical and temporal relations between medical entities in Japanese medical reports. We experiment with the practical annotation scenarios by separately annotating two different types of reports. We design a pipeline system with three components for recognizing medical entities, classifying entity modalities, and extracting relations. The empirical results show accurate analyzing performance and suggest the satisfactory annotation quality, the effective annotation strategy for targeting report types, and the superiority of the latest contextual embedding models.
Lightweight Cross-Lingual Sentence Representation Learning
Jun 12, 2021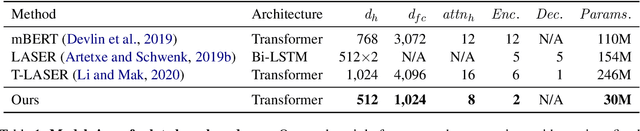
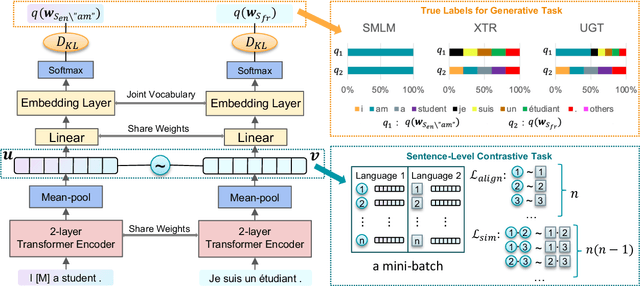
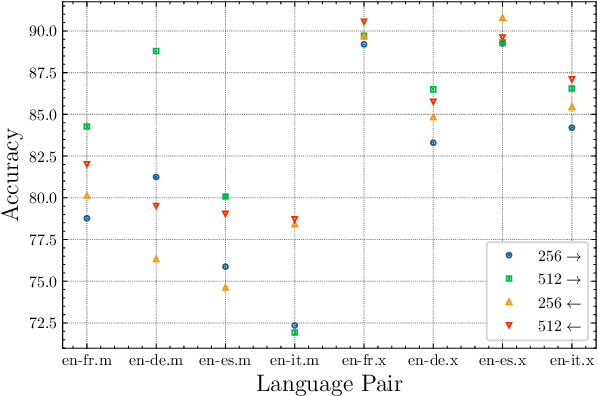
Large-scale models for learning fixed-dimensional cross-lingual sentence representations like LASER (Artetxe and Schwenk, 2019b) lead to significant improvement in performance on downstream tasks. However, further increases and modifications based on such large-scale models are usually impractical due to memory limitations. In this work, we introduce a lightweight dual-transformer architecture with just 2 layers for generating memory-efficient cross-lingual sentence representations. We explore different training tasks and observe that current cross-lingual training tasks leave a lot to be desired for this shallow architecture. To ameliorate this, we propose a novel cross-lingual language model, which combines the existing single-word masked language model with the newly proposed cross-lingual token-level reconstruction task. We further augment the training task by the introduction of two computationally-lite sentence-level contrastive learning tasks to enhance the alignment of cross-lingual sentence representation space, which compensates for the learning bottleneck of the lightweight transformer for generative tasks. Our comparisons with competing models on cross-lingual sentence retrieval and multilingual document classification confirm the effectiveness of the newly proposed training tasks for a shallow model.
Frustratingly Easy Edit-based Linguistic Steganography with a Masked Language Model
Apr 20, 2021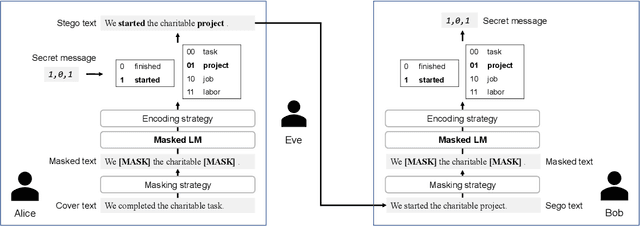

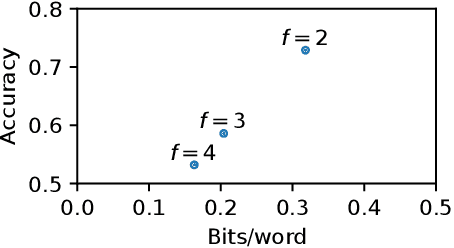
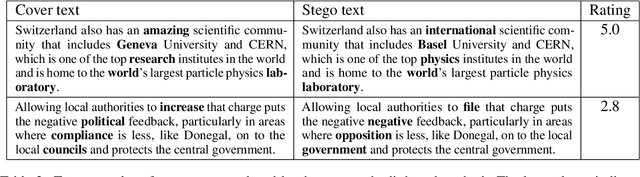
With advances in neural language models, the focus of linguistic steganography has shifted from edit-based approaches to generation-based ones. While the latter's payload capacity is impressive, generating genuine-looking texts remains challenging. In this paper, we revisit edit-based linguistic steganography, with the idea that a masked language model offers an off-the-shelf solution. The proposed method eliminates painstaking rule construction and has a high payload capacity for an edit-based model. It is also shown to be more secure against automatic detection than a generation-based method while offering better control of the security/payload capacity trade-off.
Modeling and Utilizing User's Internal State in Movie Recommendation Dialogue
Dec 05, 2020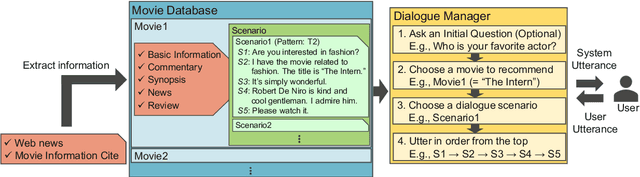



Intelligent dialogue systems are expected as a new interface between humans and machines. Such an intelligent dialogue system should estimate the user's internal state (UIS) in dialogues and change its response appropriately according to the estimation result. In this paper, we model the UIS in dialogues, taking movie recommendation dialogues as examples, and construct a dialogue system that changes its response based on the UIS. Based on the dialogue data analysis, we model the UIS as three elements: knowledge, interest, and engagement. We train the UIS estimators on a dialogue corpus with the modeled UIS's annotations. The estimators achieved high estimation accuracy. We also design response change rules that change the system's responses according to each UIS. We confirmed that response changes using the result of the UIS estimators improved the system utterances' naturalness in both dialogue-wise evaluation and utterance-wise evaluation.
Minimize Exposure Bias of Seq2Seq Models in Joint Entity and Relation Extraction
Oct 06, 2020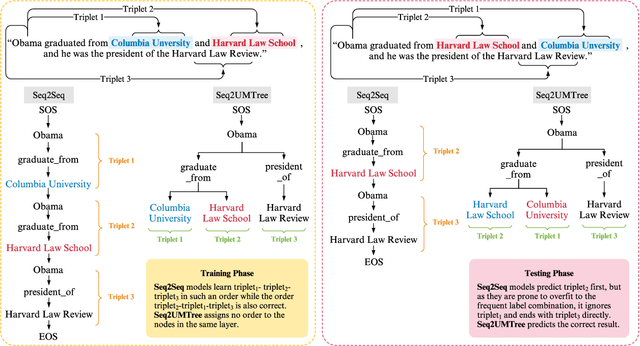
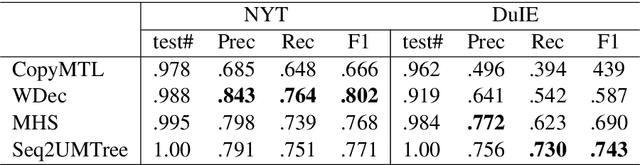
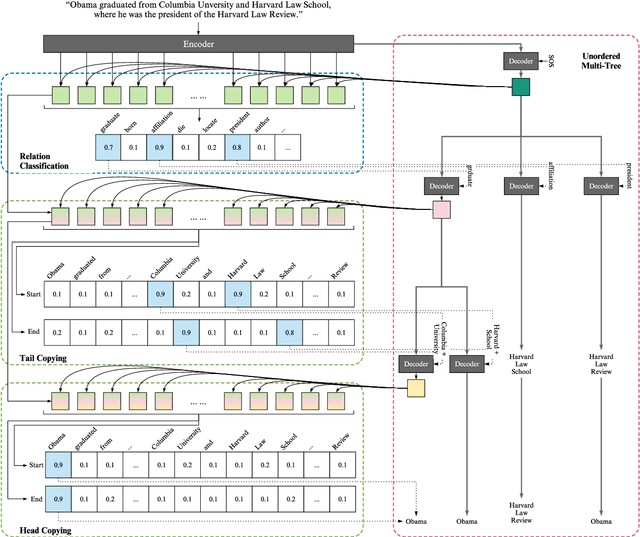
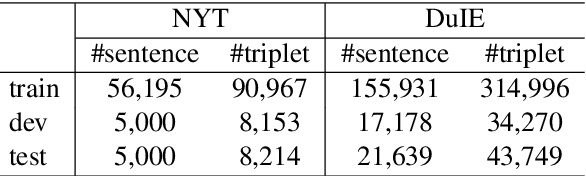
Joint entity and relation extraction aims to extract relation triplets from plain text directly. Prior work leverages Sequence-to-Sequence (Seq2Seq) models for triplet sequence generation. However, Seq2Seq enforces an unnecessary order on the unordered triplets and involves a large decoding length associated with error accumulation. These introduce exposure bias, which may cause the models overfit to the frequent label combination, thus deteriorating the generalization. We propose a novel Sequence-to-Unordered-Multi-Tree (Seq2UMTree) model to minimize the effects of exposure bias by limiting the decoding length to three within a triplet and removing the order among triplets. We evaluate our model on two datasets, DuIE and NYT, and systematically study how exposure bias alters the performance of Seq2Seq models. Experiments show that the state-of-the-art Seq2Seq model overfits to both datasets while Seq2UMTree shows significantly better generalization. Our code is available at https://github.com/WindChimeRan/OpenJERE .