 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExCAM: Explainable Cultural Awareness Metrics
May 28, 2026Evaluating the cultural awareness of large language models is crucial to ensure the fairness of generated text and the generalizability of applications across the world. Recent benchmarks explore cultural goods like food or values like behavior in stressful situations through the lens of question answering or text generation tasks. However, creating these benchmarks requires time-intensive and costly human annotations. Also, benchmarks that evaluate cultural awareness in free text are scarce and often rely on dated evaluation mechanisms. To address this gap, we introduce ExCAM, an Explainable Cultural Awareness Metric, which is, to our knowledge, the first dedicated evaluation metric that identifies, rates and explains cultural errors in instruction-output pairs. To train and evaluate ExCAM, we introduce ExCAM40k, a dataset comprised of nine existing benchmarks that we reformat and enhance with synthetic errors. Compared to several baselines, including GPT-5, ExCAM achieves the highest error detection rate with up to 80% accuracy on a balanced test set. Therefore, ExCAM opens the pathway towards fine-grained and explainable cultural evaluation of free text.
OptiMer: Optimal Distribution Vector Merging Is Better than Data Mixing for Continual Pre-Training
Mar 30, 2026Continual pre-training is widely used to adapt LLMs to target languages and domains, yet the mixture ratio of training data remains a sensitive hyperparameter that is expensive to tune: they must be fixed before training begins, and a suboptimal choice can waste weeks of compute. In this work, we propose OptiMer, which decouples ratio selection from training: we train one CPT model per dataset, extract each model's distribution vector, which represents the parameter shift induced by that dataset, and search for optimal composition weights post-hoc via Bayesian optimization. Experiments on Gemma 3 27B across languages (Japanese, Chinese) and domains (Math, Code) show that OptiMer consistently outperforms data mixture and model averaging baselines with 15-35 times lower search cost. Key findings reveal that 1) the optimized weights can be interpreted as data mixture ratios, and retraining with these ratios improves data mixture CPT, and 2) the same vector pool can be re-optimized for a given objective without any retraining, producing target-tailored models on demand. Our work establishes that data mixture ratio selection, traditionally a pre-training decision, can be reformulated as a post-hoc optimization over distribution vectors, offering a more flexible paradigm for continual pre-training.
Is Human Annotation Necessary? Iterative MBR Distillation for Error Span Detection in Machine Translation
Mar 16, 2026Error Span Detection (ESD) is a crucial subtask in Machine Translation (MT) evaluation, aiming to identify the location and severity of translation errors. While fine-tuning models on human-annotated data improves ESD performance, acquiring such data is expensive and prone to inconsistencies among annotators. To address this, we propose a novel self-evolution framework based on Minimum Bayes Risk (MBR) decoding, named Iterative MBR Distillation for ESD, which eliminates the reliance on human annotations by leveraging an off-the-shelf LLM to generate pseudo-labels. Extensive experiments on the WMT Metrics Shared Task datasets demonstrate that models trained solely on these self-generated pseudo-labels outperform both unadapted base model and supervised baselines trained on human annotations at the system and span levels, while maintaining competitive sentence-level performance.
Minimum Bayes Risk Decoding for Error Span Detection in Reference-Free Automatic Machine Translation Evaluation
Dec 19, 2025



Error Span Detection (ESD) extends automatic machine translation (MT) evaluation by localizing translation errors and labeling their severity. Current generative ESD methods typically use Maximum a Posteriori (MAP) decoding, assuming that the model-estimated probabilities are perfectly correlated with similarity to the human annotation, but we often observe higher likelihood assigned to an incorrect annotation than to the human one. We instead apply Minimum Bayes Risk (MBR) decoding to generative ESD. We use a sentence- or span-level similarity function for MBR decoding, which selects candidate hypotheses based on their approximate similarity to the human annotation. Experimental results on the WMT24 Metrics Shared Task show that MBR decoding significantly improves span-level performance and generally matches or outperforms MAP at the system and sentence levels. To reduce the computational cost of MBR decoding, we further distill its decisions into a model decoded via greedy search, removing the inference-time latency bottleneck.
PrahokBART: A Pre-trained Sequence-to-Sequence Model for Khmer Natural Language Generation
Dec 15, 2025This work introduces {\it PrahokBART}, a compact pre-trained sequence-to-sequence model trained from scratch for Khmer using carefully curated Khmer and English corpora. We focus on improving the pre-training corpus quality and addressing the linguistic issues of Khmer, which are ignored in existing multilingual models, by incorporating linguistic components such as word segmentation and normalization. We evaluate PrahokBART on three generative tasks: machine translation, text summarization, and headline generation, where our results demonstrate that it outperforms mBART50, a strong multilingual pre-trained model. Additionally, our analysis provides insights into the impact of each linguistic module and evaluates how effectively our model handles space during text generation, which is crucial for the naturalness of texts in Khmer.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025
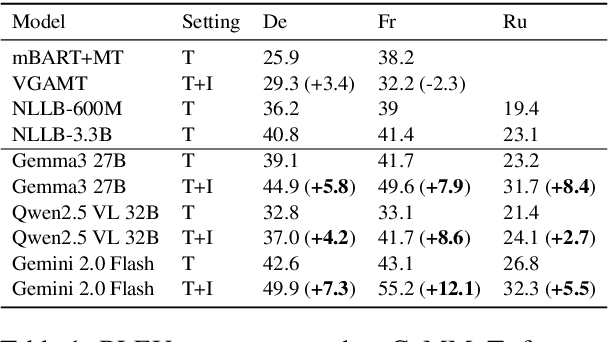

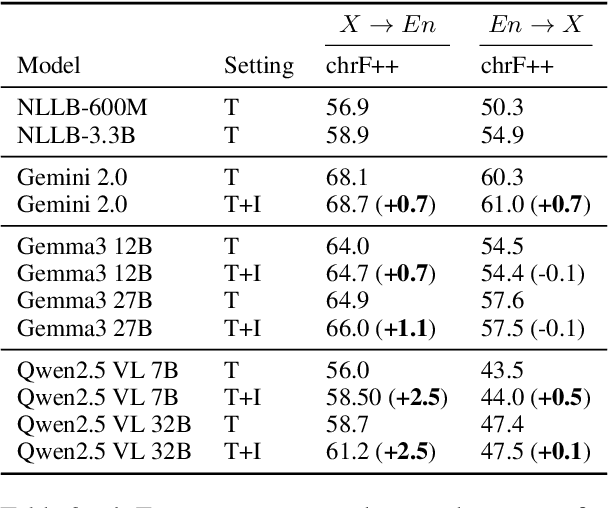
Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
IteRABRe: Iterative Recovery-Aided Block Reduction
Mar 08, 2025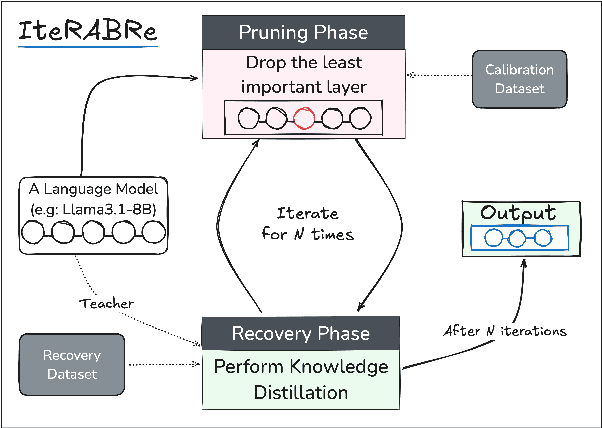
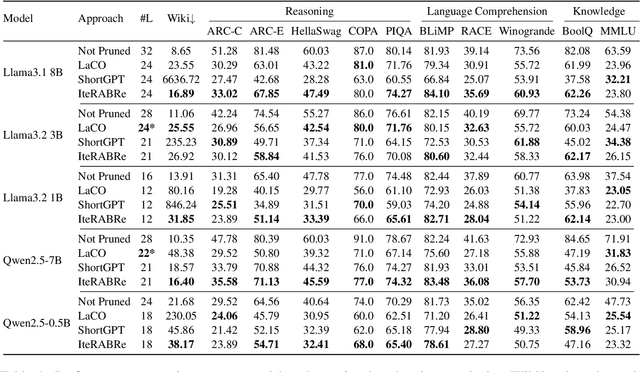
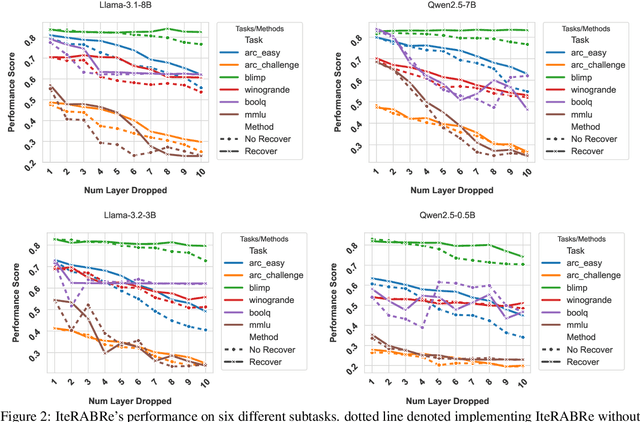
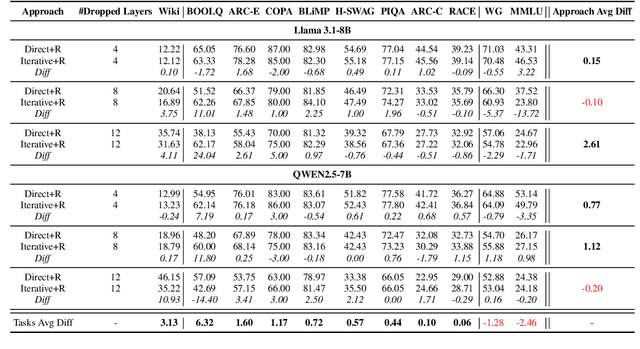
Large Language Models (LLMs) have grown increasingly expensive to deploy, driving the need for effective model compression techniques. While block pruning offers a straightforward approach to reducing model size, existing methods often struggle to maintain performance or require substantial computational resources for recovery. We present IteRABRe, a simple yet effective iterative pruning method that achieves superior compression results while requiring minimal computational resources. Using only 2.5M tokens for recovery, our method outperforms baseline approaches by ~3% on average when compressing the Llama3.1-8B and Qwen2.5-7B models. IteRABRe demonstrates particular strength in the preservation of linguistic capabilities, showing an improvement 5% over the baselines in language-related tasks. Our analysis reveals distinct pruning characteristics between these models, while also demonstrating preservation of multilingual capabilities.
Pralekha: An Indic Document Alignment Evaluation Benchmark
Nov 28, 2024



Mining parallel document pairs poses a significant challenge because existing sentence embedding models often have limited context windows, preventing them from effectively capturing document-level information. Another overlooked issue is the lack of concrete evaluation benchmarks comprising high-quality parallel document pairs for assessing document-level mining approaches, particularly for Indic languages. In this study, we introduce Pralekha, a large-scale benchmark for document-level alignment evaluation. Pralekha includes over 2 million documents, with a 1:2 ratio of unaligned to aligned pairs, covering 11 Indic languages and English. Using Pralekha, we evaluate various document-level mining approaches across three dimensions: the embedding models, the granularity levels, and the alignment algorithm. To address the challenge of aligning documents using sentence and chunk-level alignments, we propose a novel scoring method, Document Alignment Coefficient (DAC). DAC demonstrates substantial improvements over baseline pooling approaches, particularly in noisy scenarios, achieving average gains of 20-30% in precision and 15-20% in F1 score. These results highlight DAC's effectiveness in parallel document mining for Indic languages.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Enhancing Personality Recognition in Dialogue by Data Augmentation and Heterogeneous Conversational Graph Networks
Jan 11, 2024



Personality recognition is useful for enhancing robots' ability to tailor user-adaptive responses, thus fostering rich human-robot interactions. One of the challenges in this task is a limited number of speakers in existing dialogue corpora, which hampers the development of robust, speaker-independent personality recognition models. Additionally, accurately modeling both the interdependencies among interlocutors and the intra-dependencies within the speaker in dialogues remains a significant issue. To address the first challenge, we introduce personality trait interpolation for speaker data augmentation. For the second, we propose heterogeneous conversational graph networks to independently capture both contextual influences and inherent personality traits. Evaluations on the RealPersonaChat corpus demonstrate our method's significant improvements over existing baselines.