 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJASS: Japanese-specific Sequence to Sequence Pre-training for Neural Machine Translation
Paper and Code

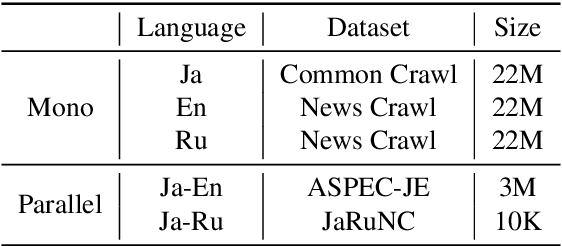

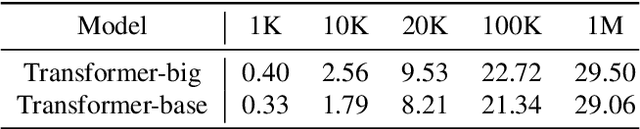
Neural machine translation (NMT) needs large parallel corpora for state-of-the-art translation quality. Low-resource NMT is typically addressed by transfer learning which leverages large monolingual or parallel corpora for pre-training. Monolingual pre-training approaches such as MASS (MAsked Sequence to Sequence) are extremely effective in boosting NMT quality for languages with small parallel corpora. However, they do not account for linguistic information obtained using syntactic analyzers which is known to be invaluable for several Natural Language Processing (NLP) tasks. To this end, we propose JASS, Japanese-specific Sequence to Sequence, as a novel pre-training alternative to MASS for NMT involving Japanese as the source or target language. JASS is joint BMASS (Bunsetsu MASS) and BRSS (Bunsetsu Reordering Sequence to Sequence) pre-training which focuses on Japanese linguistic units called bunsetsus. In our experiments on ASPEC Japanese--English and News Commentary Japanese--Russian translation we show that JASS can give results that are competitive with if not better than those given by MASS. Furthermore, we show for the first time that joint MASS and JASS pre-training gives results that significantly surpass the individual methods indicating their complementary nature. We will release our code, pre-trained models and bunsetsu annotated data as resources for researchers to use in their own NLP tasks.