 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Question-Answer Dataset for LLM Safety Evaluation with a Focus on Illegal Activities
May 28, 2026In this paper, we discuss question-answer dataset for LLM safety evaluation, with a focus on illegal activities. Specifically, on the basis of manual analysis of AnswerCarefully, we introduce several additional information, methods for creating question-answer examples, and a rubric for evaluating LLM-generated responses. The outcomes of this study are intended to be shared with the "JAI-Trust" project.
ATD-Trans: A Geographically Grounded Japanese-English Travelogue Translation Dataset
May 13, 2026Geographic text, or textual data rich in geographic (geo-) information is a valuable source for various geographic applications, e.g., tourism management. Making such information accessible to speakers of other languages further enhances its utility; thus, accurate machine translation (MT) is essential for equity in multilingual geo-information access. To facilitate in-depth analysis for geographic text, we introduce ATD-Trans, a geographically grounded Japanese--English travelogue translation dataset, which enables evaluation of MT quality at both the overall and geo-entity levels across domestic (within Japan) and overseas regions. Our experiments on existing language models examine two factors: model language focus and geographic regions. The results highlight advantages of Japanese-enhanced models and greater difficulty in translating domestic-region geo-entities mentioned in travel blogs.
The Uneven Impact of Post-Training Quantization in Machine Translation
Aug 28, 2025Quantization is essential for deploying large language models (LLMs) on resource-constrained hardware, but its implications for multilingual tasks remain underexplored. We conduct the first large-scale evaluation of post-training quantization (PTQ) on machine translation across 55 languages using five LLMs ranging from 1.7B to 70B parameters. Our analysis reveals that while 4-bit quantization often preserves translation quality for high-resource languages and large models, significant degradation occurs for low-resource and typologically diverse languages, particularly in 2-bit settings. We compare four quantization techniques (AWQ, BitsAndBytes, GGUF, and AutoRound), showing that algorithm choice and model size jointly determine robustness. GGUF variants provide the most consistent performance, even at 2-bit precision. Additionally, we quantify the interactions between quantization, decoding hyperparameters, and calibration languages, finding that language-matched calibration offers benefits primarily in low-bit scenarios. Our findings offer actionable insights for deploying multilingual LLMs for machine translation under quantization constraints, especially in low-resource settings.
Unsupervised Translation Quality Estimation Exploiting Synthetic Data and Pre-trained Multilingual Encoder
Nov 09, 2023Translation quality estimation (TQE) is the task of predicting translation quality without reference translations. Due to the enormous cost of creating training data for TQE, only a few translation directions can benefit from supervised training. To address this issue, unsupervised TQE methods have been studied. In this paper, we extensively investigate the usefulness of synthetic TQE data and pre-trained multilingual encoders in unsupervised sentence-level TQE, both of which have been proven effective in the supervised training scenarios. Our experiment on WMT20 and WMT21 datasets revealed that this approach can outperform other unsupervised TQE methods on high- and low-resource translation directions in predicting post-editing effort and human evaluation score, and some zero-resource translation directions in predicting post-editing effort.
Bilingual Corpus Mining and Multistage Fine-Tuning for Improving Machine Translation of Lecture Transcripts
Nov 07, 2023



Lecture transcript translation helps learners understand online courses, however, building a high-quality lecture machine translation system lacks publicly available parallel corpora. To address this, we examine a framework for parallel corpus mining, which provides a quick and effective way to mine a parallel corpus from publicly available lectures on Coursera. To create the parallel corpora, we propose a dynamic programming based sentence alignment algorithm which leverages the cosine similarity of machine-translated sentences. The sentence alignment F1 score reaches 96%, which is higher than using the BERTScore, LASER, or sentBERT methods. For both English--Japanese and English--Chinese lecture translations, we extracted parallel corpora of approximately 50,000 lines and created development and test sets through manual filtering for benchmarking translation performance. Through machine translation experiments, we show that the mined corpora enhance the quality of lecture transcript translation when used in conjunction with out-of-domain parallel corpora via multistage fine-tuning. Furthermore, this study also suggests guidelines for gathering and cleaning corpora, mining parallel sentences, cleaning noise in the mined data, and creating high-quality evaluation splits. For the sake of reproducibility, we have released the corpora as well as the code to create them. The dataset is available at https://github.com/shyyhs/CourseraParallelCorpusMining.
Scientific Credibility of Machine Translation Research: A Meta-Evaluation of 769 Papers
Jun 29, 2021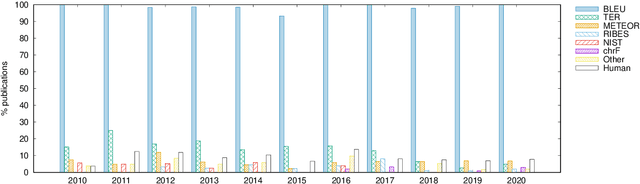

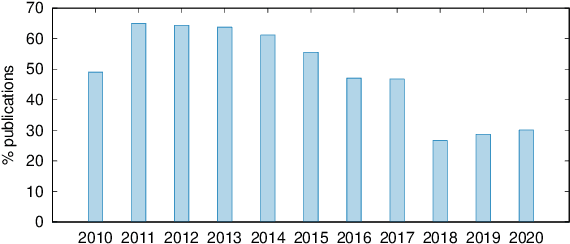
This paper presents the first large-scale meta-evaluation of machine translation (MT). We annotated MT evaluations conducted in 769 research papers published from 2010 to 2020. Our study shows that practices for automatic MT evaluation have dramatically changed during the past decade and follow concerning trends. An increasing number of MT evaluations exclusively rely on differences between BLEU scores to draw conclusions, without performing any kind of statistical significance testing nor human evaluation, while at least 108 metrics claiming to be better than BLEU have been proposed. MT evaluations in recent papers tend to copy and compare automatic metric scores from previous work to claim the superiority of a method or an algorithm without confirming neither exactly the same training, validating, and testing data have been used nor the metric scores are comparable. Furthermore, tools for reporting standardized metric scores are still far from being widely adopted by the MT community. After showing how the accumulation of these pitfalls leads to dubious evaluation, we propose a guideline to encourage better automatic MT evaluation along with a simple meta-evaluation scoring method to assess its credibility.
Recurrent Stacking of Layers in Neural Networks: An Application to Neural Machine Translation
Jun 18, 2021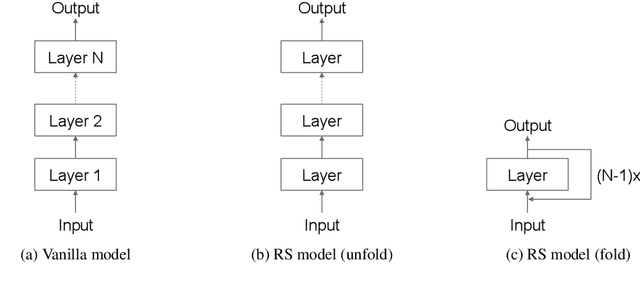
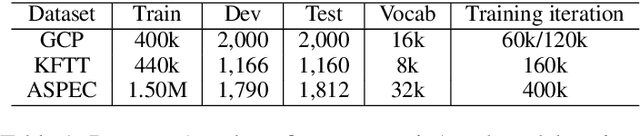
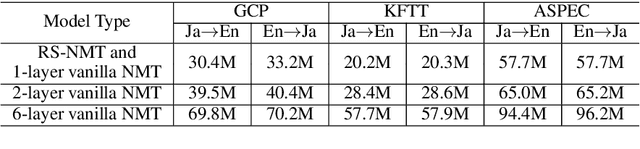
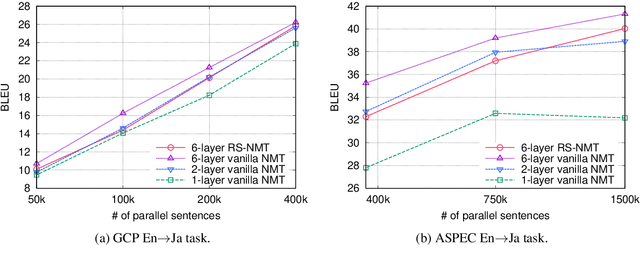
In deep neural network modeling, the most common practice is to stack a number of recurrent, convolutional, or feed-forward layers in order to obtain high-quality continuous space representations which in turn improves the quality of the network's prediction. Conventionally, each layer in the stack has its own parameters which leads to a significant increase in the number of model parameters. In this paper, we propose to share parameters across all layers thereby leading to a recurrently stacked neural network model. We report on an extensive case study on neural machine translation (NMT), where we apply our proposed method to an encoder-decoder based neural network model, i.e., the Transformer model, and experiment with three Japanese--English translation datasets. We empirically demonstrate that the translation quality of a model that recurrently stacks a single layer 6 times, despite having significantly fewer parameters, approaches that of a model that stacks 6 layers where each layer has different parameters. We also explore the limits of recurrent stacking where we train extremely deep NMT models. This paper also examines the utility of our recurrently stacked model as a student model through transfer learning via leveraging pre-trained parameters and knowledge distillation, and shows that it compensates for the performance drops in translation quality that the direct training of recurrently stacked model brings. We also show how transfer learning helps in faster decoding on top of the already reduced number of parameters due to recurrent stacking. Finally, we analyze the effects of recurrently stacked layers by visualizing the attentions of models that use recurrently stacked layers and models that do not.
Understanding Pre-Editing for Black-Box Neural Machine Translation
Feb 05, 2021
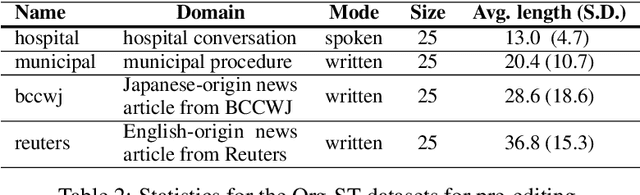
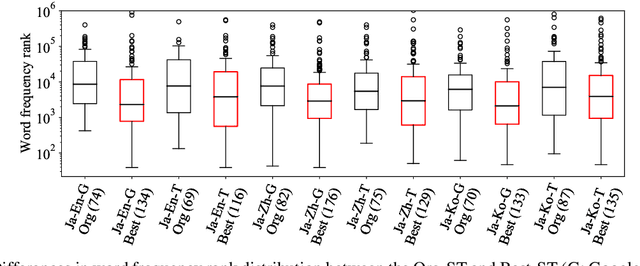
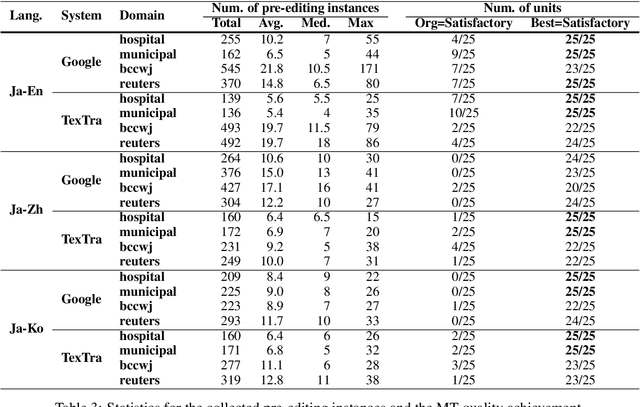
Pre-editing is the process of modifying the source text (ST) so that it can be translated by machine translation (MT) in a better quality. Despite the unpredictability of black-box neural MT (NMT), pre-editing has been deployed in various practical MT use cases. Although many studies have demonstrated the effectiveness of pre-editing methods for particular settings, thus far, a deep understanding of what pre-editing is and how it works for black-box NMT is lacking. To elicit such understanding, we extensively investigated human pre-editing practices. We first implemented a protocol to incrementally record the minimum edits for each ST and collected 6,652 instances of pre-editing across three translation directions, two MT systems, and four text domains. We then analysed the instances from three perspectives: the characteristics of the pre-edited ST, the diversity of pre-editing operations, and the impact of the pre-editing operations on NMT outputs. Our findings include the following: (1) enhancing the explicitness of the meaning of an ST and its syntactic structure is more important for obtaining better translations than making the ST shorter and simpler, and (2) although the impact of pre-editing on NMT is generally unpredictable, there are some tendencies of changes in the NMT outputs depending on the editing operation types.
Synthesizing Monolingual Data for Neural Machine Translation
Jan 29, 2021
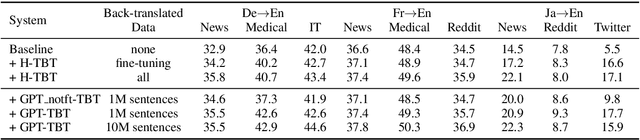
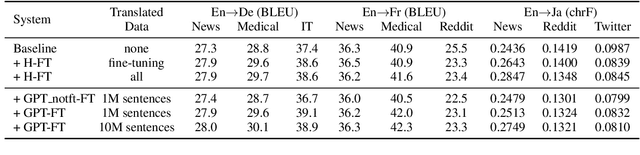
In neural machine translation (NMT), monolingual data in the target language are usually exploited through a method so-called "back-translation" to synthesize additional training parallel data. The synthetic data have been shown helpful to train better NMT, especially for low-resource language pairs and domains. Nonetheless, large monolingual data in the target domains or languages are not always available to generate large synthetic parallel data. In this work, we propose a new method to generate large synthetic parallel data leveraging very small monolingual data in a specific domain. We fine-tune a pre-trained GPT-2 model on such small in-domain monolingual data and use the resulting model to generate a large amount of synthetic in-domain monolingual data. Then, we perform back-translation, or forward translation, to generate synthetic in-domain parallel data. Our preliminary experiments on three language pairs and five domains show the effectiveness of our method to generate fully synthetic but useful in-domain parallel data for improving NMT in all configurations. We also show promising results in extreme adaptation for personalized NMT.
Softmax Tempering for Training Neural Machine Translation Models
Sep 20, 2020

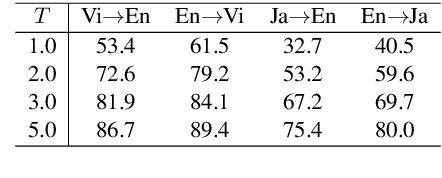
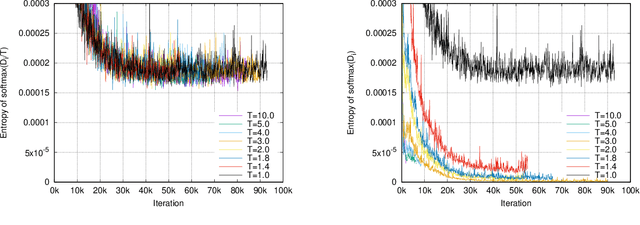
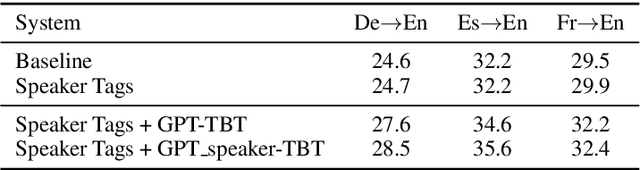
Neural machine translation (NMT) models are typically trained using a softmax cross-entropy loss where the softmax distribution is compared against smoothed gold labels. In low-resource scenarios, NMT models tend to over-fit because the softmax distribution quickly approaches the gold label distribution. To address this issue, we propose to divide the logits by a temperature coefficient, prior to applying softmax, during training. In our experiments on 11 language pairs in the Asian Language Treebank dataset and the WMT 2019 English-to-German translation task, we observed significant improvements in translation quality by up to 3.9 BLEU points. Furthermore, softmax tempering makes the greedy search to be as good as beam search decoding in terms of translation quality, enabling 1.5 to 3.5 times speed-up. We also study the impact of softmax tempering on multilingual NMT and recurrently stacked NMT, both of which aim to reduce the NMT model size by parameter sharing thereby verifying the utility of temperature in developing compact NMT models. Finally, an analysis of softmax entropies and gradients reveal the impact of our method on the internal behavior of NMT models.