 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoScreen-FW: An LLM-based Framework for Resume Screening
Mar 19, 2026Corporate recruiters often need to screen many resumes within a limited time, which increases their burden and may cause suitable candidates to be overlooked. To address these challenges, prior work has explored LLM-based automated resume screening. However, some methods rely on commercial LLMs, which may pose data privacy risks. Moreover, since companies typically do not make resumes with evaluation results publicly available, it remains unclear which resume samples should be used during learning to improve an LLM's judgment performance. To address these problems, we propose AutoScreen-FW, an LLM-based locally and automatically resume screening framework. AutoScreen-FW uses several methods to select a small set of representative resume samples. These samples are used for in-context learning together with a persona description and evaluation criteria, enabling open-source LLMs to act as a career advisor and evaluate unseen resumes. Experiments with multiple ground truths show that the open-source LLM judges consistently outperform GPT-5-nano. Under one ground truth setting, it also surpass GPT-5-mini. Although it is slightly weaker than GPT-5-mini under other ground-truth settings, it runs substantially faster per resume than commercial GPT models. These findings indicate the potential for deploying AutoScreen-FW locally in companies to support efficient screening while reducing recruiters' burden.
A System for Worldwide COVID-19 Information Aggregation
Jul 28, 2020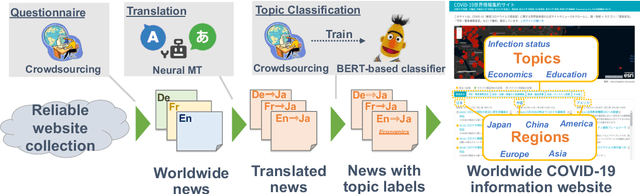

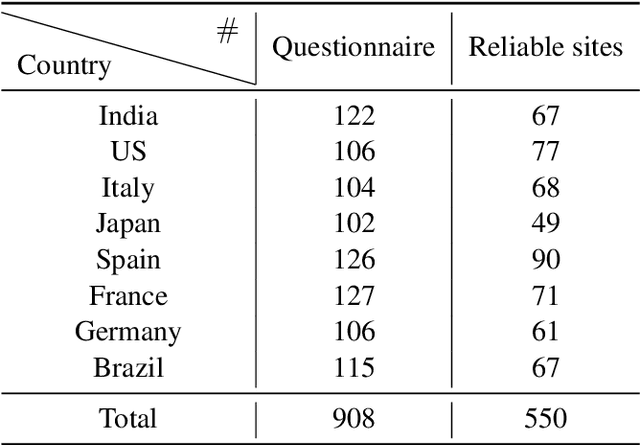
The global pandemic of COVID-19 has made the public pay close attention to related news, covering various domains, such as sanitation, treatment, and effects on education. Meanwhile, the COVID-19 condition is very different among the countries (e.g., policies and development of the epidemic), and thus citizens would be interested in news in foreign countries. We build a system for worldwide COVID-19 information aggregation (http://lotus.kuee.kyoto-u.ac.jp/NLPforCOVID-19 ) containing reliable articles from 10 regions in 7 languages sorted by topics for Japanese citizens. Our reliable COVID-19 related website dataset collected through crowdsourcing ensures the quality of the articles. A neural machine translation module translates articles in other languages into Japanese. A BERT-based topic-classifier trained on an article-topic pair dataset helps users find their interested information efficiently by putting articles into different categories.