 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training via Leveraging Assisting Languages and Data Selection for Neural Machine Translation
Paper and Code
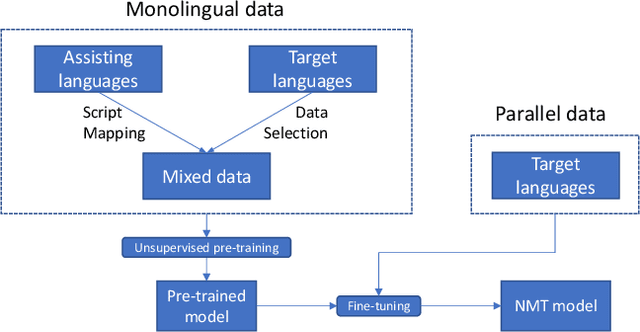
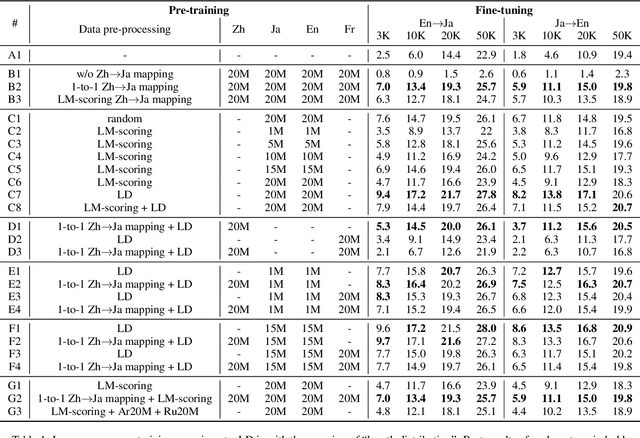
Sequence-to-sequence (S2S) pre-training using large monolingual data is known to improve performance for various S2S NLP tasks in low-resource settings. However, large monolingual corpora might not always be available for the languages of interest (LOI). To this end, we propose to exploit monolingual corpora of other languages to complement the scarcity of monolingual corpora for the LOI. A case study of low-resource Japanese-English neural machine translation (NMT) reveals that leveraging large Chinese and French monolingual corpora can help overcome the shortage of Japanese and English monolingual corpora, respectively, for S2S pre-training. We further show how to utilize script mapping (Chinese to Japanese) to increase the similarity between the two monolingual corpora leading to further improvements in translation quality. Additionally, we propose simple data-selection techniques to be used prior to pre-training that significantly impact the quality of S2S pre-training. An empirical comparison of our proposed methods reveals that leveraging assisting language monolingual corpora, data selection and script mapping are extremely important for NMT pre-training in low-resource scenarios.