 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Upcycling Large Language Models into Mixture of Experts
Oct 10, 2024



Upcycling pre-trained dense language models into sparse mixture-of-experts (MoE) models is an efficient approach to increase the model capacity of already trained models. However, optimal techniques for upcycling at scale remain unclear. In this work, we conduct an extensive study of upcycling methods and hyperparameters for billion-parameter scale language models. We propose a novel "virtual group" initialization scheme and weight scaling approach to enable upcycling into fine-grained MoE architectures. Through ablations, we find that upcycling outperforms continued dense model training. In addition, we show that softmax-then-topK expert routing improves over topK-then-softmax approach and higher granularity MoEs can help improve accuracy. Finally, we upcycled Nemotron-4 15B on 1T tokens and compared it to a continuously trained version of the same model on the same 1T tokens: the continuous trained model achieved 65.3% MMLU, whereas the upcycled model achieved 67.6%. Our results offer insights and best practices to effectively leverage upcycling for building MoE language models.
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models
Jun 27, 2023



Large language models (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean. However, existing methods are difficult to reproduce or build on, due to private code, data, and large compute requirements. This has created substantial barriers to research on machine learning methods for theorem proving. This paper removes these barriers by introducing LeanDojo: an open-source Lean playground consisting of toolkits, data, models, and benchmarks. LeanDojo extracts data from Lean and enables interaction with the proof environment programmatically. It contains fine-grained annotations of premises in proofs, providing valuable data for premise selection: a key bottleneck in theorem proving. Using this data, we develop ReProver (Retrieval-Augmented Prover): the first LLM-based prover that is augmented with retrieval for selecting premises from a vast math library. It is inexpensive and needs only one GPU week of training. Our retriever leverages LeanDojo's program analysis capability to identify accessible premises and hard negative examples, which makes retrieval much more effective. Furthermore, we construct a new benchmark consisting of 96,962 theorems and proofs extracted from Lean's math library. It features challenging data split requiring the prover to generalize to theorems relying on novel premises that are never used in training. We use this benchmark for training and evaluation, and experimental results demonstrate the effectiveness of ReProver over non-retrieval baselines and GPT-4. We thus provide the first set of open-source LLM-based theorem provers without any proprietary datasets and release it under a permissive MIT license to facilitate further research.
Context Generation Improves Open Domain Question Answering
Oct 12, 2022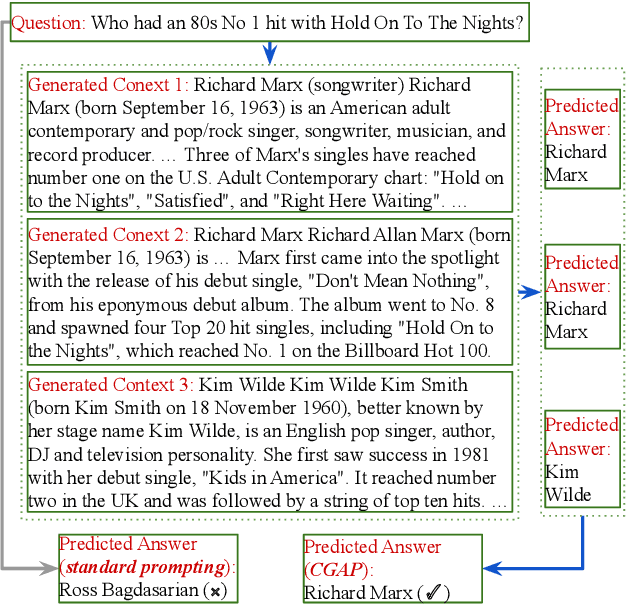

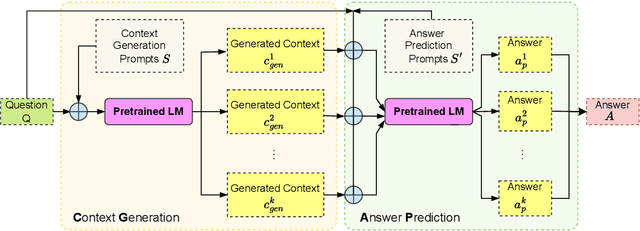
Closed-book question answering (QA) requires a model to directly answer an open-domain question without access to any external knowledge. Prior work on closed-book QA either directly finetunes or prompts a pretrained language model (LM) to leverage the stored knowledge. However, they do not fully exploit the parameterized knowledge. To address this issue, we propose a two-stage, closed-book QA framework which employs a coarse-to-fine approach to extract relevant knowledge and answer a question. Our approach first generates a related context for a given question by prompting a pretrained LM. We then prompt the same LM for answer prediction using the generated context and the question. Additionally, to eliminate failure caused by context uncertainty, we marginalize over generated contexts. Experimental results on three QA benchmarks show that our method significantly outperforms previous closed-book QA methods (e.g. exact matching 68.6% vs. 55.3%), and is on par with open-book methods that exploit external knowledge sources (e.g. 68.6% vs. 68.0%). Our method is able to better exploit the stored knowledge in pretrained LMs without adding extra learnable parameters or needing finetuning, and paves the way for hybrid models that integrate pretrained LMs with external knowledge.
Multi-Stage Prompting for Knowledgeable Dialogue Generation
Mar 16, 2022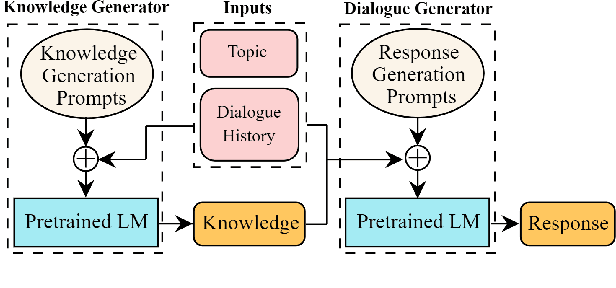
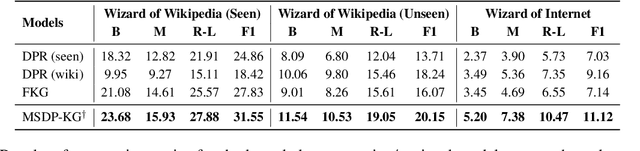
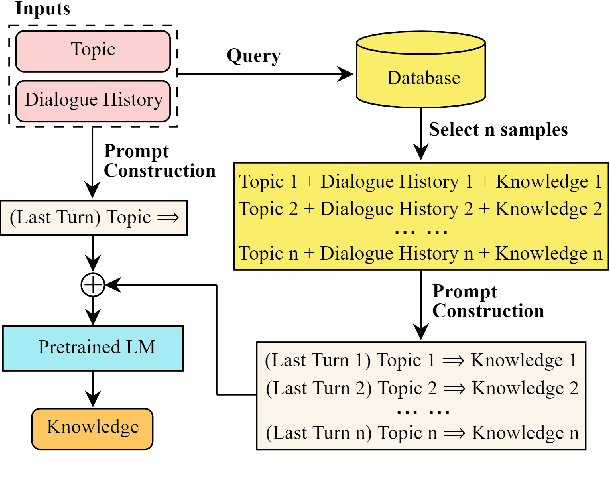

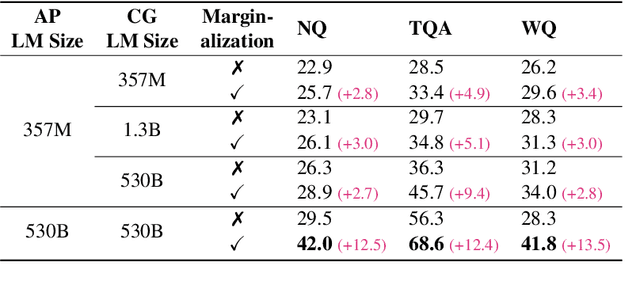
Existing knowledge-grounded dialogue systems typically use finetuned versions of a pretrained language model (LM) and large-scale knowledge bases. These models typically fail to generalize on topics outside of the knowledge base, and require maintaining separate potentially large checkpoints each time finetuning is needed. In this paper, we aim to address these limitations by leveraging the inherent knowledge stored in the pretrained LM as well as its powerful generation ability. We propose a multi-stage prompting approach to generate knowledgeable responses from a single pretrained LM. We first prompt the LM to generate knowledge based on the dialogue context. Then, we further prompt it to generate responses based on the dialogue context and the previously generated knowledge. Results show that our knowledge generator outperforms the state-of-the-art retrieval-based model by 5.8% when combining knowledge relevance and correctness. In addition, our multi-stage prompting outperforms the finetuning-based dialogue model in terms of response knowledgeability and engagement by up to 10% and 5%, respectively. Furthermore, we scale our model up to 530 billion parameters and show that larger LMs improve the generation correctness score by up to 10%, and response relevance, knowledgeability and engagement by up to 10%. Our code is available at: https://github.com/NVIDIA/Megatron-LM.
Flowtron: an Autoregressive Flow-based Generative Network for Text-to-Speech Synthesis
May 13, 2020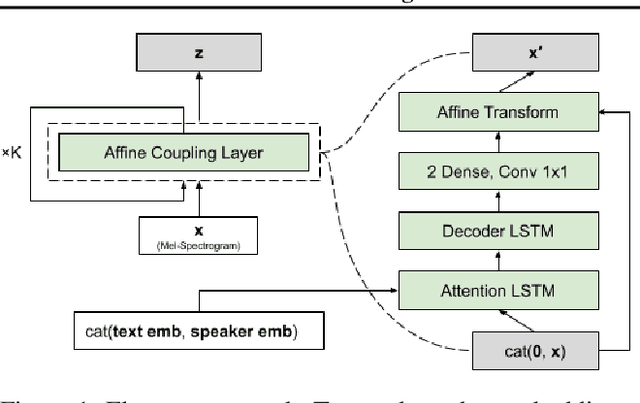
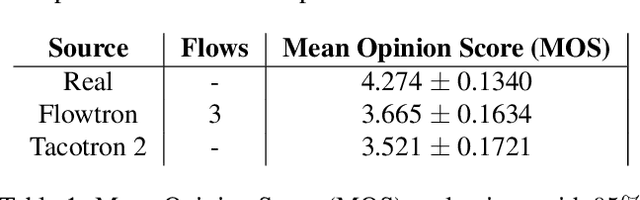
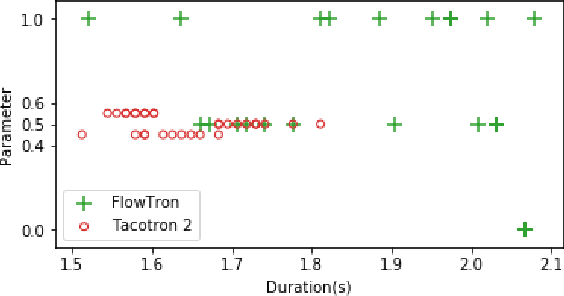
In this paper we propose Flowtron: an autoregressive flow-based generative network for text-to-speech synthesis with control over speech variation and style transfer. Flowtron borrows insights from IAF and revamps Tacotron in order to provide high-quality and expressive mel-spectrogram synthesis. Flowtron is optimized by maximizing the likelihood of the training data, which makes training simple and stable. Flowtron learns an invertible mapping of data to a latent space that can be manipulated to control many aspects of speech synthesis (pitch, tone, speech rate, cadence, accent). Our mean opinion scores (MOS) show that Flowtron matches state-of-the-art TTS models in terms of speech quality. In addition, we provide results on control of speech variation, interpolation between samples and style transfer between speakers seen and unseen during training. Code and pre-trained models will be made publicly available at https://github.com/NVIDIA/flowtron
Mellotron: Multispeaker expressive voice synthesis by conditioning on rhythm, pitch and global style tokens
Oct 26, 2019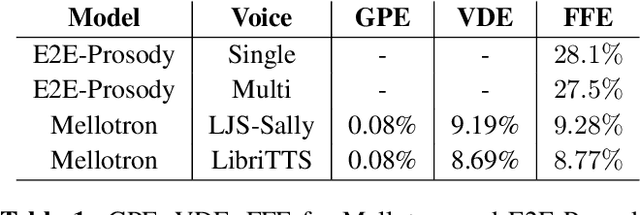

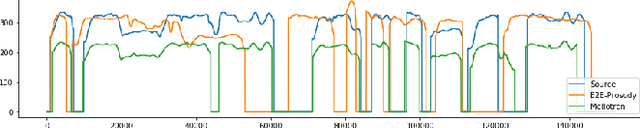
Mellotron is a multispeaker voice synthesis model based on Tacotron 2 GST that can make a voice emote and sing without emotive or singing training data. By explicitly conditioning on rhythm and continuous pitch contours from an audio signal or music score, Mellotron is able to generate speech in a variety of styles ranging from read speech to expressive speech, from slow drawls to rap and from monotonous voice to singing voice. Unlike other methods, we train Mellotron using only read speech data without alignments between text and audio. We evaluate our models using the LJSpeech and LibriTTS datasets. We provide F0 Frame Errors and synthesized samples that include style transfer from other speakers, singers and styles not seen during training, procedural manipulation of rhythm and pitch and choir synthesis.
WaveGlow: A Flow-based Generative Network for Speech Synthesis
Oct 31, 2018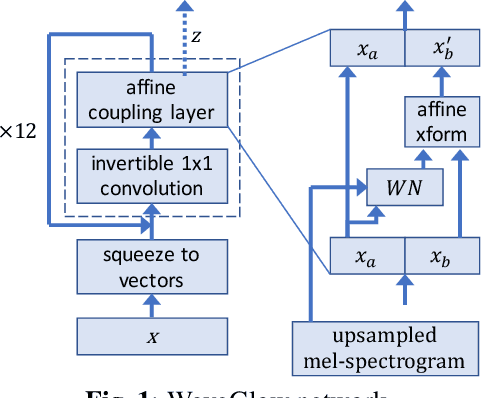
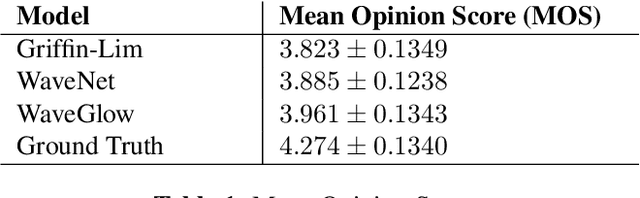
In this paper we propose WaveGlow: a flow-based network capable of generating high quality speech from mel-spectrograms. WaveGlow combines insights from Glow and WaveNet in order to provide fast, efficient and high-quality audio synthesis, without the need for auto-regression. WaveGlow is implemented using only a single network, trained using only a single cost function: maximizing the likelihood of the training data, which makes the training procedure simple and stable. Our PyTorch implementation produces audio samples at a rate of more than 500 kHz on an NVIDIA V100 GPU. Mean Opinion Scores show that it delivers audio quality as good as the best publicly available WaveNet implementation. All code will be made publicly available online.