 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Clinical Named Entity Recognition using Contextualized Token Representations
Jun 23, 2021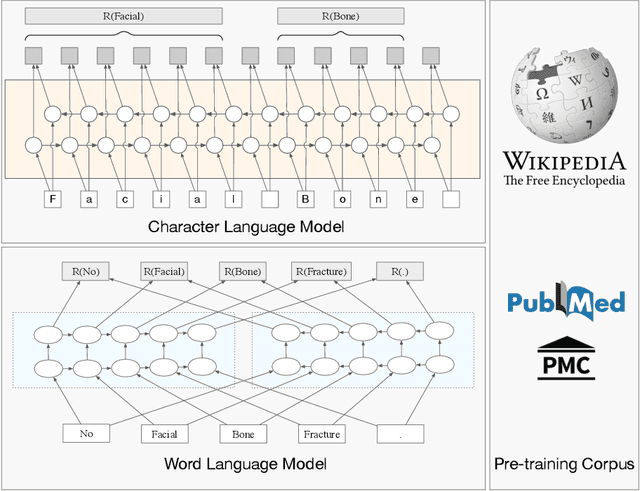
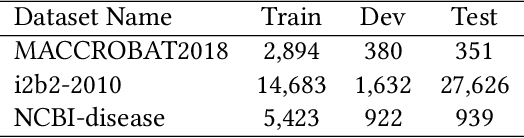
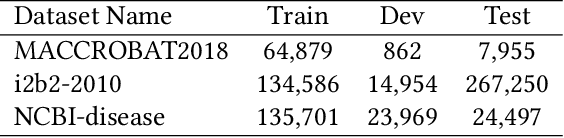

The clinical named entity recognition (CNER) task seeks to locate and classify clinical terminologies into predefined categories, such as diagnostic procedure, disease disorder, severity, medication, medication dosage, and sign symptom. CNER facilitates the study of side-effect on medications including identification of novel phenomena and human-focused information extraction. Existing approaches in extracting the entities of interests focus on using static word embeddings to represent each word. However, one word can have different interpretations that depend on the context of the sentences. Evidently, static word embeddings are insufficient to integrate the diverse interpretation of a word. To overcome this challenge, the technique of contextualized word embedding has been introduced to better capture the semantic meaning of each word based on its context. Two of these language models, ELMo and Flair, have been widely used in the field of Natural Language Processing to generate the contextualized word embeddings on domain-generic documents. However, these embeddings are usually too general to capture the proximity among vocabularies of specific domains. To facilitate various downstream applications using clinical case reports (CCRs), we pre-train two deep contextualized language models, Clinical Embeddings from Language Model (C-ELMo) and Clinical Contextual String Embeddings (C-Flair) using the clinical-related corpus from the PubMed Central. Explicit experiments show that our models gain dramatic improvements compared to both static word embeddings and domain-generic language models.
Flowtron: an Autoregressive Flow-based Generative Network for Text-to-Speech Synthesis
May 13, 2020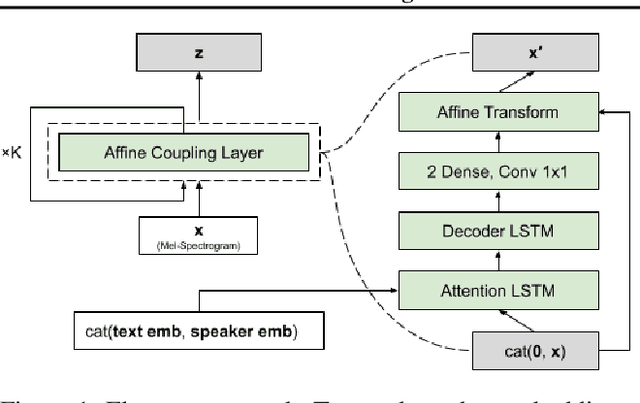
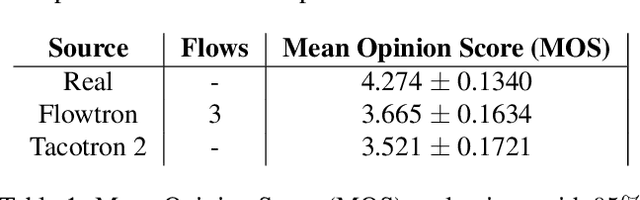
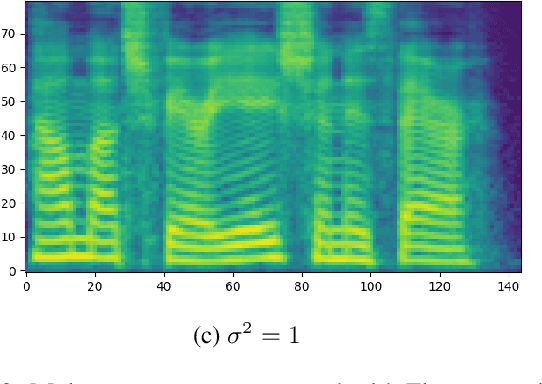
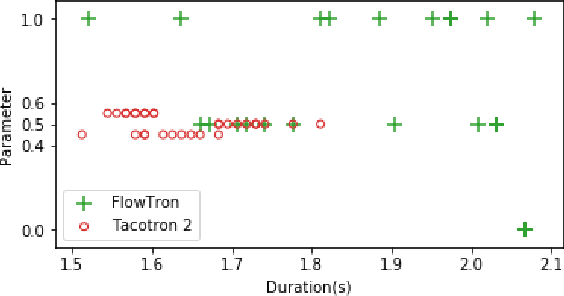
In this paper we propose Flowtron: an autoregressive flow-based generative network for text-to-speech synthesis with control over speech variation and style transfer. Flowtron borrows insights from IAF and revamps Tacotron in order to provide high-quality and expressive mel-spectrogram synthesis. Flowtron is optimized by maximizing the likelihood of the training data, which makes training simple and stable. Flowtron learns an invertible mapping of data to a latent space that can be manipulated to control many aspects of speech synthesis (pitch, tone, speech rate, cadence, accent). Our mean opinion scores (MOS) show that Flowtron matches state-of-the-art TTS models in terms of speech quality. In addition, we provide results on control of speech variation, interpolation between samples and style transfer between speakers seen and unseen during training. Code and pre-trained models will be made publicly available at https://github.com/NVIDIA/flowtron
An Interpretable Model for Scene Graph Generation
Nov 21, 2018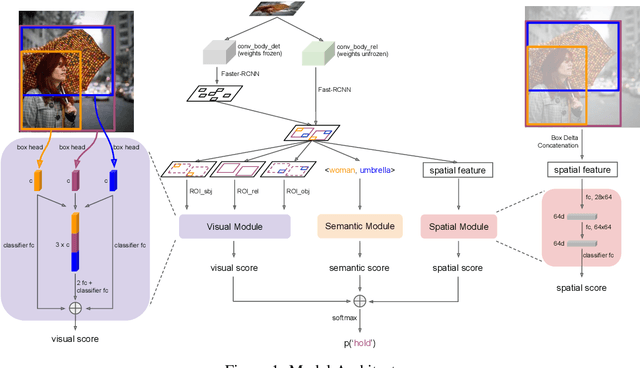
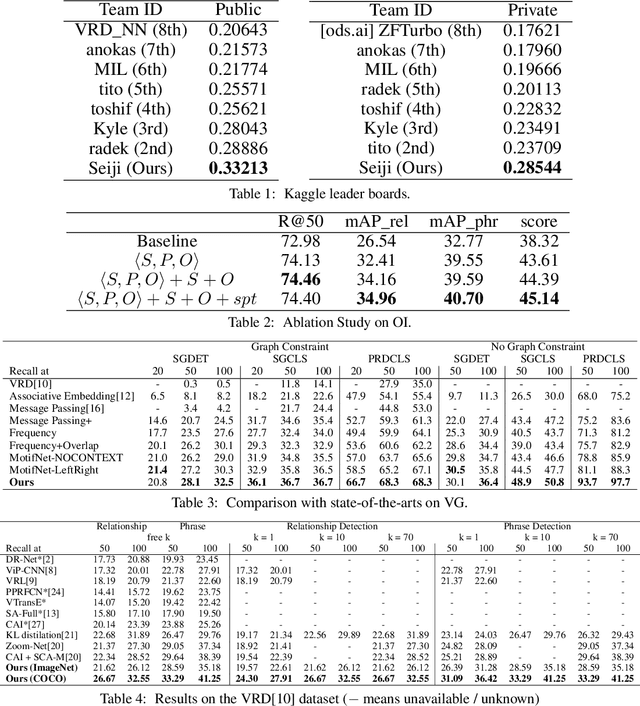
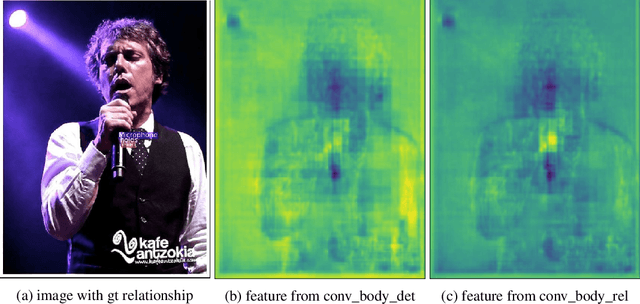

We propose an efficient and interpretable scene graph generator. We consider three types of features: visual, spatial and semantic, and we use a late fusion strategy such that each feature's contribution can be explicitly investigated. We study the key factors about these features that have the most impact on the performance, and also visualize the learned visual features for relationships and investigate the efficacy of our model. We won the champion of the OpenImages Visual Relationship Detection Challenge on Kaggle, where we outperform the 2nd place by 5\% (20\% relatively). We believe an accurate scene graph generator is a fundamental stepping stone for higher-level vision-language tasks such as image captioning and visual QA, since it provides a semantic, structured comprehension of an image that is beyond pixels and objects.
Introduction to the 1st Place Winning Model of OpenImages Relationship Detection Challenge
Nov 01, 2018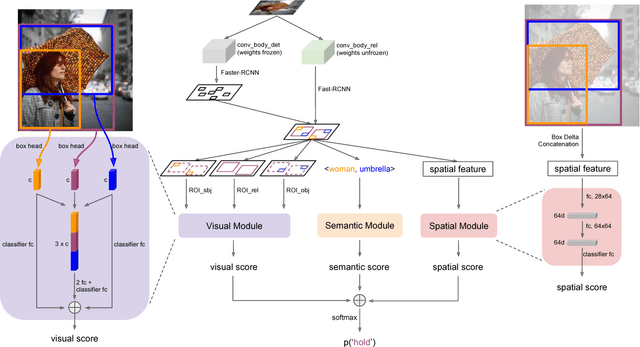

This article describes the model we built that achieved 1st place in the OpenImage Visual Relationship Detection Challenge on Kaggle. Three key factors contribute the most to our success: 1) language bias is a powerful baseline for this task. We build the empirical distribution $P(predicate|subject,object)$ in the training set and directly use that in testing. This baseline achieved the 2nd place when submitted; 2) spatial features are as important as visual features, especially for spatial relationships such as "under" and "inside of"; 3) It is a very effective way to fuse different features by first building separate modules for each of them, then adding their output logits before the final softmax layer. We show in ablation study that each factor can improve the performance to a non-trivial extent, and the model reaches optimal when all of them are combined.
Aligned Image-Word Representations Improve Inductive Transfer Across Vision-Language Tasks
Oct 16, 2017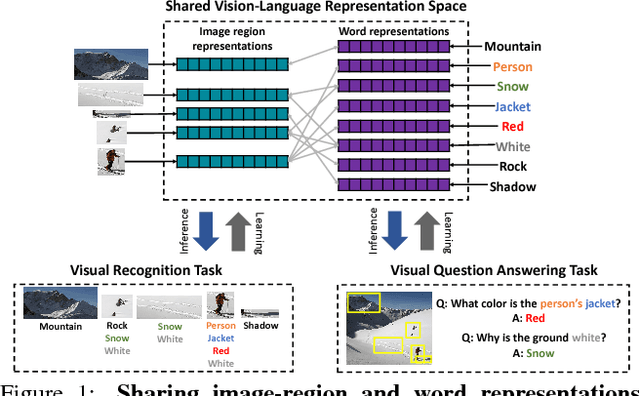
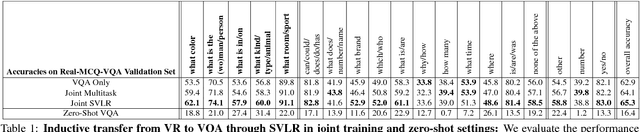
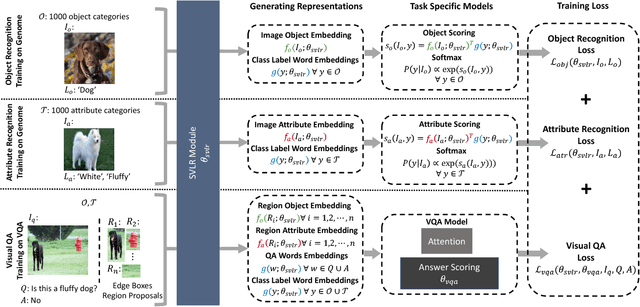
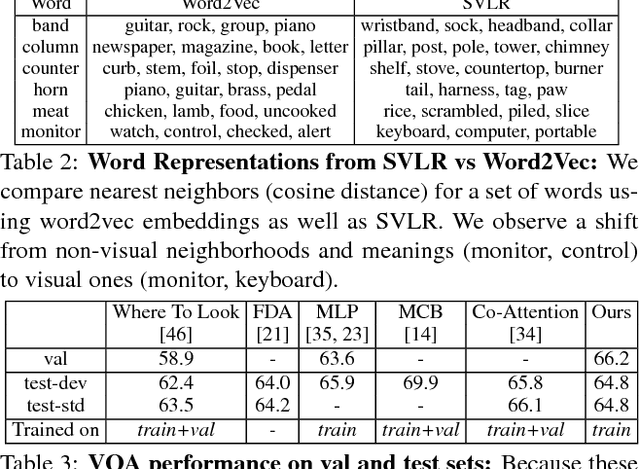
An important goal of computer vision is to build systems that learn visual representations over time that can be applied to many tasks. In this paper, we investigate a vision-language embedding as a core representation and show that it leads to better cross-task transfer than standard multi-task learning. In particular, the task of visual recognition is aligned to the task of visual question answering by forcing each to use the same word-region embeddings. We show this leads to greater inductive transfer from recognition to VQA than standard multitask learning. Visual recognition also improves, especially for categories that have relatively few recognition training labels but appear often in the VQA setting. Thus, our paper takes a small step towards creating more general vision systems by showing the benefit of interpretable, flexible, and trainable core representations.
Efficient Media Retrieval from Non-Cooperative Queries
Nov 19, 2014


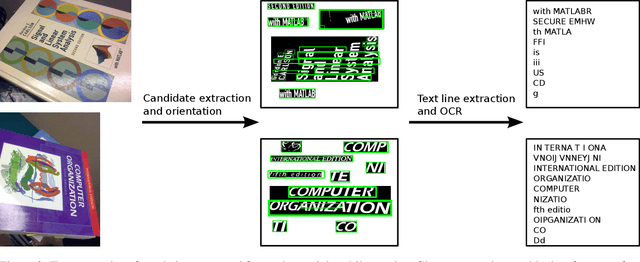
Text is ubiquitous in the artificial world and easily attainable when it comes to book title and author names. Using the images from the book cover set from the Stanford Mobile Visual Search dataset and additional book covers and metadata from openlibrary.org, we construct a large scale book cover retrieval dataset, complete with 100K distractor covers and title and author strings for each. Because our query images are poorly conditioned for clean text extraction, we propose a method for extracting a matching noisy and erroneous OCR readings and matching it against clean author and book title strings in a standard document look-up problem setup. Finally, we demonstrate how to use this text-matching as a feature in conjunction with popular retrieval features such as VLAD using a simple learning setup to achieve significant improvements in retrieval accuracy over that of either VLAD or the text alone.