 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
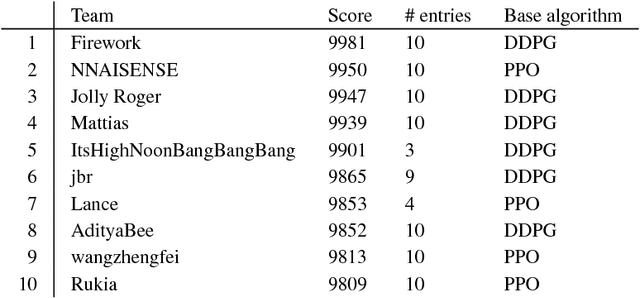

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
ContextVP: Fully Context-Aware Video Prediction
Sep 09, 2018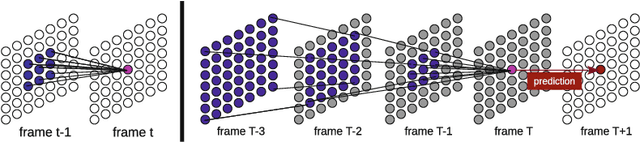
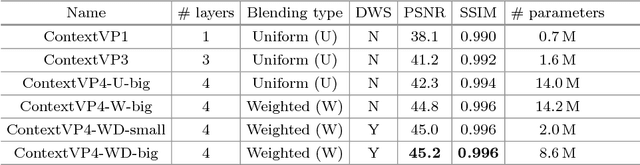
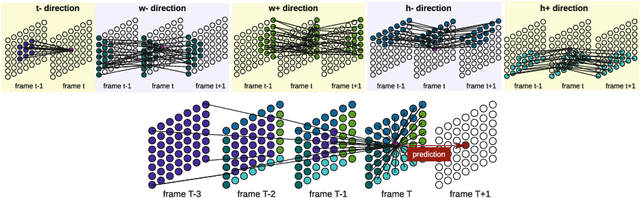
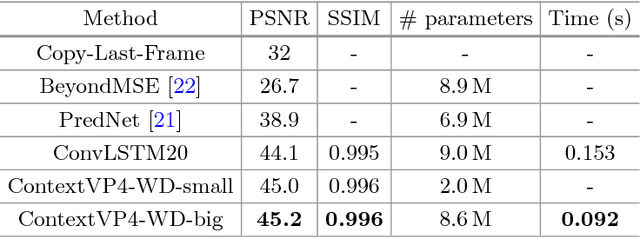
Video prediction models based on convolutional networks, recurrent networks, and their combinations often result in blurry predictions. We identify an important contributing factor for imprecise predictions that has not been studied adequately in the literature: blind spots, i.e., lack of access to all relevant past information for accurately predicting the future. To address this issue, we introduce a fully context-aware architecture that captures the entire available past context for each pixel using Parallel Multi-Dimensional LSTM units and aggregates it using blending units. Our model outperforms a strong baseline network of 20 recurrent convolutional layers and yields state-of-the-art performance for next step prediction on three challenging real-world video datasets: Human 3.6M, Caltech Pedestrian, and UCF-101. Moreover, it does so with fewer parameters than several recently proposed models, and does not rely on deep convolutional networks, multi-scale architectures, separation of background and foreground modeling, motion flow learning, or adversarial training. These results highlight that full awareness of past context is of crucial importance for video prediction.
LSTM: A Search Space Odyssey
Oct 04, 2017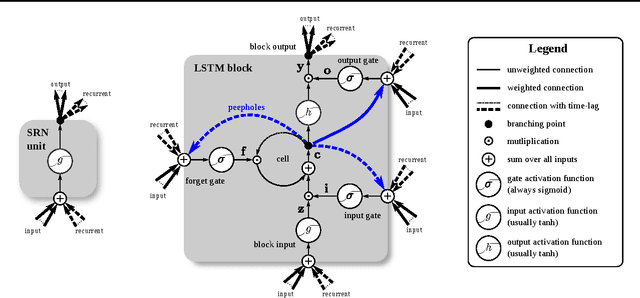
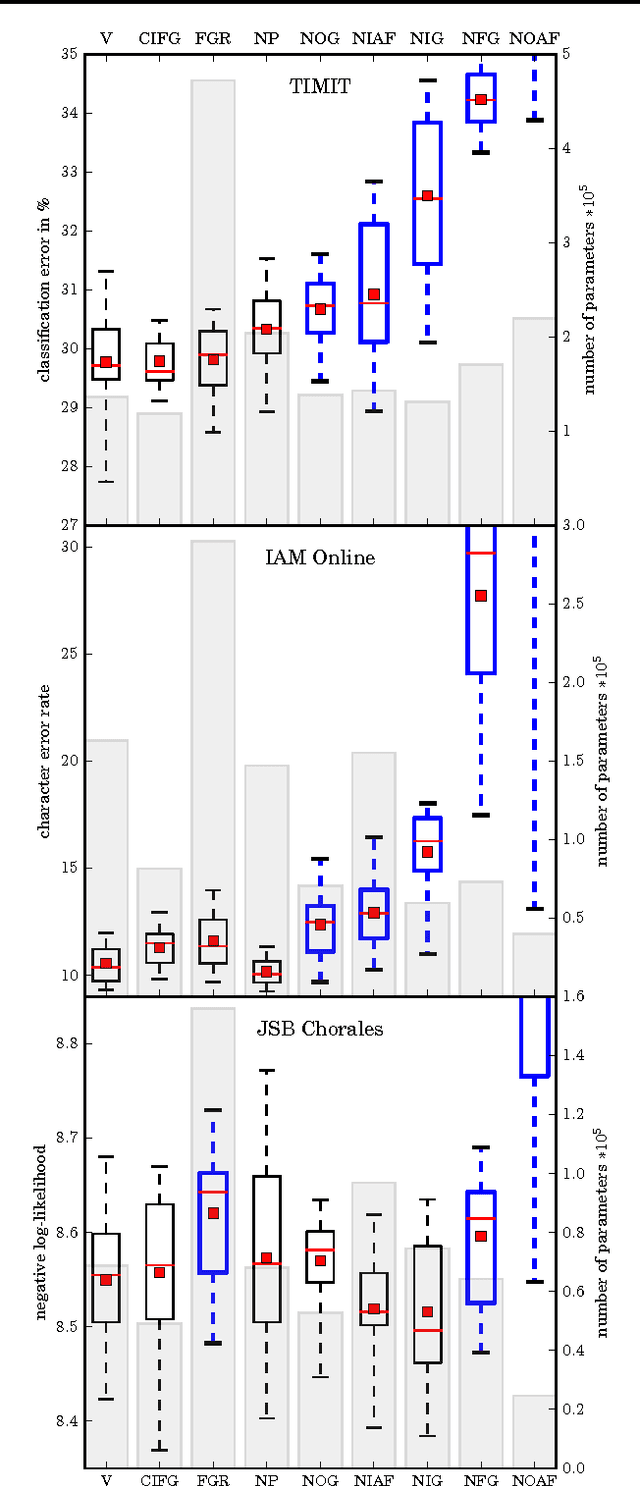
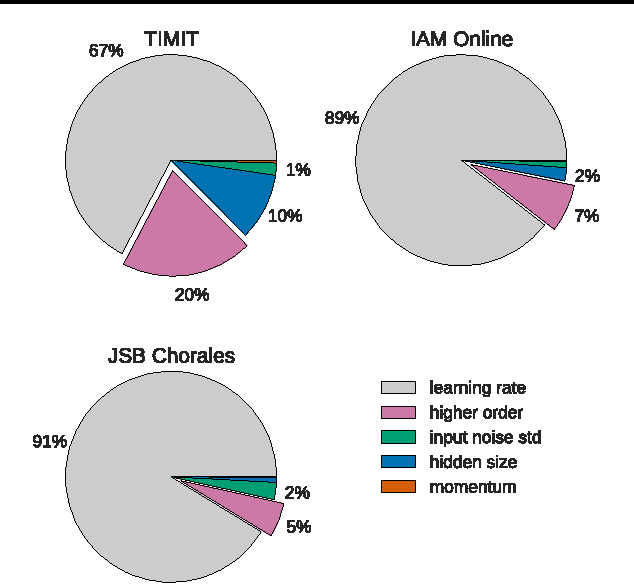
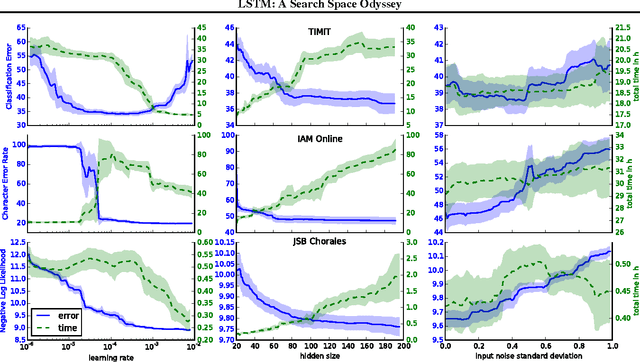
Several variants of the Long Short-Term Memory (LSTM) architecture for recurrent neural networks have been proposed since its inception in 1995. In recent years, these networks have become the state-of-the-art models for a variety of machine learning problems. This has led to a renewed interest in understanding the role and utility of various computational components of typical LSTM variants. In this paper, we present the first large-scale analysis of eight LSTM variants on three representative tasks: speech recognition, handwriting recognition, and polyphonic music modeling. The hyperparameters of all LSTM variants for each task were optimized separately using random search, and their importance was assessed using the powerful fANOVA framework. In total, we summarize the results of 5400 experimental runs ($\approx 15$ years of CPU time), which makes our study the largest of its kind on LSTM networks. Our results show that none of the variants can improve upon the standard LSTM architecture significantly, and demonstrate the forget gate and the output activation function to be its most critical components. We further observe that the studied hyperparameters are virtually independent and derive guidelines for their efficient adjustment.
* 12 pages, 6 figures
Recurrent Highway Networks
Jul 04, 2017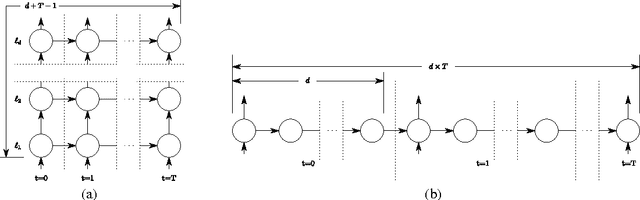
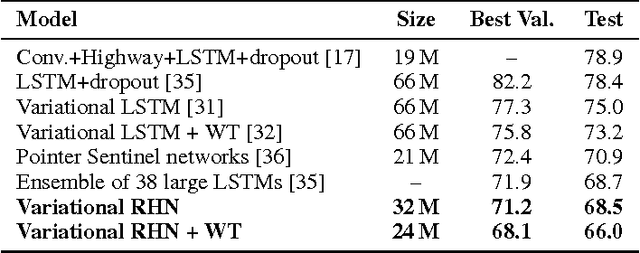
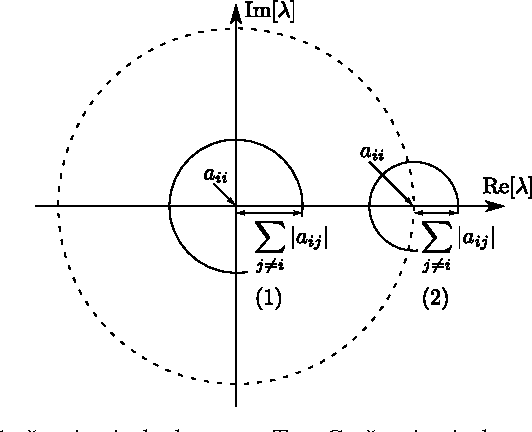
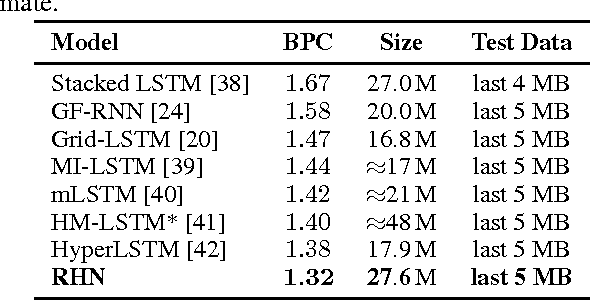
Many sequential processing tasks require complex nonlinear transition functions from one step to the next. However, recurrent neural networks with 'deep' transition functions remain difficult to train, even when using Long Short-Term Memory (LSTM) networks. We introduce a novel theoretical analysis of recurrent networks based on Gersgorin's circle theorem that illuminates several modeling and optimization issues and improves our understanding of the LSTM cell. Based on this analysis we propose Recurrent Highway Networks, which extend the LSTM architecture to allow step-to-step transition depths larger than one. Several language modeling experiments demonstrate that the proposed architecture results in powerful and efficient models. On the Penn Treebank corpus, solely increasing the transition depth from 1 to 10 improves word-level perplexity from 90.6 to 65.4 using the same number of parameters. On the larger Wikipedia datasets for character prediction (text8 and enwik8), RHNs outperform all previous results and achieve an entropy of 1.27 bits per character.
Binding via Reconstruction Clustering
Jan 20, 2016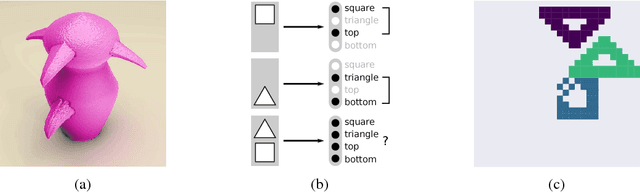

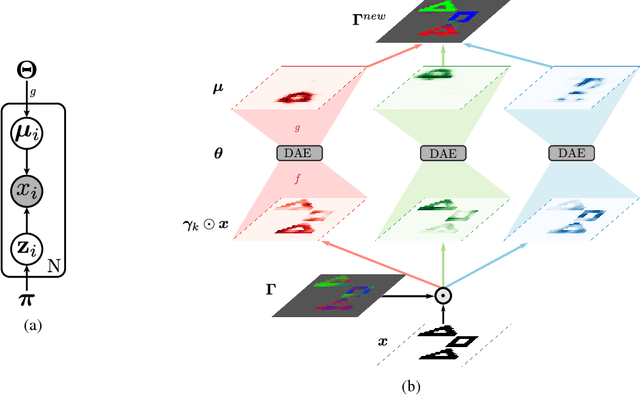

Disentangled distributed representations of data are desirable for machine learning, since they are more expressive and can generalize from fewer examples. However, for complex data, the distributed representations of multiple objects present in the same input can interfere and lead to ambiguities, which is commonly referred to as the binding problem. We argue for the importance of the binding problem to the field of representation learning, and develop a probabilistic framework that explicitly models inputs as a composition of multiple objects. We propose an unsupervised algorithm that uses denoising autoencoders to dynamically bind features together in multi-object inputs through an Expectation-Maximization-like clustering process. The effectiveness of this method is demonstrated on artificially generated datasets of binary images, showing that it can even generalize to bind together new objects never seen by the autoencoder during training.
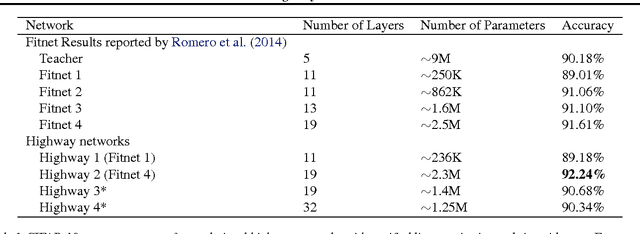
Training Very Deep Networks
Nov 23, 2015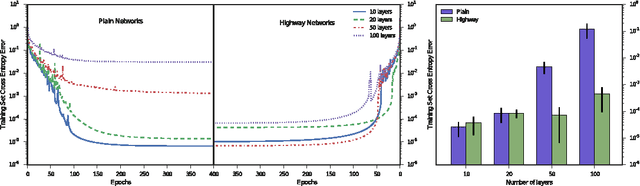


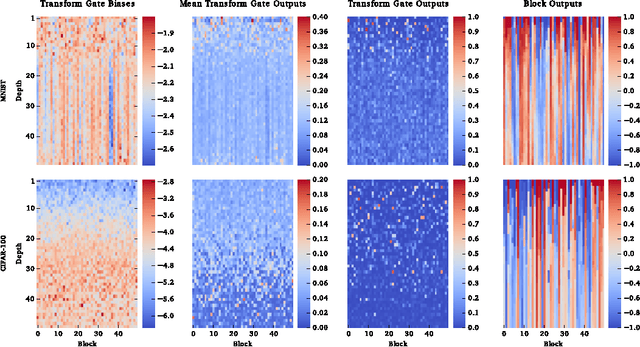
Theoretical and empirical evidence indicates that the depth of neural networks is crucial for their success. However, training becomes more difficult as depth increases, and training of very deep networks remains an open problem. Here we introduce a new architecture designed to overcome this. Our so-called highway networks allow unimpeded information flow across many layers on information highways. They are inspired by Long Short-Term Memory recurrent networks and use adaptive gating units to regulate the information flow. Even with hundreds of layers, highway networks can be trained directly through simple gradient descent. This enables the study of extremely deep and efficient architectures.
Highway Networks
Nov 03, 2015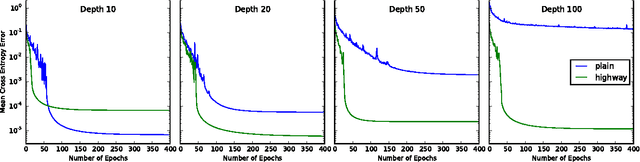
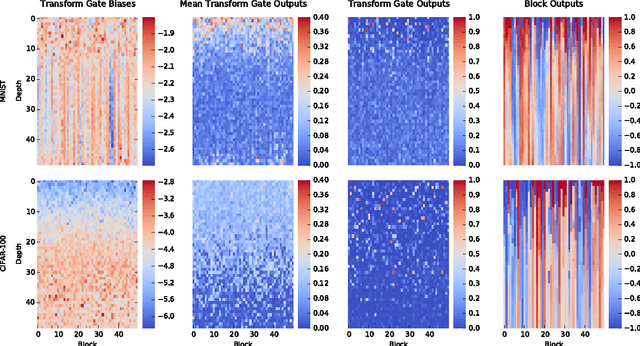
There is plenty of theoretical and empirical evidence that depth of neural networks is a crucial ingredient for their success. However, network training becomes more difficult with increasing depth and training of very deep networks remains an open problem. In this extended abstract, we introduce a new architecture designed to ease gradient-based training of very deep networks. We refer to networks with this architecture as highway networks, since they allow unimpeded information flow across several layers on "information highways". The architecture is characterized by the use of gating units which learn to regulate the flow of information through a network. Highway networks with hundreds of layers can be trained directly using stochastic gradient descent and with a variety of activation functions, opening up the possibility of studying extremely deep and efficient architectures.
Understanding Locally Competitive Networks
Apr 09, 2015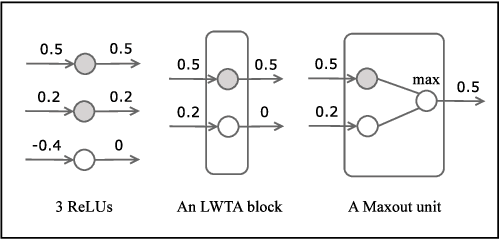
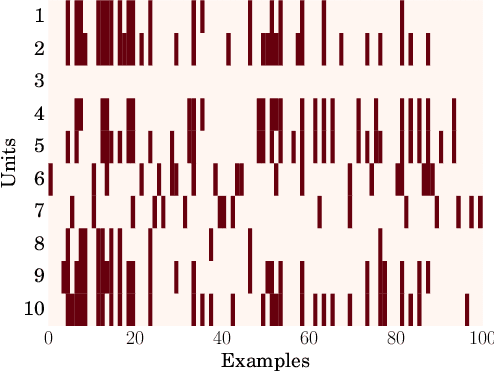


Recently proposed neural network activation functions such as rectified linear, maxout, and local winner-take-all have allowed for faster and more effective training of deep neural architectures on large and complex datasets. The common trait among these functions is that they implement local competition between small groups of computational units within a layer, so that only part of the network is activated for any given input pattern. In this paper, we attempt to visualize and understand this self-modularization, and suggest a unified explanation for the beneficial properties of such networks. We also show how our insights can be directly useful for efficiently performing retrieval over large datasets using neural networks.
First Experiments with PowerPlay
Oct 31, 2012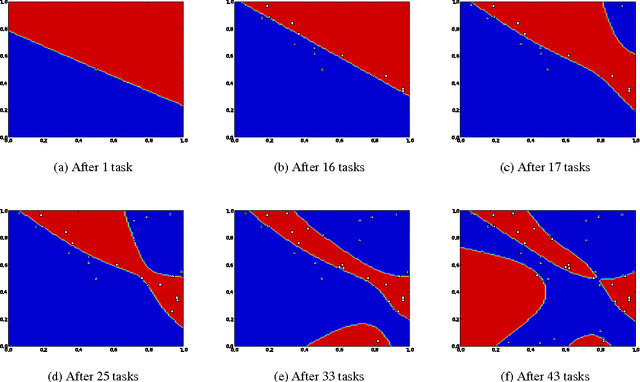
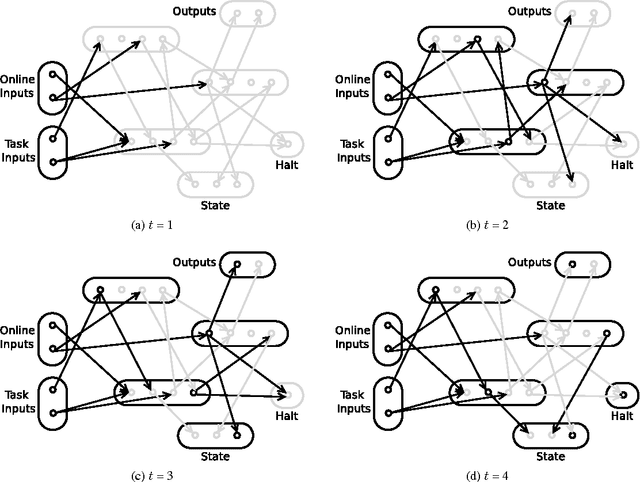
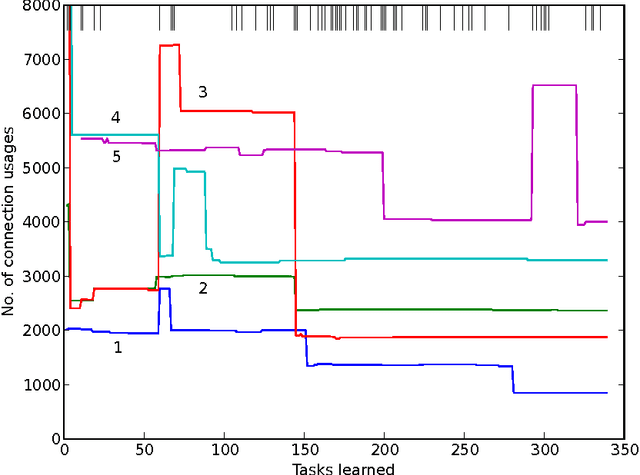
Like a scientist or a playing child, PowerPlay not only learns new skills to solve given problems, but also invents new interesting problems by itself. By design, it continually comes up with the fastest to find, initially novel, but eventually solvable tasks. It also continually simplifies or compresses or speeds up solutions to previous tasks. Here we describe first experiments with PowerPlay. A self-delimiting recurrent neural network SLIM RNN is used as a general computational problem solving architecture. Its connection weights can encode arbitrary, self-delimiting, halting or non-halting programs affecting both environment (through effectors) and internal states encoding abstractions of event sequences. Our PowerPlay-driven SLIM RNN learns to become an increasingly general solver of self-invented problems, continually adding new problem solving procedures to its growing skill repertoire. Extending a recent conference paper, we identify interesting, emerging, developmental stages of our open-ended system. We also show how it automatically self-modularizes, frequently re-using code for previously invented skills, always trying to invent novel tasks that can be quickly validated because they do not require too many weight changes affecting too many previous tasks.